
Créer un Serveur MCP en TypeScript en 30 min — Tutoriel Complet 2026
Le Model Context Protocol (MCP) permet aux agents IA d'accéder à vos données. Ce tutoriel pas à pas vous guide de l'installation à la connexion Cursor en 30 minutes chrono.

Mis à jour le

Comment Créer un Serveur MCP en TypeScript en 30 Minutes
Le Model Context Protocol (MCP) est le standard émergent qui permet aux agents IA (Claude, Cursor, GPT-5) d'accéder à vos données et systèmes propriétaires de manière sécurisée et structurée. Si vous avez déjà voulu que votre agent IA puisse consulter votre CRM, votre base de données ou votre documentation interne — c'est exactement ce que MCP rend possible. Dans ce tutoriel, vous allez apprendre à créer un serveur MCP en TypeScript complet, de l'installation du SDK officiel jusqu'à la connexion à un client réel comme Cursor.
L'objectif est volontairement concret : à la fin, vous disposerez d'un serveur fonctionnel exposant des outils (tools), des ressources (resources) et des prompts, testable avec l'inspecteur officiel, et prêt à être sécurisé pour la production. Comptez environ 30 minutes pour la version de base, un peu plus si vous explorez les sections avancées.
Qu'est-ce que le Model Context Protocol (MCP) et pourquoi l'utiliser ?
MCP est un protocole ouvert, standardisé, qui décrit comment un modèle de langage accède à des outils et à des données externes. Avant MCP, chaque intégration entre un agent IA et un système (CRM, base SQL, API maison) était un développement sur-mesure, non réutilisable d'un agent à l'autre. MCP résout ce problème en imposant un contrat commun : un client (l'hôte qui héberge le LLM) sait toujours interroger un serveur de la même façon, quel que soit l'éditeur.
L'analogie la plus parlante est celle du port USB-C : au lieu d'un câble propriétaire par appareil, un connecteur universel. MCP joue ce rôle pour les agents IA. Vous écrivez votre logique une seule fois côté serveur, et tous les clients compatibles (Cursor, Claude Desktop, n8n, et d'autres) peuvent s'y brancher sans réécriture.
Comment est structuré un serveur MCP : client, serveur et transport ?
L'architecture MCP repose sur trois rôles bien séparés. Le client (aussi appelé hôte) est l'application qui contient le LLM et orchestre la conversation. Le serveur expose des capacités : outils, ressources, prompts. Le transport est le canal de communication entre les deux, utilisant le format de messages JSON-RPC 2.0.
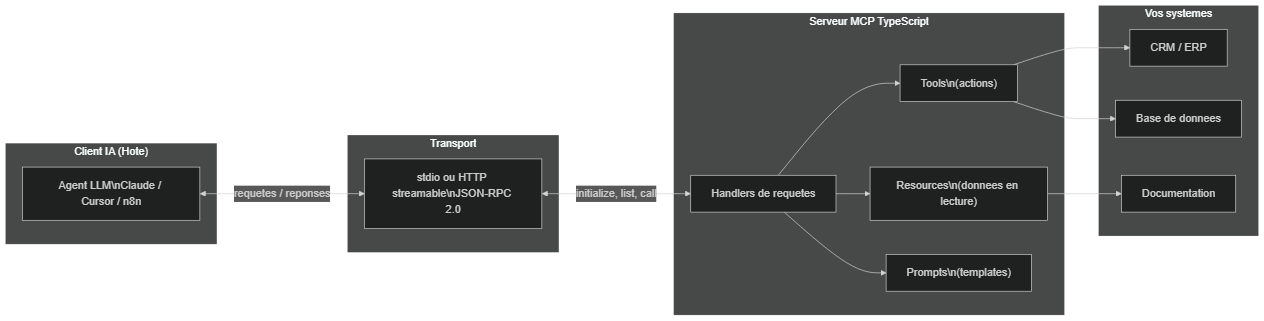 Le client IA dialogue avec le serveur MCP via un transport (stdio ou HTTP). Le serveur expose des outils, des ressources et des prompts connectés à vos systèmes.
Le client IA dialogue avec le serveur MCP via un transport (stdio ou HTTP). Le serveur expose des outils, des ressources et des prompts connectés à vos systèmes.
Cette séparation est la clé de la portabilité. Votre serveur ne sait pas — et n'a pas besoin de savoir — quel modèle l'interroge. Il répond simplement aux requêtes du protocole : « quelles sont tes capacités ? », « liste tes outils », « exécute cet outil avec ces arguments ». Le client se charge de présenter ces résultats au LLM.
Pourquoi MCP plutôt qu'une simple API REST ?
La question légitime : pourquoi ne pas simplement connecter l'agent IA à votre API REST existante ?
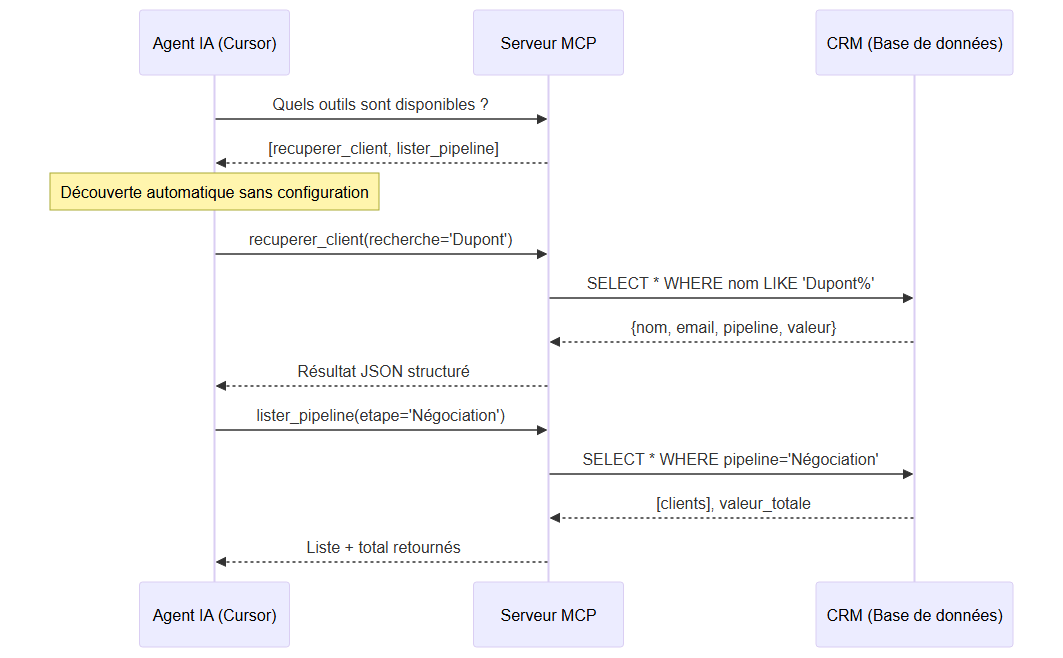 L'agent IA interroge le serveur MCP pour découvrir les outils disponibles, puis les appelle directement
L'agent IA interroge le serveur MCP pour découvrir les outils disponibles, puis les appelle directement
La différence fondamentale : MCP est un protocole de découverte d'outils. L'agent IA peut demander à votre serveur MCP « quels outils as-tu disponibles ? » et reçoit une liste structurée avec descriptions, paramètres et types. L'agent comprend alors quoi faire avec ces outils sans configuration manuelle de votre côté.
Avec une API REST classique, vous devez expliquer à l'agent comment l'utiliser dans chaque prompt : quelle route appeler, quel format de corps, quels en-têtes. Avec MCP, vous le faites une fois dans le code, sous forme de schémas typés, et tous les agents qui se connectent à votre serveur comprennent automatiquement. C'est cette auto-description qui change tout : moins de prompt engineering fragile, plus de fiabilité.
Sous le capot, MCP s'appuie sur JSON-RPC 2.0, un format de messages simple et éprouvé. Concrètement, trois types de messages circulent : les requêtes (le client demande quelque chose et attend une réponse), les réponses (le serveur renvoie un résultat ou une erreur), et les notifications (messages à sens unique, sans réponse attendue). Vous n'écrirez quasiment jamais ce JSON à la main : le SDK le sérialise et le désérialise pour vous. Mais savoir que ce protocole est standardisé aide à comprendre pourquoi un même serveur fonctionne indifféremment avec Cursor, Claude Desktop ou un client maison.
Comment le LLM choisit-il quel outil appeler ?
C'est une question fréquente, car le mécanisme est moins magique qu'il n'y paraît. Quand le client se connecte, il récupère la liste des outils avec leurs descriptions et leurs schémas, puis injecte ces informations dans le contexte du modèle. Lors d'une conversation, si la demande de l'utilisateur correspond à un outil disponible, le LLM émet un appel d'outil structuré — exactement comme le « function calling » que vous connaissez peut-être déjà. Le client intercepte cet appel, le transmet à votre serveur MCP, récupère le résultat, et le réinjecte dans le contexte pour que le modèle formule sa réponse finale. Votre travail côté serveur consiste donc surtout à bien nommer et bien décrire vos outils : c'est ce texte qui guide la décision du modèle.
Quels cas d'usage concrets pour un serveur MCP ?
Avant de plonger dans le code, ancrons l'intérêt avec des cas réels. Un serveur MCP brille dès qu'un agent IA doit interagir avec vos données plutôt qu'avec ses seules connaissances générales.
- Assistant commercial : un agent qui consulte votre CRM en temps réel pour répondre « quels prospects sont en négociation et pour quel montant ? » sans que vous ayez à copier-coller des extraits.
- Support technique augmenté : un outil
rechercher_documentationqui interroge votre base Notion ou Confluence pour fournir des réponses sourcées, à jour, sans hallucination. - Opérations internes : exposer des outils
creer_ticket,assigner_tacheouverifier_stockpour que l'agent agisse réellement sur vos systèmes, pas seulement converse. - Reporting à la demande : un outil qui agrège des métriques (ventes, performance, finances) et renvoie une synthèse que le modèle met en forme.
Le point commun de ces usages : la donnée vit chez vous, l'intelligence vit dans le modèle, et MCP fait le pont proprement et de façon réutilisable. Vous n'écrivez l'intégration qu'une fois.
Quels sont les prérequis pour créer un serveur MCP en TypeScript ?
Avant de coder, vérifiez que vous disposez de l'environnement minimal. Rien d'exotique : si vous faites déjà du Node, vous êtes prêt.
- Node.js 20 ou supérieur (le SDK requiert une version récente de Node)
- TypeScript installé :
npm install -g typescript - Un éditeur compatible MCP pour tester (Cursor ou Claude Desktop)
- Pour l'exemple, une source de données simulée — ici un CRM fictif en mémoire, que vous remplacerez par votre vraie base
Côté connaissances, un niveau intermédiaire en TypeScript suffit : comprendre async/await, les types d'objets et l'import de modules ESM. Aucune notion préalable de MCP n'est nécessaire — c'est précisément l'objet de ce guide.
Comment initialiser le projet ? (Étape 1)
 Pipeline complet : de l'initialisation npm à la sécurisation en production
Pipeline complet : de l'initialisation npm à la sécurisation en production
Commencez par créer le dossier du projet et installer les dépendances. Le paquet central est le SDK officiel @modelcontextprotocol/sdk, maintenu par l'équipe Model Context Protocol.
mkdir mon-serveur-mcp
cd mon-serveur-mcp
npm init -y
npm install @modelcontextprotocol/sdk
npm install -D typescript @types/node ts-node
npx tsc --init
Configurez ensuite votre tsconfig.json pour le mode ESM, requis par le SDK :
{
"compilerOptions": {
"target": "ES2022",
"module": "ESNext",
"moduleResolution": "bundler",
"outDir": "./dist",
"strict": true,
"esModuleInterop": true
}
}
Ajoutez "type": "module" dans votre package.json pour que Node interprète les fichiers compilés comme des modules ES. C'est une source d'erreurs fréquente : sans cette ligne, les imports .js du SDK échouent à l'exécution.
Comment créer le serveur MCP de base ? (Étape 2)
Le SDK propose deux niveaux d'API. La classe Server (bas niveau, server/index.js) donne un accès direct aux handlers du protocole — c'est l'approche que nous utilisons ici pour bien comprendre les mécanismes. La classe McpServer (haut niveau, server/mcp.js) est plus ergonomique ; nous y reviendrons.
Créez src/index.ts et instanciez le serveur en déclarant son nom, sa version et ses capacités :
// src/index.ts
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { CallToolRequestSchema, ListToolsRequestSchema } from "@modelcontextprotocol/sdk/types.js";
const server = new Server(
{ name: "mon-crm-mcp", version: "1.0.0" },
{ capabilities: { tools: {} } }
);
// Données simulées CRM (à remplacer par votre vraie source)
const clients = [
{ id: "1", nom: "Dupont SAS", email: "contact@dupont.fr", pipeline: "Négociation", valeur: 15000 },
{ id: "2", nom: "Martin & Co", email: "info@martin.com", pipeline: "Prospect", valeur: 5000 },
{ id: "3", nom: "Leclerc Digital", email: "bonjour@leclerc.io", pipeline: "Client actif", valeur: 42000 },
];
Le champ capabilities déclare ce que votre serveur sait faire. Ici, tools: {} annonce que le serveur expose des outils. Vous ajouterez resources: {} et prompts: {} plus loin, quand vous activerez ces primitives.
Comment définir des outils (tools) dans un serveur MCP ? (Étape 3)
Un outil (tool) est une action que l'agent peut déclencher. Chaque outil possède un nom, une description en langage naturel (lue par le LLM pour décider quand l'appeler) et un schéma d'entrée (inputSchema) au format JSON Schema qui décrit ses paramètres.
Déclarez d'abord la liste des outils disponibles via le handler ListToolsRequestSchema :
// Déclaration des outils disponibles
server.setRequestHandler(ListToolsRequestSchema, async () => ({
tools: [
{
name: "recuperer_client",
description: "Récupère les informations d'un client par son email ou son nom",
inputSchema: {
type: "object",
properties: {
recherche: { type: "string", description: "Email ou nom du client" }
},
required: ["recherche"]
}
},
{
name: "lister_pipeline",
description: "Liste tous les clients à une étape du pipeline commercial",
inputSchema: {
type: "object",
properties: {
etape: { type: "string", description: "Étape du pipeline (Prospect, Négociation, Client actif)" }
},
required: ["etape"]
}
}
]
}));
La qualité des descriptions est déterminante. Le LLM ne voit que ce texte pour décider quand et comment utiliser un outil. Une description vague (« récupère des données ») donne des appels hasardeux ; une description précise (« récupère un client par email ou nom ») guide l'agent vers le bon usage.
Comment se déroule un appel d'outil de bout en bout ?
Avant d'implémenter la logique, visualisons le cycle complet d'un appel. Le client commence par un handshake (initialize), découvre les capacités, liste les outils, puis appelle l'outil choisi par le LLM.
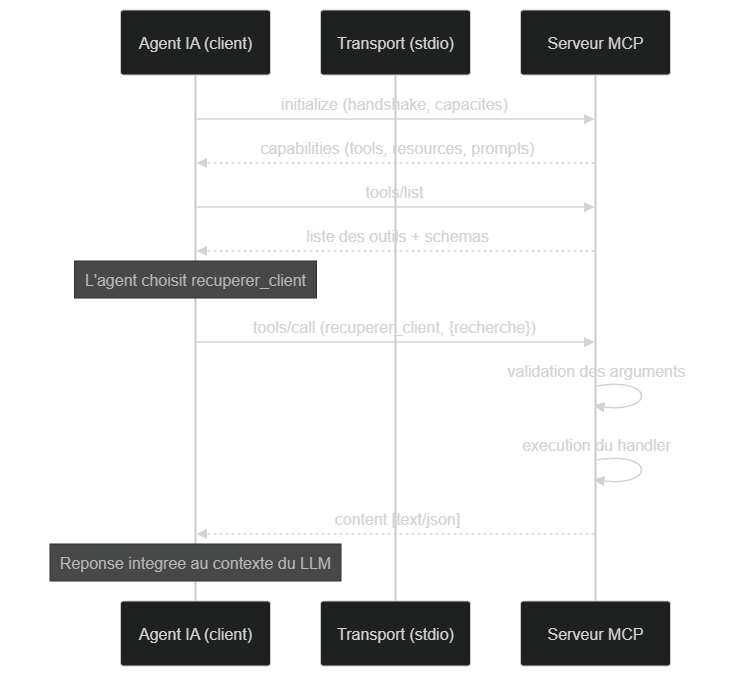 Du handshake à la réponse : le client négocie, liste les outils, puis exécute l'outil avec des arguments validés avant d'injecter le résultat dans le contexte du LLM
Du handshake à la réponse : le client négocie, liste les outils, puis exécute l'outil avec des arguments validés avant d'injecter le résultat dans le contexte du LLM
Implémentez maintenant la logique d'exécution via le handler CallToolRequestSchema. Il reçoit le nom de l'outil et ses arguments, exécute la bonne branche, et renvoie un tableau de content :
server.setRequestHandler(CallToolRequestSchema, async (request) => {
const { name, arguments: args } = request.params;
if (name === "recuperer_client") {
const { recherche } = args as { recherche: string };
const client = clients.find(c =>
c.email.includes(recherche) || c.nom.toLowerCase().includes(recherche.toLowerCase())
);
if (!client) return { content: [{ type: "text", text: "Aucun client trouvé" }] };
return {
content: [{ type: "text", text: JSON.stringify(client, null, 2) }]
};
}
if (name === "lister_pipeline") {
const { etape } = args as { etape: string };
const resultats = clients.filter(c => c.pipeline === etape);
const total = resultats.reduce((sum, c) => sum + c.valeur, 0);
return {
content: [{
type: "text",
text: JSON.stringify({ clients: resultats, valeur_totale: total }, null, 2)
}]
};
}
throw new Error("Outil non trouvé : " + name);
});
Le format de retour est important : content est toujours un tableau d'éléments typés (text, image, etc.). Pour des données structurées, on sérialise en JSON dans un bloc text. Le cast args as { recherche: string } est ici un raccourci d'exemple simplifié — en production, validez réellement les arguments (voir plus bas).
Comment démarrer le transport stdio et connecter à un client ? (Étape 4)
Le serveur est prêt mais ne communique pas encore. Il lui faut un transport. Pour un usage local (Cursor, Claude Desktop), le transport stdio est le plus simple : le client lance votre serveur comme un sous-processus et échange des messages via l'entrée/sortie standard.
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
// On écrit sur stderr car stdout est réservé au protocole
console.error("Serveur MCP démarré et en attente de connexions...");
}
main().catch(console.error);
Point crucial : avec le transport stdio, stdout est réservé aux messages du protocole. Tout console.log parasiterait la communication. Utilisez toujours console.error (qui écrit sur stderr) pour vos logs de débogage.
Compilez puis lancez :
npx tsc && node dist/index.js
Pour connecter le serveur à Cursor, déclarez-le dans ~/.cursor/mcp.json :
{
"mcpServers": {
"mon-crm": {
"command": "node",
"args": ["/chemin/absolu/vers/dist/index.js"]
}
}
}
La configuration pour Claude Desktop est quasi identique : on renseigne command et args dans le fichier claude_desktop_config.json (chemin variable selon l'OS). Dans les deux cas, le client se charge de démarrer le processus et de gérer le cycle de vie. Vous pouvez aussi exposer ce serveur à un workflow no-code : nous détaillons cette intégration dans notre guide connecter n8n à un serveur MCP.
Comment exposer des ressources et des prompts ? (Étape 5)
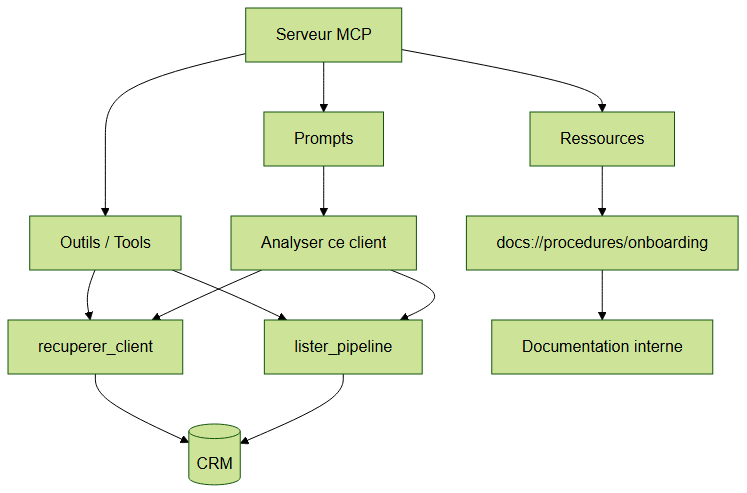 Architecture du serveur MCP : Tools pour les actions, Resources pour les données en lecture, Prompts pour les templates
Architecture du serveur MCP : Tools pour les actions, Resources pour les données en lecture, Prompts pour les templates
Les outils ne sont qu'une des trois primitives MCP. Vous pouvez aussi exposer des ressources (données en lecture seule, comme votre wiki interne) et des prompts (templates d'instructions pré-formatés).
Les ressources permettent à l'agent d'accéder à des données statiques ou semi-statiques sans appeler un outil : documentation, procédures, tarifs, catalogue produit. Chaque ressource est identifiée par un uri. On déclare la liste, puis on implémente la lecture :
import {
ListResourcesRequestSchema,
ReadResourceRequestSchema,
} from "@modelcontextprotocol/sdk/types.js";
// Lister les ressources exposées
server.setRequestHandler(ListResourcesRequestSchema, async () => ({
resources: [
{
uri: "docs://procedures/onboarding",
name: "Procédure d'onboarding client",
description: "Les étapes à suivre pour onboarder un nouveau client",
mimeType: "text/markdown",
},
],
}));
// Lire le contenu d'une ressource demandée
server.setRequestHandler(ReadResourceRequestSchema, async (request) => {
const { uri } = request.params;
if (uri === "docs://procedures/onboarding") {
return {
contents: [{
uri,
mimeType: "text/markdown",
text: "# Onboarding\n1. Créer le compte\n2. Planifier l'appel de cadrage\n3. Envoyer les accès",
}],
};
}
throw new Error("Ressource introuvable : " + uri);
});
Les prompts sont des templates d'instructions réutilisables que l'utilisateur déclenche d'un clic dans Cursor ou Claude Desktop. Exemple : un prompt « analyser ce client » qui enchaîne plusieurs outils. Pensez à activer ces primitives dans capabilities (resources: {}, prompts: {}) sinon le client ne les listera pas.
L'API haut niveau McpServer : faut-il l'utiliser ?
Tout le code ci-dessus utilise la classe Server bas niveau, idéale pour comprendre le protocole. En pratique, la documentation officielle recommande désormais la classe McpServer (server/mcp.js), qui gère pour vous la négociation des capacités, le routage des requêtes et la validation des entrées avec Zod.
Avec McpServer, un outil se déclare via registerTool, en passant un schéma Zod plutôt qu'un JSON Schema manuel :
// Exemple simplifié — vérifiez la signature exacte dans la doc officielle MCP
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { z } from "zod";
const server = new McpServer({ name: "mon-crm-mcp", version: "1.0.0" });
server.registerTool(
"recuperer_client",
{
description: "Récupère un client par email ou nom",
inputSchema: z.object({ recherche: z.string() }),
},
async ({ recherche }) => ({
content: [{ type: "text", text: `Recherche : ${recherche}` }],
})
);
L'avantage : Zod valide automatiquement les arguments avant d'appeler votre handler, et infère les types TypeScript. Vous supprimez les casts manuels (args as ...) et réduisez les erreurs. Pour un nouveau projet, McpServer est le choix par défaut recommandé ; la classe Server reste utile quand vous avez besoin d'un contrôle très fin sur les handlers bruts. Référez-vous à la documentation officielle du SDK TypeScript pour les signatures exactes, qui évoluent selon les versions.
Comment tester et déboguer son serveur avec MCP Inspector ? (Étape 6)
MCP Inspector est l'outil officiel de débogage. Il vous permet de tester votre serveur sans ouvrir Cursor à chaque modification — un gain de temps énorme pendant le développement. Lancez-le directement avec npx, sans installation préalable :
npx @modelcontextprotocol/inspector node dist/index.js
L'Inspector ouvre une interface web locale qui affiche la liste de tous vos outils, ressources et prompts, un formulaire pour tester chaque outil avec des arguments réels, les logs de chaque appel avec la réponse complète, et les erreurs en cas de problème de sérialisation.
C'est l'outil indispensable avant de connecter votre serveur à un vrai agent. Vous validez que chaque outil répond correctement, que les schémas sont bien interprétés, et que les erreurs sont propres — le tout dans une boucle de feedback de quelques secondes. Prenez l'habitude de garder l'Inspector ouvert pendant que vous codez : chaque ajout d'outil se vérifie immédiatement.
Comment automatiser les tests de votre serveur MCP ?
L'Inspector est irremplaçable pour le feedback immédiat en cours de développement, mais il ne couvre pas les tests de non-régression. Dès que votre serveur intègre une vraie base de données ou déclenche des actions à effet de bord — envoi d'e-mail, écriture en base, appel d'une API tierce — un jeu de tests automatisés devient une assurance-vie pour toute l'équipe. Sans cela, chaque nouvelle fonctionnalité risque de casser silencieusement un handler existant, sans que personne ne le remarque avant qu'un agent soit en production.
La stratégie la plus simple consiste à découpler les handlers de la couche transport. Vos handlers sont des fonctions TypeScript ordinaires : vous pouvez les appeler directement dans vos tests, en remplaçant la source de données réelle par un mock en mémoire — exactement comme le CRM fictif de notre exemple. Avec Vitest ou Jest, un test de l'outil recuperer_client configure quelques clients fictifs, invoque la logique métier, et vérifie que le content renvoyé contient les bons champs JSON. Le tout s'exécute en quelques millisecondes, sans processus Node à démarrer ni dépendances externes à mocker.
Pour des tests d'intégration plus réalistes, le SDK fournit InMemoryTransport, qui connecte un client et un serveur dans le même processus de test — sans socket ni stdio. Vous simulez ainsi un échange MCP complet : handshake initialize, tools/list, puis tools/call avec validation Zod incluse. C'est la manière la plus rigoureuse de tester la séquence d'initialisation, les messages d'erreur et le comportement des ressources. Cette approche s'intègre idéalement dans une pipeline CI/CD, où la suite de tests complète tourne automatiquement à chaque pull request sans aucune dépendance externe.
Adoptez également le principe du contrat d'outil stable : évitez de renommer un outil existant ou de modifier son schéma d'entrée de façon rétro-incompatible sans versionner le serveur. Les agents qui s'appuient sur votre serveur en production ont mémorisé les noms et les paramètres de vos outils. Un changement non annoncé casse silencieusement des workflows entiers. La règle d'or : préférez ajouter de nouveaux outils plutôt que modifier les existants, et incrémentez le champ version dans l'instanciation du serveur à chaque changement de surface d'API. Un court CHANGELOG des outils aide considérablement les équipes consommatrices à adapter leurs prompts ou leurs workflows no-code sans être prises par surprise.
Quelles sont les bonnes pratiques de validation, d'erreurs et de sécurité ?
Un serveur MCP qui marche en démo n'est pas un serveur prêt pour la production. Trois chantiers méritent votre attention.
Validation des entrées. Ne faites jamais confiance aux arguments reçus. Avec McpServer, Zod s'en charge ; avec la classe Server, validez manuellement avant d'exécuter quoi que ce soit. Un outil qui interroge une base SQL doit absolument se prémunir contre l'injection : utilisez des requêtes paramétrées, jamais de concaténation de chaînes.
Gestion des erreurs. Renvoyez des messages clairs et exploitables par le LLM. Plutôt que de laisser une exception brute remonter, capturez-la et retournez un content explicite (« Client introuvable », « Étape de pipeline invalide »). L'agent saura alors reformuler ou demander une précision à l'utilisateur, au lieu de planter.
Sécurité. Dès que le serveur quitte votre machine locale, plusieurs garde-fous deviennent indispensables :
- Authentification : valider un token secret (Bearer) dans chaque requête HTTP
- Rate limiting : limiter le nombre de requêtes par client et par minute
- Logging des accès : journaliser chaque appel d'outil avec son contexte (horodatage, outil, arguments)
- HTTPS obligatoire : ne jamais exposer un serveur MCP sur Internet sans chiffrement TLS
- Principe du moindre privilège : n'exposez que les outils réellement nécessaires, avec des permissions minimales
La sécurité d'un serveur MCP rejoint celle de toute API exposée. Si votre serveur déclenche des actions à effet de bord (écriture en base, envoi d'e-mails), pensez à un mécanisme de confirmation humaine pour les opérations sensibles.
Observabilité. Un serveur MCP qui tourne en silence est difficile à maintenir. Instrumentez chaque outil : durée d'exécution, taux d'erreur, fréquence d'appel par outil. Ces métriques révèlent vite quels outils sont réellement utilisés par l'agent — et lesquels ne le sont jamais (souvent parce que leur description est mauvaise). Couplez ces logs à un identifiant de session pour rejouer un échange complet quand un comportement vous surprend. C'est aussi en relisant ces traces que vous repérez les hallucinations : un outil bien décrit mais mal sollicité indique souvent un schéma d'entrée ambigu à corriger.
Idempotence. Pour les outils qui écrivent, visez l'idempotence quand c'est possible : un même appel répété ne doit pas créer deux fois la même ressource. Les agents peuvent relancer un appel après un timeout réseau ; sans idempotence, vous récoltez des doublons.
Comment déployer son serveur MCP en production ?
En local, le transport stdio suffit. Pour un serveur accessible à distance (équipe, plusieurs clients), passez au transport HTTP streamable, fourni par StreamableHTTPServerTransport (server/streamableHttp.js). Ce transport gère les sessions et le streaming des réponses, et s'intègre derrière un serveur web comme Express.
// Exemple simplifié — voir la doc officielle pour la gestion complète des sessions
import { StreamableHTTPServerTransport } from "@modelcontextprotocol/sdk/server/streamableHttp.js";
import { randomUUID } from "node:crypto";
const transport = new StreamableHTTPServerTransport({
sessionIdGenerator: () => randomUUID(),
});
await server.connect(transport);
// transport.handleRequest(req, res) est appelé depuis votre route HTTP (ex. POST /mcp)
Côté hébergement, un serveur MCP est un simple processus Node : il se déploie comme n'importe quelle application Node.js — conteneur Docker, VPS, ou plateforme PaaS. Mettez en place un gestionnaire de processus (PM2 ou un orchestrateur) pour le redémarrage automatique, et exposez les métriques pour surveiller la latence des outils. Pour un parcours de déploiement complet de bout en bout, consultez notre tutoriel pour déployer un agent IA sur un serveur MCP en 20 minutes.
Dépannage : quelles sont les erreurs les plus fréquentes ?
Quelques pièges classiques qui font perdre du temps aux débutants :
- Le serveur ne démarre pas / imports cassés : vérifiez
"type": "module"danspackage.jsonet la présence de l'extension.jsdans vos imports compilés. Le SDK est ESM only. - Le client ne voit aucun outil : la capacité correspondante n'est pas déclarée dans
capabilities, ou le handlerListToolsRequestScheman'est pas enregistré. - Communication brouillée en stdio : un
console.logtraîne quelque part. Remplacez-le parconsole.error. - Chemin introuvable côté client : utilisez un chemin absolu vers
dist/index.jsdansmcp.json. Les chemins relatifs ne sont pas résolus de manière fiable. - Arguments invalides acceptés : sans validation, des arguments mal typés passent et font planter le handler. Passez à
McpServer+ Zod.
Que pouvez-vous connecter ensuite ?
Une fois ce serveur MCP de base maîtrisé, les connexions naturelles suivantes sont :
- Votre base PostgreSQL ou MySQL via un pool de connexions
- HubSpot, Salesforce ou Pipedrive via leurs APIs officielles
- Votre documentation Notion ou Confluence pour le RAG interne
- Vos pipelines n8n pour déclencher des workflows depuis l'agent IA
MCP s'inscrit dans un mouvement plus large d'interopérabilité des agents. Pour comprendre où le protocole se situe par rapport aux standards émergents, lisez notre analyse MCP, A2A et l'interopérabilité des agents IA. Et si vous travaillez surtout côté automatisation, notre guide n8n AI Agent : transformez vos workflows en systèmes intelligents montre comment un serveur MCP démultiplie un agent no-code.
Combien de temps faut-il vraiment pour créer un serveur MCP ?
Le titre promet 30 minutes — tenons cette promesse honnêtement. Pour un serveur de base, un ou deux outils sur une donnée simple, 30 minutes suffisent une fois l'environnement Node prêt : 5 minutes d'initialisation, 10 minutes pour les outils, 5 minutes pour le transport et la connexion à Cursor, 10 minutes de tests dans l'Inspector. C'est la version « ça marche sur ma machine ».
Passer à un serveur production demande davantage : connecter une vraie base, valider chaque entrée avec Zod, ajouter authentification, rate limiting, logs et tests automatisés. Comptez plutôt une à deux journées selon la complexité des systèmes à brancher. La bonne nouvelle : la courbe d'apprentissage du protocole, elle, se franchit en une seule fois. Le deuxième serveur MCP que vous écrirez ira beaucoup plus vite que le premier.
Ce qu'il faut retenir
Créer un serveur MCP en TypeScript tient en quelques étapes claires : initialiser le projet avec le SDK officiel, déclarer des outils auto-décrits, implémenter leurs handlers, brancher un transport stdio, exposer ressources et prompts, tester avec MCP Inspector, puis sécuriser et déployer. La vraie valeur n'est pas dans la complexité du code — elle est minime — mais dans la standardisation : un serveur, tous vos agents le comprennent.
Commencez petit (un ou deux outils sur une donnée que vous maîtrisez), validez dans l'Inspector, puis branchez progressivement vos vrais systèmes. C'est la voie la plus rapide vers des agents IA réellement utiles dans votre contexte métier.
Vous voulez un serveur MCP personnalisé qui donne à vos agents accès à vos données propriétaires ? BOVO Digital conçoit et livre des serveurs MCP en production.
Étiquettes
FAQ
MCP fonctionne-t-il avec tous les agents IA ou seulement Claude ?
MCP est un protocole ouvert supporté par Claude (Anthropic), Cursor, et des adaptateurs sont disponibles pour GPT-5 via des wrappers communautaires. La compatibilité s'étend rapidement — en 2026, MCP est devenu le standard de facto pour la connexion agents-données.
Faut-il des compétences avancées en TypeScript pour créer un serveur MCP ?
Un niveau intermédiaire en TypeScript suffit. La librairie officielle @modelcontextprotocol/sdk abstrait la complexité du protocole. Les concepts clés à maîtriser : les types génériques TypeScript, async/await, et les bases de Node.js. Ce tutoriel vous guide sur tout ça.
Quelle différence entre l'API Server bas niveau et McpServer haut niveau ?
La classe Server (server/index.js) expose les handlers bruts du protocole via setRequestHandler — utile pour un contrôle fin. La classe McpServer (server/mcp.js) est l'API ergonomique recommandée : registerTool, registerResource et registerPrompt gèrent la négociation des capacités et la validation des entrées avec Zod. Vérifiez toujours la signature exacte dans la doc officielle MCP.
Quelle est la différence entre le transport stdio et le transport HTTP ?
Le transport stdio fait communiquer le client et le serveur via l'entrée et la sortie standard d'un processus local — idéal pour Cursor ou Claude Desktop. Le transport HTTP streamable (StreamableHTTPServerTransport) expose le serveur sur le réseau pour des clients distants, avec gestion de sessions. On commence par stdio, puis on passe à HTTP pour la production.
BOVO Digital peut-il créer un serveur MCP personnalisé pour mon entreprise ?
Oui. BOVO Digital conçoit des serveurs MCP qui connectent vos agents IA à vos données propriétaires : CRM, ERP, base documentaire, API internes. Délai typique : 5 à 10 jours ouvrés selon la complexité des systèmes à connecter.
Peut-on écrire des tests automatisés pour un serveur MCP TypeScript ?
Oui. La stratégie recommandée est de découpler les handlers de la couche transport et de les tester directement avec Vitest ou Jest, en substituant la source de données par un mock en mémoire. Pour des tests d'intégration complets, le SDK fournit InMemoryTransport qui simule un échange MCP entier (handshake, tools/list, tools/call) dans un seul processus, sans socket ni stdio.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
William Aklamavo
Expert en développement web et automatisation, passionné par l'innovation technologique et l'entrepreneuriat digital.


