
Nemotron 3 Nano Omni de NVIDIA : Ce Que Ça Change Pour l'Automatisation Multimodale
NVIDIA vient de lancer un modèle qui voit, entend et comprend le texte — tout à la fois, 9 fois plus efficacement. Pour l'automatisation, c'est un tournant. Voici ce que ça ouvre concrètement.

Mis à jour le

Nemotron 3 Nano Omni de NVIDIA : Ce Que Ça Change Pour l'Automatisation Multimodale
Depuis plusieurs années, l'automatisation IA reposait sur une architecture fragmentée : un modèle pour traiter le texte, un autre pour analyser les images, un troisième pour transcrire l'audio. Chaque brique communiquait avec les autres via des APIs, des délais et des coûts empilés. Les agents IA multimodaux restaient une promesse sur le papier, coûteux à construire et difficiles à maintenir à l'échelle.
NVIDIA vient de casser ce modèle avec le lancement de Nemotron 3 Nano Omni : un modèle multimodal unifié qui traite vision, audio et langage simultanément, avec une efficacité annoncée 9 fois supérieure aux architectures actuelles séparées. Pour les entreprises qui cherchent à automatiser des processus complexes impliquant plusieurs types de données, c'est une rupture significative. Cet article vous explique pourquoi, comment l'intégrer dans vos workflows existants, et ce que cela change concrètement pour vos opérations.
Ce qu'est Nemotron 3 Nano Omni
Nemotron 3 Nano Omni n'est pas simplement "un modèle qui fait tout". Sa particularité technique est un espace d'attention partagé entre les trois modalités. Là où GPT-4o traite l'image et le texte séquentiellement avec un contexte partiel, Nemotron 3 Nano Omni traite les trois flux dans le même espace de représentation.
En pratique, si vous envoyez une photo d'un produit endommagé avec un message audio du client décrivant le problème, le modèle comprend la relation entre les deux sans que vous ayez à les connecter explicitement. L'information visuelle influence directement le raisonnement textuel et vice-versa. C'est une différence architecturale fondamentale, pas une amélioration incrémentale.
Les spécifications annoncées selon la documentation officielle NVIDIA :
- Latence multimodale : 0,8 à 2 secondes (vs 3-8 secondes avec pipelines séparés)
- Coût relatif : ~30% du coût d'un pipeline GPT-4o Vision + Whisper équivalent
- Auto-hébergement possible via NVIDIA NIM (GPU A100/H100/L40S)
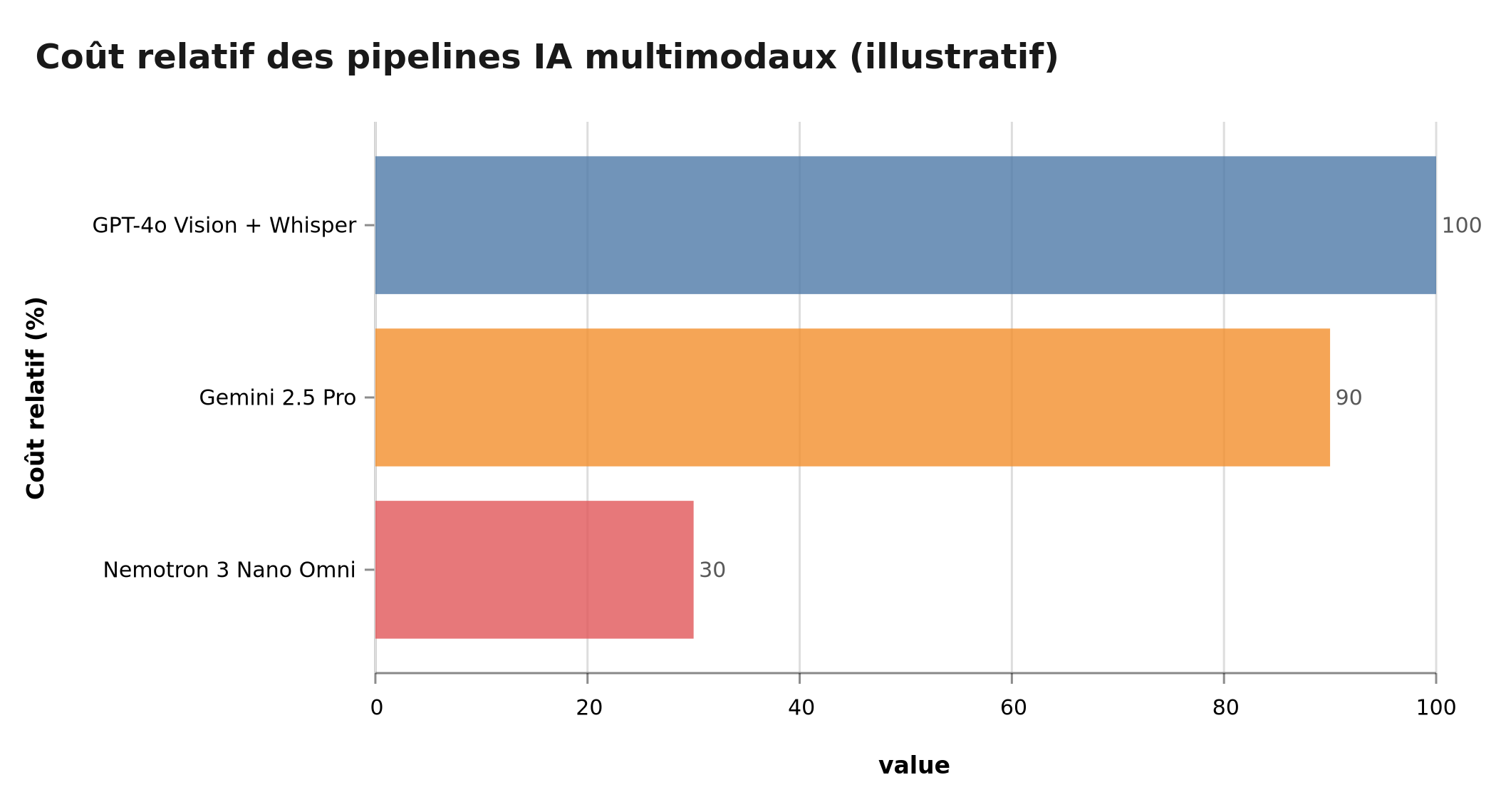 Nemotron 3 Nano Omni à ~30% du coût d'un pipeline GPT-4o équivalent — données illustratives
Nemotron 3 Nano Omni à ~30% du coût d'un pipeline GPT-4o équivalent — données illustratives
Architecture et fonctionnement technique
La famille Nemotron de NVIDIA s'inscrit dans la lignée des modèles développés sur l'architecture Megatron, un framework de training distribué développé en interne et documenté dans les publications de recherche NVIDIA. La version "Nano" désigne les variantes optimisées pour un déploiement efficace, avec un compromis calculé entre capacité et consommation de ressources. La variante "Omni" fait référence à l'architecture omnimodale : la capacité à traiter plusieurs types de données sans changement de contexte ou de pipeline.
Selon la documentation officielle NVIDIA, le modèle repose sur un encodeur visuel unifié capable de traiter des images statiques, des flux vidéo et des flux audio, dont les représentations sont projetées dans le même espace de tokens que le langage. Cette unification est ce qui permet à Nemotron 3 Nano Omni d'être entraîné de manière conjointe sur des paires multimodales — et non sur des données unimodales auxquelles on aurait ensuite ajouté des adaptateurs.
Sur le plan de la licence, NVIDIA propose Nemotron 3 Nano Omni sous la NVIDIA Open Model License, qui autorise un usage commercial avec certaines restrictions sur la redistribution et le fine-tuning. Cette licence est plus permissive que les licences propriétaires des modèles OpenAI ou Anthropic, tout en maintenant des garde-fous sur l'utilisation malveillante. Pour les entreprises qui cherchent à personnaliser le modèle sur leurs données métier, NVIDIA propose des outils de fine-tuning via la plateforme NVIDIA AI Foundry.
Le déploiement se fait principalement via NVIDIA NIM (Neural Inference Microservice), une couche de service standardisée qui expose le modèle sous forme d'API REST compatible OpenAI. Concrètement, cela signifie qu'un pipeline n8n ou Make déjà connecté à GPT-4o peut basculer vers Nemotron 3 Nano Omni en changeant seulement l'URL et la clé API — sans modifier la structure du payload.
Pourquoi les modèles "Nano" représentent un virage stratégique
Le marché de l'IA ne se joue plus uniquement sur les grands modèles. Depuis 2024, une tendance de fond émerge clairement : les modèles "small" ou "Nano" gagnent en pertinence dans les architectures de production. Cette tendance n'est pas un compromis par manque de moyens — c'est une stratégie délibérée.
Trois raisons expliquent pourquoi les modèles Nano deviennent stratégiques pour les entreprises en 2026.
La latence change tout pour l'expérience utilisateur. Un modèle qui répond en 1 seconde vs 5 secondes, ce n'est pas juste "plus rapide" — c'est la différence entre un produit utilisable et un prototype de laboratoire. Pour les applications de support client, d'analyse en temps réel ou d'assistants embarqués, la latence est une contrainte fonctionnelle, pas une préférence esthétique.
Le coût à l'échelle est exponentiel. À 0,08€ par interaction, un pipeline multimodal semble gérable pour 100 requêtes. À 100 000 requêtes par mois, c'est 8 000€ mensuels. Avec un modèle Nano à 0,025€ par interaction, le même volume coûte 2 500€ — une économie qui finance en elle-même plusieurs recrutements. Les modèles Nano transforment des cas d'usage "théoriquement possibles" en cas d'usage "économiquement viables".
L'edge computing change les contraintes de déploiement. Tous les cas d'usage ne peuvent pas envoyer des données dans le cloud. Les données médicales, les documents confidentiels, les flux vidéo de sécurité — autant de contextes où la donnée doit rester sur site. Les modèles Nano sont conçus pour tourner sur des infrastructures plus légères : une seule carte GPU NVIDIA A100 suffit pour servir plusieurs centaines de requêtes par minute avec Nemotron 3 Nano Omni via NIM.
Si vous explorez déjà des modèles locaux pour l'automatisation, la démarche s'apparente à ce que nous avons documenté dans le guide Tutoriel Gemma 4 avec Ollama et n8n — agent IA local gratuit et privé. La différence avec Nemotron 3 Nano Omni : le multimodal natif, qui ouvre des cas d'usage impossibles avec un modèle texte-seul.
Les agents IA multimodaux : ce que ça change concrètement
Un agent IA multimodal n'est pas simplement un modèle qui "voit" et qui "parle". C'est un système qui peut prendre des décisions basées sur des signaux hétérogènes — une image, un texte, un audio — et les traiter comme un tout cohérent, pas comme des données séparées.
La distinction est importante. Dans un pipeline classique, l'agent reçoit d'abord la transcription d'un audio, puis l'analyse d'une image, puis combine les deux textes pour raisonner. Chaque étape introduit une latence et une perte d'information : la transcription ne capture pas le ton, l'analyse d'image ne capture pas la nuance contextuelle. Dans un pipeline multimodal natif, l'agent traite tout simultanément — le ton vocal, l'expression de l'image et le contexte textuel sont présents dans le même espace de représentation au moment du raisonnement.
Ce que cela change en pratique :
- Un agent de support client peut voir la photo du problème ET entendre la frustration dans la voix du client dans le même appel, ajustant sa réponse en conséquence.
- Un agent de contrôle qualité peut analyser une vidéo de production et la mettre en relation avec les commentaires audio des opérateurs, sans ETL intermédiaire.
- Un agent RH peut évaluer une présentation vidéo (contenu + ton + langage corporel) et produire un feedback structuré en un seul appel.
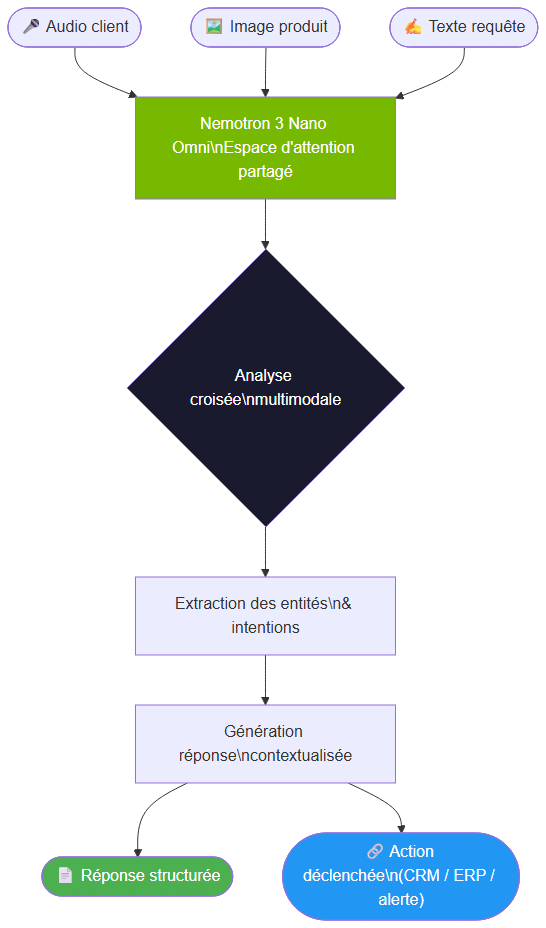 Architecture d'un agent multimodal : les trois flux entrent dans l'espace d'attention partagé et produisent une action ou une réponse contextualisée
Architecture d'un agent multimodal : les trois flux entrent dans l'espace d'attention partagé et produisent une action ou une réponse contextualisée
La comparaison avec les architectures concurrentes est révélatrice. GPT-4o de OpenAI propose une approche multimodale, mais la gestion de l'audio en temps réel reste distincte du pipeline vision-texte. Claude 3.5 Sonnet d'Anthropic excelle sur le texte et les images statiques, mais n'intègre pas l'audio nativement. Ce n'est pas une critique — ce sont des choix architecturaux différents. Nemotron 3 Nano Omni fait le pari d'une unification native plutôt qu'une modularité flexible.
Pour comprendre comment le paysage global des modèles évolue, notre analyse de la guerre IA ouverte vs fermée en 2026 donne le contexte stratégique de ces décisions.
Nemotron Nano vs Gemini Nano vs Apple Intelligence
La course aux modèles edge s'accélère. En 2026, NVIDIA n'est pas seul à vouloir apporter l'IA puissante sur des infrastructures limitées. Voici comment se positionnent les trois acteurs principaux selon leur documentation publique.
NVIDIA Nemotron 3 Nano Omni cible les environnements serveurs edge : datacenter privé, NVIDIA Jetson pour la robotique et l'industrie, serveurs on-premise des entreprises. Sa proposition de valeur est le multimodal natif avec audio intégré, via une API standard déployable en NIM. La licence commerciale ouverte est un avantage compétitif réel pour les entreprises qui veulent s'affranchir des APIs propriétaires.
Google Gemini Nano est conçu pour tourner directement sur smartphone (Android, Pixel, Galaxy) et vise des cas d'usage on-device : résumés, suggestions de réponse, aide à la rédaction. Ses capacités multimodales sont réelles mais orientées vers le texte et les images — l'audio natif n'est pas au même niveau d'intégration que Nemotron. L'atout de Gemini Nano est son écosystème Android et l'intégration directe dans les applications Google.
Apple Intelligence suit une philosophie différente : des modèles on-device ultra-optimisés pour les puces Apple Silicon (A17 Pro, M4), avec un focus sur la vie privée absolue et les use cases consumer (rédaction, résumés, Photos, Siri). Apple Intelligence n'expose pas d'API publique — c'est un avantage pour les utilisateurs finaux, mais une impossibilité pour les développeurs qui veulent l'intégrer dans des workflows business.
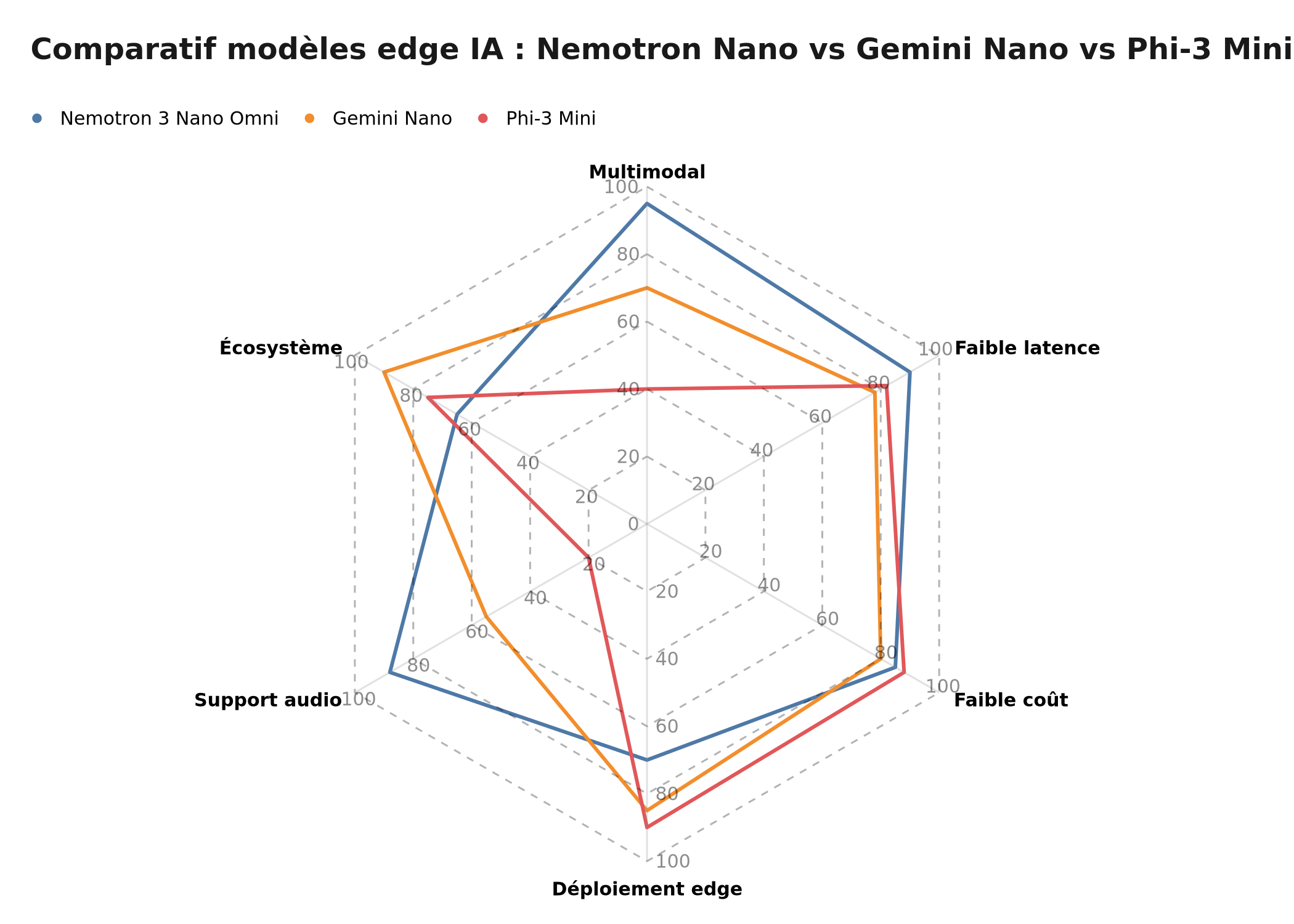 Comparaison illustrative des modèles edge — scores relatifs sur multimodal, latence, coût, déploiement edge, support audio et écosystème
Comparaison illustrative des modèles edge — scores relatifs sur multimodal, latence, coût, déploiement edge, support audio et écosystème
| Critère | Nemotron 3 Nano Omni | Gemini Nano | Apple Intelligence |
|---|---|---|---|
| Déploiement cible | Serveur edge / cloud privé | On-device Android | On-device Apple |
| Multimodal natif | Oui (vision + audio + texte) | Partiel (vision + texte) | Partiel (via intégration) |
| API publique | Oui (NVIDIA NIM) | Via Android ML Kit | Non |
| Licence commerciale | Oui (Open Model License) | Oui (via API) | Non (intégré OS) |
| Audio natif intégré | Oui | Limité | Partiel |
| Intégration n8n/Make | Via HTTP Request | Via API Google | Impossible |
Pour les développeurs et les automatiseurs, le critère décisif est l'intégrabilité dans des workflows existants. Nemotron 3 Nano Omni via NIM est le seul des trois qui s'intègre directement dans n8n, Make ou Zapier sans middleware propriétaire.
ROI calculé sur 3 cas d'usage réels
Cas 1 : Service client pour e-commerce (1 000 contacts/mois)
Architecture séparée (avant) : ~0,08€ par interaction = 80€/mois, latence 6-12 secondes. Nemotron 3 Nano Omni (après) : ~0,025€ par interaction = 25€/mois, latence 1-2 secondes.
Économie mensuelle : 55€ (-69%). Amélioration UX : latence divisée par 4.
Cas 2 : Traitement de factures pour comptable (500 documents/mois)
Architecture séparée (avant) : OCR tiers (1,5€/1000 pages) + LLM extraction = ~20,75€/mois + intégration complexe. Nemotron 3 Nano Omni (après) : un seul appel à 0,015€/document = 7,50€/mois + architecture simplifiée.
Économie mensuelle : 13,25€ (-64%). Suppression d'une dépendance externe.
Cas 3 : Contrôle qualité visuel pour PME industrielle (2 000 pièces/jour)
Ce cas d'usage n'était pas rentable avant. Le coût de 0,08€/pièce représentait 4 800€/mois — impossible pour une PME. Avec Nemotron 3 Nano Omni à 0,012€/pièce : 720€/mois. Ce cas d'usage devient viable pour les PME avec un budget de digitalisation normal.
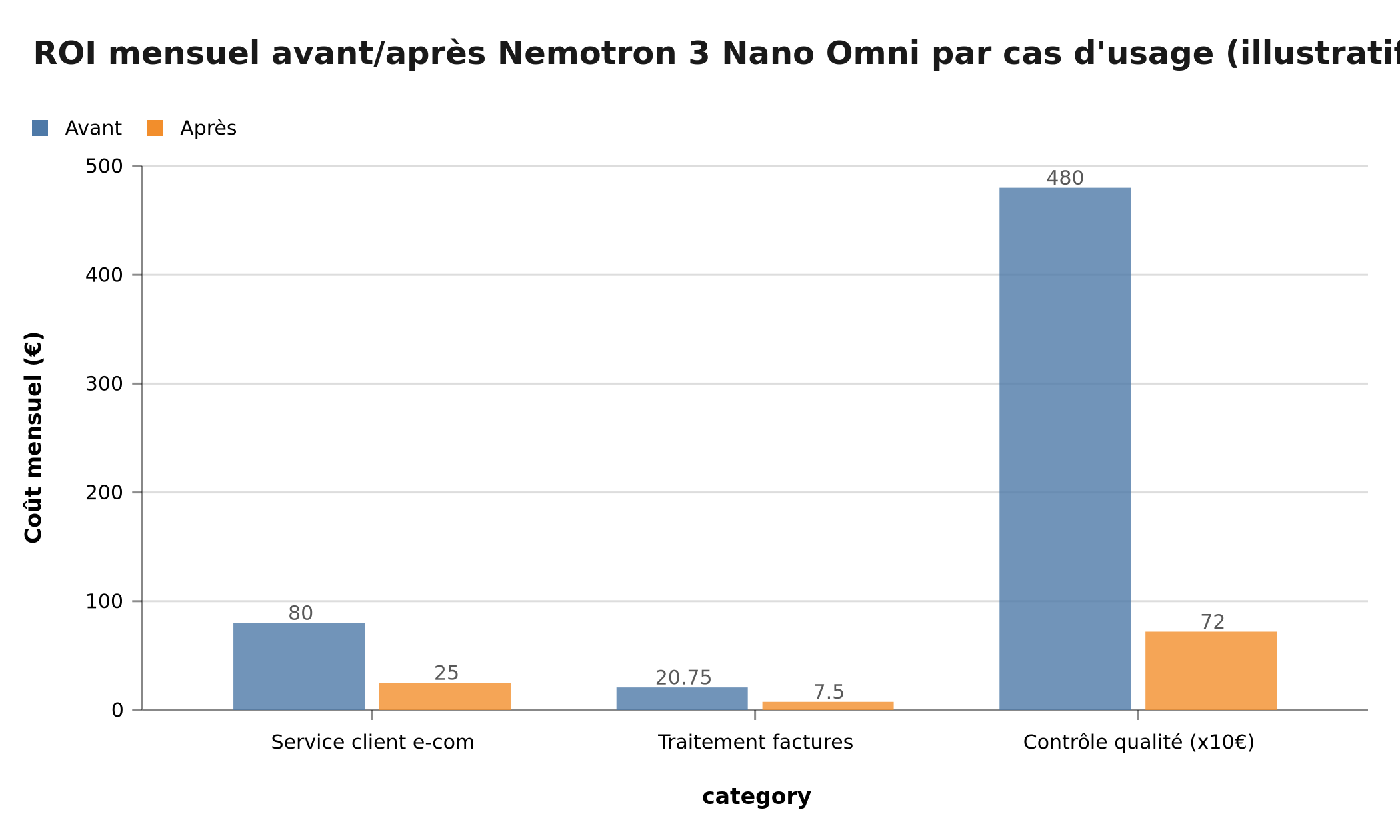 Économies mensuelles illustratives : -69% service client, -64% factures, -85% contrôle qualité PME
Économies mensuelles illustratives : -69% service client, -64% factures, -85% contrôle qualité PME
Ces chiffres sont illustratifs et varient selon les volumes, l'infrastructure choisie et le fournisseur cloud. Ils donnent néanmoins un ordre de grandeur réaliste basé sur les tarifs NIM publiés par NVIDIA.
Cas d'usage avancés : robotique, analyse vidéo, assistants embarqués
L'aspect le plus excitant de Nemotron 3 Nano Omni pour les industriels n'est pas le service client ou la facturation. Ce sont les cas d'usage qui n'existaient tout simplement pas avant — parce qu'aucun modèle ne pouvait traiter plusieurs flux en temps réel à un coût raisonnable.
Robotique et automatisation industrielle. NVIDIA positionne explicitement la gamme Nemotron pour les applications robotiques, notamment via la plateforme NVIDIA Jetson qui embarque des puces conçues pour l'inférence edge. Un robot équipé de caméras et de microphones peut aujourd'hui utiliser Nemotron pour comprendre son environnement (vision), les instructions de l'opérateur (audio) et les données de capteurs (texte structuré) dans un seul modèle. Selon la documentation officielle NVIDIA, la plateforme Isaac ROS intègre nativement les modèles NIM pour ces cas d'usage.
Analyse vidéo en temps réel. Les flux vidéo de surveillance, de production ou de transport génèrent des téraoctets de données que personne ne regarde vraiment. Un agent Nemotron connecté à un flux RTSP peut analyser chaque frame en recherchant des anomalies visuelles, les croiser avec les descriptions audio des opérateurs, et déclencher des alertes ciblées. Ce que cela permet concrètement : passer de la surveillance passive à l'inspection active, sans augmenter les effectifs humains.
Assistants embarqués pour les professionnels de terrain. Un technicien de maintenance qui porte des lunettes connectées ou utilise une tablette sur le terrain peut interagir avec un assistant Nemotron qui voit ce que lui voit (via la caméra), entend sa question vocale, et répond avec des instructions précises adaptées à ce qu'il observe. Ce scénario, qui relevait de la science-fiction il y a 3 ans, devient un cas d'usage déployable en 2026 avec NVIDIA NIM.
Analyse de réunions multimodales. Plutôt que de transcrire passivement une réunion, un agent multimodal peut analyser simultanément la transcription, les expressions faciales des participants et les slides partagées à l'écran. Le résumé produit est alors contextuel : il sait qu'une objection a été formulée sur slide 12 par le CFO avec un ton sceptique, et le signale comme point d'attention dans le compte-rendu.
Ces applications font écho aux annonces présentées lors de la dernière conférence NVIDIA GTC — que nous avons décortiquée pour les entrepreneurs.
Secteurs les plus impactés en 2026
E-commerce et retail : Traitement automatique des retours (photo du produit + message client → décision remboursement ou échange), description de produits à partir de photos, contrôle qualité des photos catalogue, analyse des avis clients multimodaux (texte + photo produit).
Finance et assurance : Analyse de sinistres (photos des dégâts + rapport audio de l'assuré → estimation automatique), traitement des justificatifs complexes, détection de fraude multimodale en combinant données visuelles et comportementales.
Santé (avec conformité RGPD) : Triage des demandes patients (image + description vocale → priorisation), analyse d'images médicales avec rapport automatique pour assister les médecins, documentation clinique dictée et structurée en temps réel.
RH et formation : Évaluation de présentations (enregistrement vidéo → analyse du contenu, du débit, de la posture), matching CV visuel et textuel, formation adaptative basée sur l'analyse des interactions apprenant.
Logistique : Contrôle de chargements (photos + bon de livraison audio → validation), détection de dommages en temps réel sur les chaînes de réception, suivi des anomalies de production.
Comment intégrer Nemotron 3 Nano Omni dans un pipeline n8n ou Make
Si vous avez déjà un pipeline n8n en production, l'intégration se fait via le nœud HTTP Request avec l'API NVIDIA NIM. La structure du payload est compatible OpenAI, ce qui signifie que vous pouvez réutiliser des workflows existants avec un minimum de modifications.
// Nœud n8n — HTTP Request vers NVIDIA NIM
{
"url": "https://integrate.api.nvidia.com/v1/chat/completions",
"method": "POST",
"headers": {
"Authorization": "Bearer YOUR_NVIDIA_API_KEY",
"Content-Type": "application/json"
},
"body": {
"model": "nvidia/nemotron-3-nano-omni",
"messages": [{
"role": "user",
"content": [
{ "type": "text", "text": "Analyse cette facture et extrait les données structurées" },
{ "type": "image_url", "image_url": { "url": "{{image_url}}" } }
]
}],
"max_tokens": 1024
}
}
Voici l'architecture complète d'un pipeline n8n intégrant Nemotron 3 Nano Omni, de la récupération des fichiers jusqu'à la mise à jour du CRM :
 Pipeline n8n Nemotron : de la réception d'un fichier multimodal jusqu'à l'action dans votre CRM ou système de notification
Pipeline n8n Nemotron : de la réception d'un fichier multimodal jusqu'à l'action dans votre CRM ou système de notification
Pour Make (ex-Integromat), le principe est identique via le module HTTP. La différence principale est dans la gestion des fichiers binaires : Make gère nativement les uploads de fichiers images via son module de données binaires, ce qui simplifie la construction du payload pour les cas d'usage de traitement de documents.
Bonnes pratiques d'intégration :
Gérez toujours les erreurs API avec un mécanisme de retry. NVIDIA NIM peut retourner des codes 429 (rate limit) ou 503 (surcharge temporaire) — prévoir un nœud de gestion d'erreur avec retry x1 après 5 secondes est la pratique standard. Compressez les images avant de les envoyer : une image de 10 Mo n'apporte pas plus d'information qu'une image de 1 Mo pour la majorité des cas d'usage d'analyse visuelle. Structurez vos prompts avec un schema JSON en output pour faciliter le parsing en aval. Et si vous traitez des données confidentielles, envisagez le déploiement on-premise via NVIDIA NIM sur vos propres GPU.
Si vous débutez avec les agents IA dans n8n, le guide n8n AI Agent — transformez vos workflows en systèmes intelligents couvre les fondamentaux avant d'ajouter la couche multimodale.
Les tendances edge AI en 2026 : pourquoi Nemotron arrive au bon moment
Le lancement de Nemotron 3 Nano Omni s'inscrit dans un contexte de marché qui a radicalement changé en 18 mois. Plusieurs tendances convergent pour rendre ce modèle particulièrement pertinent maintenant.
La souveraineté des données devient une contrainte réglementaire. Le RGPD en Europe, les évolutions législatives sur l'IA Act, et les directives sectorielles dans la santé et la finance poussent les entreprises à traiter les données dans des périmètres contrôlés. Le cloud public n'est plus systématiquement l'option par défaut. Les modèles déployables on-premise comme Nemotron via NIM répondent à cette contrainte sans sacrifier la puissance du multimodal.
Les coûts d'inférence cloud ont augmenté. Après une phase de tarification agressive en 2023-2024 pour capter des parts de marché, les grands fournisseurs (OpenAI, Anthropic, Google) ajustent leurs tarifs à la hausse. Les entreprises qui ont construit leurs workflows sur des APIs propriétaires découvrent que leur coût d'exploitation augmente au fur et à mesure que leur usage croît. Les modèles open weight comme Nemotron, déployables via NIM, offrent une alternative avec des coûts prévisibles à long terme.
L'IA générative arrive en production, pas seulement en PoC. En 2024, la majorité des projets IA en entreprise étaient des prototypes ou des pilotes. En 2026, selon les rapports sectoriels, plus de 40% des projets IA sont en production avec des SLA formels. Cela change les critères de sélection : la latence, la disponibilité, le coût à l'échelle et la contrôlabilité priment sur la "performance brute" mesurée en benchmark.
La robotique et l'automatisation physique accélèrent. L'industrie manufacturière, la logistique et l'agriculture investissent massivement dans des systèmes autonomes ou semi-autonomes. Ces systèmes nécessitent des modèles qui traitent des données sensorielles multiples en temps réel — exactement le cas d'usage cible de Nemotron 3 Nano Omni sur plateforme Jetson.
Dans ce contexte, NVIDIA ne propose pas simplement un modèle de plus. Elle positionne Nemotron comme le composant IA de base d'une stack edge complète : GPU Jetson ou datacenter privé + NVIDIA NIM + Nemotron multimodal. C'est une approche intégrée qui s'oppose à l'assemblage de briques disparates, et qui répond précisément aux besoins qui émergent en 2026.
Comparaison technique avec les modèles multimodaux actuels
| Capacité | GPT-4o | Claude 3.5 Sonnet | Gemini 2.5 Pro | Nemotron 3 Nano Omni |
|---|---|---|---|---|
| Vision | Images statiques | Images statiques | Images + vidéo | Images + vidéo + flux temps réel |
| Audio | Via Whisper séparé | Non | Audio natif | Audio natif intégré |
| Traitement simultané | Pipeline séquentiel | Texte seul | Partiel | Natif unifié |
| Latence (multimodal) | 3-8s | N/A | 2-5s | 0,8-2s |
| Coût relatif | 100% | N/A | ~90% | ~30% |
| Auto-hébergement | Non | Non | Non | Oui (via NVIDIA NIM) |
| Licence commerciale | Propriétaire | Propriétaire | Propriétaire | Open Model License |
Ce que ça ouvre pour vos projets d'automatisation
L'impact réel de Nemotron 3 Nano Omni n'est pas seulement dans le coût. C'est dans les nouveaux cas d'usage qui deviennent accessibles économiquement et techniquement :
- Réunions analysées en temps réel : transcription + analyse du sentiment sur les expressions faciales des participants + résumé structuré → en un seul appel
- Audit de visuels marketing : donner une image + un brief textuel → évaluation automatique de la cohérence brand
- Support technique avec photo : le client prend en photo son problème, l'agent comprend TOUT le contexte (image + message audio ou texte) et répond
- Inspection qualité continue : une caméra sur la chaîne de production, un micro pour les commentaires des opérateurs → alertes automatiques sans intervention humaine constante
- Documentation terrain automatique : le technicien parle, l'agent voit via la caméra → rapport structuré généré en temps réel, sans saisie manuelle
Ces cas d'usage étaient théoriquement possibles avant, mais économiquement non-viables. Ils le deviennent maintenant, pour des PME avec un budget d'automatisation normal.
Vous avez un cas d'usage multimodal à automatiser ? Nos experts n8n + NVIDIA NIM vous proposent un prototype fonctionnel en 5 jours.
Étiquettes
FAQ
Nemotron 3 Nano Omni est-il disponible en auto-hébergement ?
Oui, via NVIDIA NIM (Inference Microservice) sur des GPU NVIDIA (A100, H100, L40S). Pour les entreprises avec des données très sensibles, c'est l'option qui garantit que rien ne quitte votre infrastructure. BOVO Digital peut vous accompagner dans le déploiement et la configuration.
Comment Nemotron 3 Nano Omni se compare à GPT-4o sur les cas d'usage multimodaux ?
Nemotron 3 Nano Omni traite les trois modalités (vision, audio, texte) dans un espace d'attention partagé, là où GPT-4o les traite séquentiellement. Résultat : latence 3 à 4 fois inférieure et coût environ 70% moins élevé pour les traitements multimodaux équivalents selon les benchmarks NVIDIA.
BOVO Digital peut-il intégrer Nemotron 3 Nano Omni dans mes workflows n8n existants ?
Oui. L'intégration se fait via le nœud HTTP Request de n8n avec l'API NVIDIA NIM. BOVO Digital conçoit le pipeline complet : acquisition des données multimodales, traitement via Nemotron, structuration des résultats et intégration dans votre CRM ou ERP.
Quelle différence entre Nemotron 3 Nano Omni et Gemini Nano pour le déploiement edge ?
Gemini Nano de Google cible principalement le déploiement on-device sur smartphones Android (Pixel, Galaxy) avec un accent sur le texte et des capacités multimodales limitées. Nemotron 3 Nano Omni vise plutôt les environnements serveurs edge (Jetson, datacenter privé) avec une architecture multimodale native incluant l'audio — une différence architecturale majeure pour les workflows d'automatisation.
L'edge AI avec Nemotron est-elle adaptée aux PME sans département IT ?
Pas en auto-hébergement direct, mais via l'API cloud NVIDIA NIM, qui ne nécessite aucune infrastructure GPU propre. Une PME peut intégrer Nemotron 3 Nano Omni dans un workflow n8n ou Make avec un simple nœud HTTP Request et une clé API. BOVO Digital propose un onboarding en 5 jours pour aller de zéro à un pipeline multimodal en production.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
Vicentia Bonou
Développeuse Full Stack & Spécialiste Web/Mobile. Engagée à transformer vos idées en applications intuitives et sites web sur mesure.

