
DeepSeek V4 vs GPT-5.5 : Ce que la Guerre IA Ouverte/Fermée Change pour les Entreprises en 2026
En 48 heures, OpenAI sort GPT-5.5 et DeepSeek lâche V4 — un modèle multimodal open source MIT, 1 million de tokens, qui tourne sur des puces Huawei. Analyse complète de ce que ça change concrètement pour vos automatisations, votre stack IA et votre budget cloud en 2026.

Mis à jour le

DeepSeek V4 vs GPT-5.5 : ce que la guerre IA ouverte / fermée change pour les entreprises en 2026
En 48 heures, le marché de l'IA a basculé. Le 23 avril 2026, OpenAI annonce GPT-5.5, présenté comme « notre modèle le plus avancé », distribué dans ChatGPT, Codex et l'API. Le 24 avril 2026, DeepSeek réplique avec V4 — un modèle open source sous licence MIT, multimodal natif (texte, image, vidéo), 1 million de tokens de contexte, qui tourne entièrement sur des puces Huawei Ascend 950PR plutôt que sur Nvidia. Les deux modèles disponibles le même week-end. Deux philosophies opposées. Une guerre commerciale et géopolitique qui sort des laboratoires pour entrer dans vos workflows d'entreprise.
Pour la première fois depuis le lancement de GPT-4 en 2023, un modèle open source rivalise sérieusement avec le sommet du marché propriétaire — sur des benchmarks publics, à un prix divisé, sans dépendance au matériel américain. Cet article décortique ce qui change réellement pour les décideurs, les développeurs et les responsables d'automatisation, et donne une grille de décision claire pour répondre à la seule question qui compte : lequel mettre en production sur quel cas d'usage ?
1. Ce que GPT-5.5 apporte concrètement
GPT-5.5 n'est pas un changement de génération, c'est une consolidation agentique majeure. OpenAI ne vend plus un assistant qui répond à des questions ; OpenAI vend un agent qui exécute des tâches complexes de bout en bout — recherche web, analyse de données, génération de code, debug, opération de logiciels, écriture de documents et de tableurs.
Performances mesurées
- 82,7 % sur Terminal-Bench 2.0 : exécution autonome de tâches en ligne de commande.
- 78,7 % sur OSWorld-Verified : opérer un système d'exploitation réel via des actions GUI.
- 84,4 % sur BrowseComp : navigation web profonde et recherche multi-sources.
- Latence par token équivalente à GPT-5.4 : la performance monte sans ralentir.
Ces scores, selon les benchmarks officiels publiés par OpenAI au moment du lancement, positionnent GPT-5.5 comme le leader incontesté sur les tâches agentiques en environnement réel. Il est important de noter que les benchmarks d'inférence évoluent constamment — les scores mentionnés ici reflètent les données disponibles à la date de publication de cet article.
Ce qui change pour les workflows
Le saut n'est pas tant sur la qualité des réponses — déjà excellente avec GPT-5.4 — que sur la fiabilité agentique. GPT-5.5 utilise moins de tokens pour finir la même tâche, se corrige davantage tout seul, et enchaîne des plans multi-étapes sans perdre le fil après 30 minutes d'exécution. Pour une équipe qui automatise du support, du commercial ou de la production de contenu, ça veut dire : moins de supervision humaine, moins de boucles d'erreur, plus de tâches déléguables sans surveillance. Si vous utilisez déjà n8n pour orchestrer des agents IA, cette évolution de la fiabilité change directement le nombre de nœuds de contrôle nécessaires dans vos workflows — consultez notre article sur les agents IA avec n8n pour comprendre comment architecturer ces pipelines.
Le modèle économique reste fermé
Tout cela arrive dans un écosystème 100 % verrouillé : ChatGPT (Plus, Pro, Business, Enterprise), Codex, et l'API OpenAI. Pas de poids téléchargeables. Pas de contrôle sur l'inférence. Pas de garantie de souveraineté des données au-delà des promesses contractuelles. Et une dépendance complète à un fournisseur unique — avec une exposition aux changements de prix, de politique de modération et de disponibilité.
2. Ce que DeepSeek V4 change vraiment
V4 est techniquement et politiquement une rupture. Pas parce qu'il est meilleur que GPT-5.5 sur tous les benchmarks — il ne l'est pas — mais parce qu'il redéfinit le rapport qualité-prix-souveraineté sur lequel toutes les entreprises construisaient leur stratégie IA depuis 18 mois.
Architecture et capacités
DeepSeek V4 sort en deux variantes :
- V4-Pro : 1,6 trillion de paramètres totaux, 49 milliards activés par token (architecture MoE — Mixture of Experts).
- V4-Flash : 284 milliards de paramètres, 13 milliards activés par token — pour des cas d'usage à haut volume.
Les deux supportent une fenêtre de contexte d'1 million de tokens avec une sortie maximale de 384 000 tokens. Cela signifie pouvoir injecter une base documentaire complète, un code source entier, ou plusieurs heures de transcription audio dans une seule requête — sans découpage, sans RAG approximatif.
La multimodalité est native : texte, images et vidéos sont traités dans un même espace latent grâce à une technologie appelée Engram Memory, qui résout le problème du « lost in the middle » sur les très longs contextes. Sur MMLU-Pro, V4 atteint 86,2 à 87,5 % selon les benchmarks publics officiels disponibles à la date de publication — niveau élite, à quelques points seulement des modèles propriétaires sommitaux.
Le tarif qui casse le marché
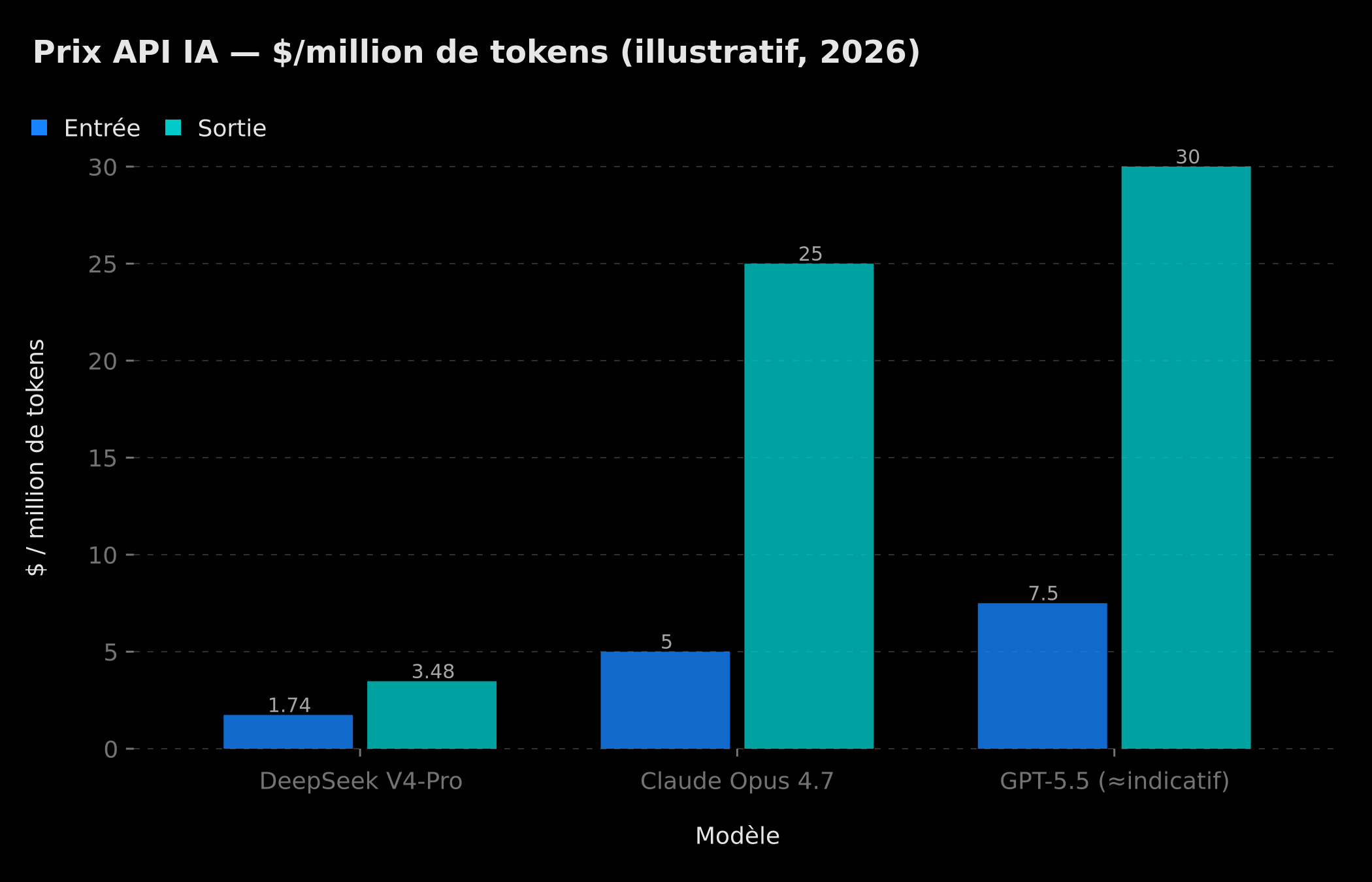 Comparaison des prix d'entrée et de sortie par million de tokens : DeepSeek V4-Pro à 1,74$/3,48$ contre Claude Opus 4.7 à 5$/25$ et GPT-5.5 à tarif supérieur indicatif
Comparaison des prix d'entrée et de sortie par million de tokens : DeepSeek V4-Pro à 1,74$/3,48$ contre Claude Opus 4.7 à 5$/25$ et GPT-5.5 à tarif supérieur indicatif
L'API de V4-Pro est facturée 1,74 $ en entrée et 3,48 $ en sortie par million de tokens. À titre de comparaison, GPT-5.5 reste sur des grilles plusieurs fois supérieures, et Claude Opus 4.7 facture 5 $ / 25 $ par million de tokens. Pour une PME qui consomme un milliard de tokens par mois sur ses automatisations IA, on passe d'une facture mensuelle à 5 chiffres à une facture divisée par 3 à 7. Le graphique ci-dessus est fourni à titre indicatif : les tarifs GPT-5.5 n'ayant pas été officiellement communiqués au format standardisé, le chiffre retenu est une estimation d'ordre de grandeur cohérente avec les informations publiques disponibles.
V4-Flash descend encore plus bas, ciblant les déploiements à très haut débit où la qualité de raisonnement peut être sacrifiée au profit du volume : idéal pour la classification, le résumé court ou la génération de métadonnées à grande échelle.
Open source réel sous licence MIT
V4 est publié sous licence MIT, avec les poids complets disponibles sur Hugging Face. Le modèle supporte les protocoles d'API OpenAI ChatCompletions et Anthropic — autrement dit, on peut remplacer GPT ou Claude dans n'importe quelle stack existante en changeant deux lignes de configuration. C'est un argument industriel énorme : une entreprise peut télécharger les poids, les héberger sur son propre cluster, et arrêter d'envoyer ses données chez OpenAI ou Anthropic sans réécrire son code.
La dimension géopolitique : Huawei plutôt que Nvidia
L'élément le plus stratégique de V4 n'est pas dans le modèle, c'est dans le matériel cible. DeepSeek a passé des mois à réécrire des portions du code pour faire tourner V4 sur les puces Huawei Ascend 950PR, et a accordé un accès anticipé exclusif à Huawei — privilège refusé à Nvidia et AMD. Ces puces affichent 2,8 fois la performance d'un Nvidia H20 (la plus puissante puce autorisée à l'export vers la Chine), pour un prix unitaire d'environ 6 900 $ — substantiellement moins cher qu'un H100.
En préparation du lancement, Alibaba, ByteDance et Tencent ont commandé plusieurs centaines de milliers d'unités Huawei. ByteDance seul prévoit plus de 5,6 milliards de dollars de dépenses sur ces puces en 2026. Le prix des Ascend a augmenté de 20 % sous l'effet de la demande. Un écosystème logiciel + matériel chinois s'est constitué en parallèle de l'écosystème américain — sans en dépendre.
Pour une entreprise européenne, africaine ou moyen-orientale, cela ouvre concrètement une deuxième option d'approvisionnement IA, indépendante des restrictions d'export américaines, des sanctions, et des aléas politiques entre Washington et la Silicon Valley.
3. Comment choisir entre GPT-5.5, DeepSeek V4 et les alternatives
La bonne réponse n'est presque jamais « un seul modèle pour tout ». Une stack IA d'entreprise sérieuse en 2026 utilise 2 à 4 modèles différents en parallèle, choisis pour leurs forces respectives. L'arbre de décision ci-dessous formalise ce raisonnement.
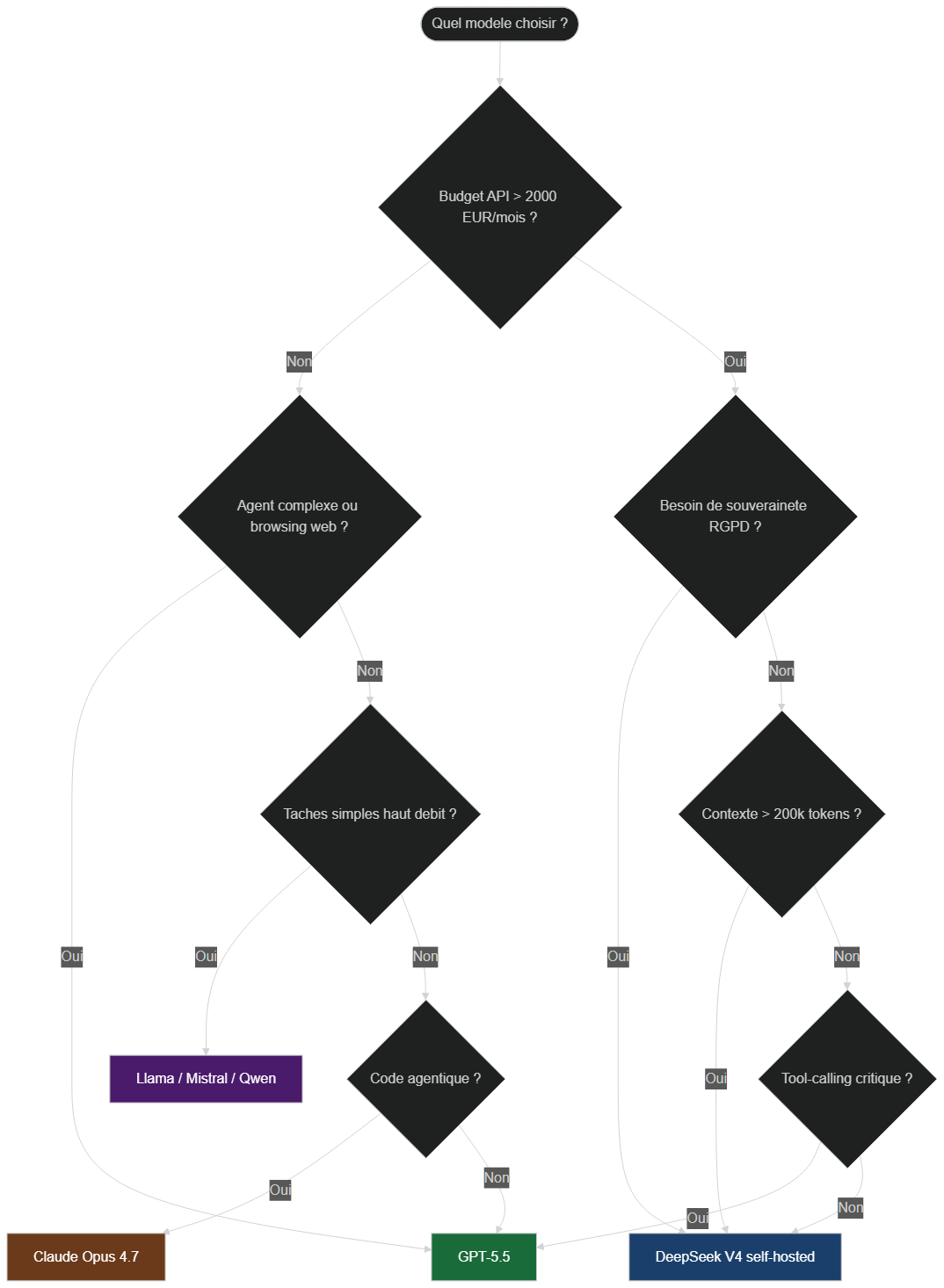 Flowchart de sélection du modèle IA : GPT-5.5, DeepSeek V4, Claude Opus 4.7 ou modèles open source selon le budget, la souveraineté et le type de tâche
Flowchart de sélection du modèle IA : GPT-5.5, DeepSeek V4, Claude Opus 4.7 ou modèles open source selon le budget, la souveraineté et le type de tâche
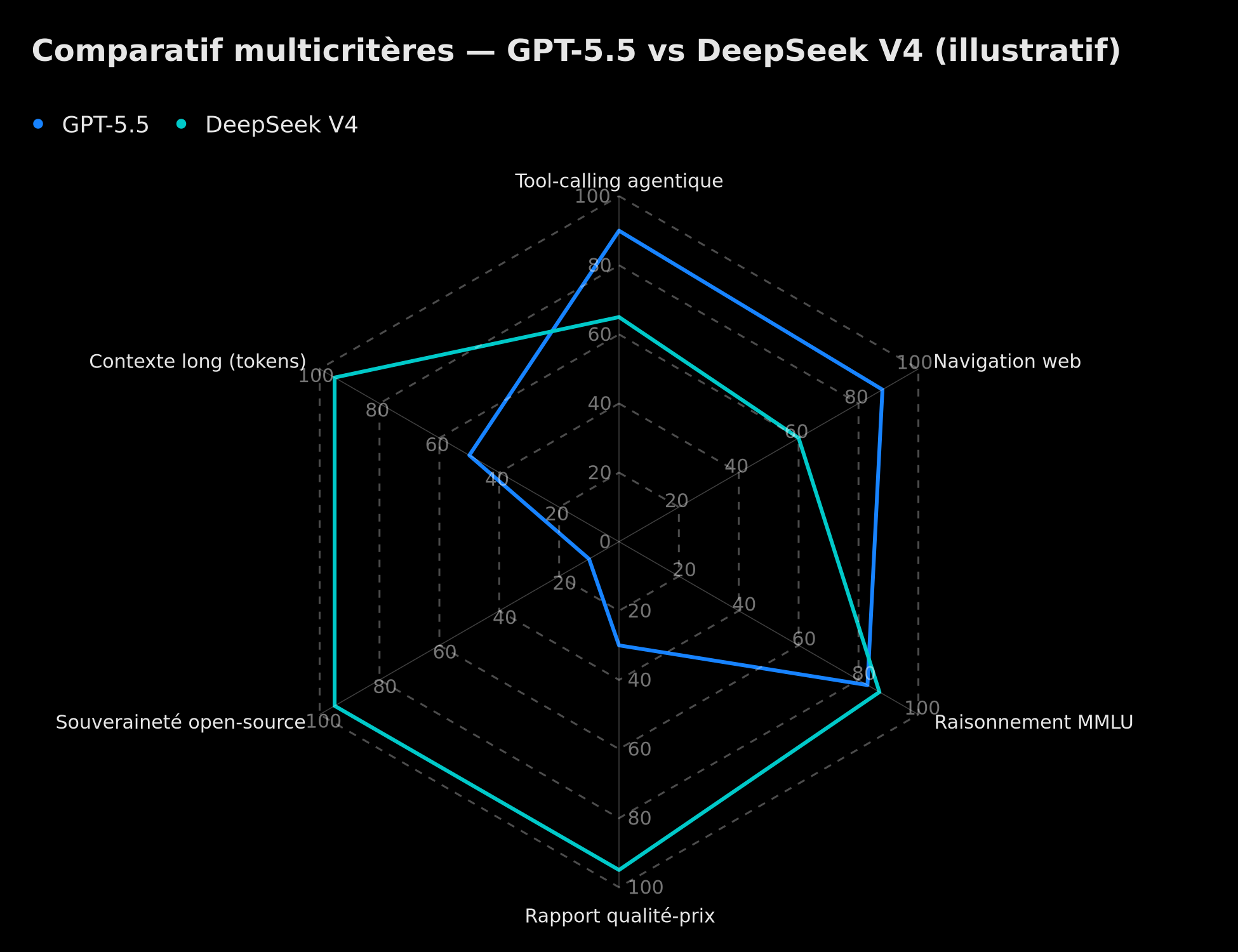 Radar multicritères GPT-5.5 vs DeepSeek V4 : tool-calling agentique, navigation web, raisonnement MMLU, rapport qualité-prix, souveraineté open-source, contexte long (illustratif)
Radar multicritères GPT-5.5 vs DeepSeek V4 : tool-calling agentique, navigation web, raisonnement MMLU, rapport qualité-prix, souveraineté open-source, contexte long (illustratif)
Choisir GPT-5.5 si…
- Vous avez déjà des automatisations branchées sur l'API OpenAI et un budget qui supporte les tarifs.
- Vos cas d'usage exigent du tool-calling agentique fiable, du browsing web profond ou de l'opération de logiciels (le terrain de jeu où GPT-5.5 domine clairement).
- Vous travaillez avec des clients américains qui exigent des prestataires sur l'écosystème OpenAI.
- La vitesse de mise en production prime sur le coût récurrent — pas de cluster GPU à gérer, tout est managé.
Choisir DeepSeek V4 si…
- Votre facture API actuelle dépasse 2 000 € par mois et que la baisse de coût ferait une différence stratégique.
- Vous voulez héberger le modèle en interne (souveraineté, RGPD strict, secret professionnel, données médicales ou bancaires).
- Vous avez des cas d'usage à très long contexte : analyse de codebase entière, traitement documentaire massif, audit de transcripts longs.
- Vous voulez tester la dépendance technologique à l'écosystème américain — option B en cas de coup dur réglementaire.
Choisir Claude Opus 4.7 si…
- Vous faites du développement logiciel agentique sérieux. Sur le CursorBench, Opus 4.7 atteint 70 % contre 58 % pour Opus 4.6, et reste l'un des modèles les plus rigoureux pour ne pas halluciner sur des tâches techniques longues.
- Vous avez besoin d'une vision haute résolution : les images jusqu'à 2 576 pixels permettent de lire des screenshots UI denses ou des diagrammes complexes.
Architecture recommandée pour 2026
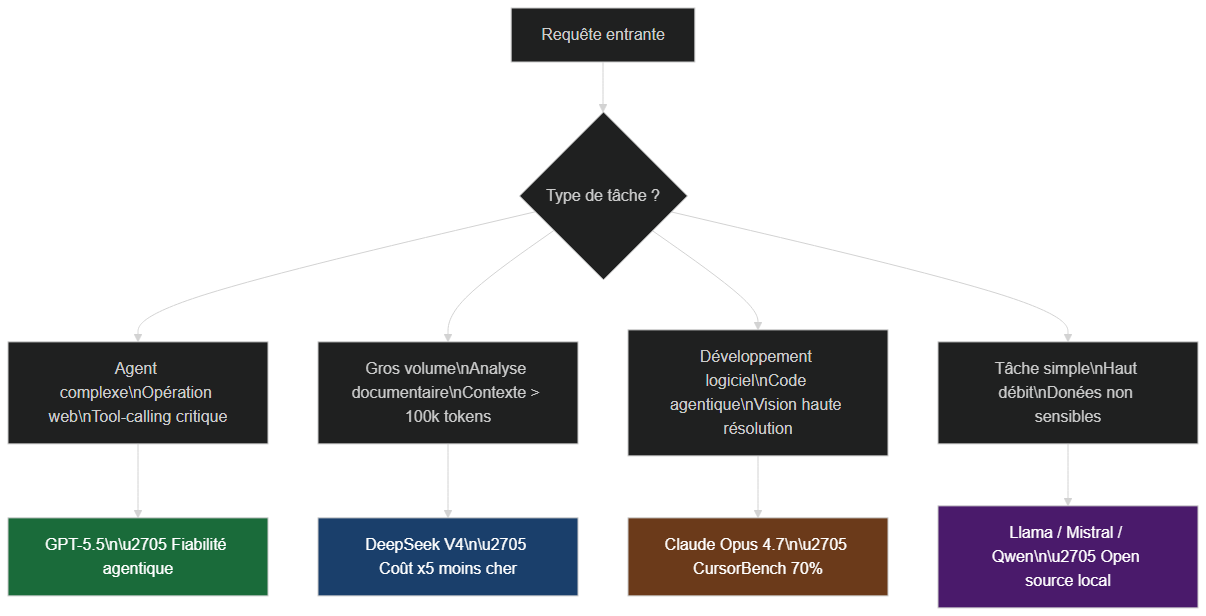 Logique de routage multi-modèles : GPT-5.5 pour les agents complexes, DeepSeek V4 pour les gros volumes, Claude Opus 4.7 pour le code, et modèles open source pour le haut débit
Logique de routage multi-modèles : GPT-5.5 pour les agents complexes, DeepSeek V4 pour les gros volumes, Claude Opus 4.7 pour le code, et modèles open source pour le haut débit
Chez BOVO Digital, nous concevons aujourd'hui les workflows clients avec une logique de routage multi-modèles :
- GPT-5.5 pour les tâches agentiques générales et l'opération web.
- DeepSeek V4 pour les gros volumes de génération, l'analyse documentaire massive, et les traitements internes où la souveraineté compte.
- Claude Opus 4.7 pour le code applicatif et les agents techniques sensibles.
- Modèles open source plus petits (Llama, Mistral, Qwen) pour les tâches simples à très haut débit.
Cette architecture multi-modèles est exactement ce que nous déployons dans nos solutions d'automatisation IA, nos chatbots et agents conversationnels et les SaaS IA-natifs que nous concevons pour nos clients.
4. Les conséquences pratiques pour votre business
Pour les dirigeants : revoir les contrats fournisseurs
Si vous avez signé en 2024 ou 2025 un contrat exclusif avec un fournisseur IA unique, il est probablement à renégocier. Le rapport de force a basculé. Les fournisseurs propriétaires acceptent désormais des clauses de portabilité, des SLA renforcés et des baisses tarifaires que vous n'auriez pas obtenues il y a 6 mois.
Pour les responsables tech : architecture pluraliste
Une stack abstraite — qui parle à un orchestrateur (LangChain, LlamaIndex, ou une couche maison) plutôt qu'à un fournisseur spécifique — est devenue une exigence stratégique, pas un nice-to-have. Le coût de la dette technique d'un système monolithiquement collé à OpenAI est désormais quantifiable : c'est la différence entre votre facture actuelle et celle que vous auriez sur DeepSeek pour les mêmes tâches.
Pour les équipes commerciales et marketing : opportunité de re-pricing
Les automatisations IA proposées aux clients en 2025 (rédaction de masse, qualification de leads, agents conversationnels) ont vu leur coût marginal chuter d'un facteur 5 à 10 en quelques mois. Soit vous baissez vos prix et prenez du marché. Soit vous gardez vos prix et augmentez votre marge. Mais ne pas trancher revient à laisser un concurrent le faire à votre place.
Pour les indépendants : se positionner sur l'orchestration
La compétence rare en 2026 n'est plus de savoir prompter. C'est savoir router intelligemment des modèles en fonction du cas d'usage, du coût et de la sensibilité des données. Les freelances qui maîtrisent n8n, Make.com, LangGraph et les architectures multi-modèles sont sur une vague que la majorité du marché n'a pas encore intégrée.
5. Les angles morts que personne ne mentionne
Le risque de dépendance Huawei
Choisir DeepSeek V4 hébergé sur des puces Huawei revient à substituer une dépendance américaine par une dépendance chinoise. Pour des cas d'usage critiques, les deux dépendances sont des risques — pas une solution. Une stratégie sérieuse 2026 inclut au moins un modèle qui tourne sur du matériel européen (par exemple Llama ou Mistral sur des GPU chez OVHcloud, Scaleway ou Anthropic via Vertex AI européen).
Le coût caché de l'auto-hébergement
Télécharger les poids de V4 sous MIT ne suffit pas. Faire tourner un MoE 1,6T en production demande plusieurs serveurs GPU haut de gamme, une équipe MLOps capable de gérer du sharding, du quantization, du serving optimisé. Pour la majorité des PME, payer l'API DeepSeek reste plus rentable que d'auto-héberger — et c'est une décision à objectiver, pas à idéologiser.
Le verrouillage par la qualité de tool-calling
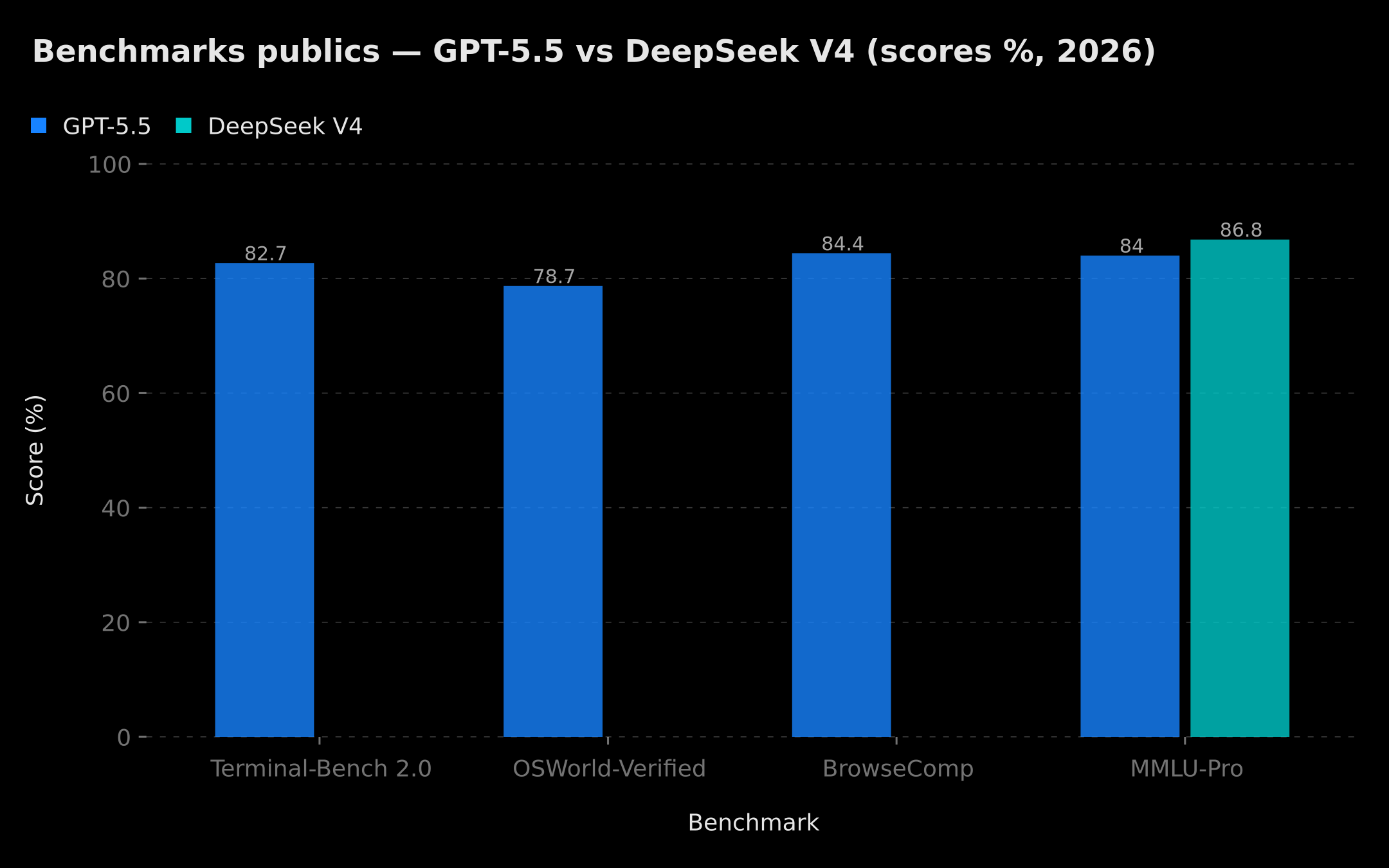 Comparaison des scores publics disponibles : Terminal-Bench 2.0, OSWorld-Verified, BrowseComp (GPT-5.5) et MMLU-Pro (GPT-5.5 vs DeepSeek V4) — données au moment de la publication
Comparaison des scores publics disponibles : Terminal-Bench 2.0, OSWorld-Verified, BrowseComp (GPT-5.5) et MMLU-Pro (GPT-5.5 vs DeepSeek V4) — données au moment de la publication
Sur des agents complexes, GPT-5.5 reste devant pour la simple raison qu'OpenAI a investi 18 mois à fiabiliser le tool-calling structuré, la gestion des erreurs et les plans multi-étapes. DeepSeek V4 supporte le protocole, mais les retours terrain montrent encore des écarts de robustesse de 10 à 20 % sur des agents en production. Si votre business dépend d'agents qui exécutent des actions critiques (paiements, prises de rendez-vous, opérations CRM), commencez par GPT-5.5 ou Claude, mesurez, puis optimisez. Pour éviter les hallucinations dans vos workflows agentiques, quelle que soit la stack choisie, consultez notre guide complet sur comment éviter les hallucinations IA en entreprise.
6. Vitesse d'inférence, contexte et cas d'usage réels
Au-delà des benchmarks académiques, deux dimensions pratiques structurent le choix en production : la vitesse d'inférence et la gestion réelle du contexte long.
Vitesse d'inférence : V4-Flash vs V4-Pro vs GPT-5.5
DeepSeek V4-Flash est conçu pour la faible latence à grande échelle. Grâce à son architecture MoE légère (13 milliards de paramètres activés par token), il atteint des vitesses de génération comparables à des modèles open source beaucoup plus petits tout en conservant une qualité de raisonnement sensiblement supérieure. C'est l'option de référence pour les applications temps réel : chatbots à fort trafic, assistants vocaux, pipelines de classification documentaire à grande cadence.
V4-Pro sacrifie la vitesse au profit de la profondeur : avec 49 milliards de paramètres activés par token, il s'impose sur les tâches d'analyse longue, de raisonnement multi-étapes et de synthèse sur contextes massifs. GPT-5.5 se situe dans une position hybride : sa latence par token est comparable à GPT-5.4 (selon OpenAI) mais son architecture fermée ne permet pas de mesures indépendantes publiées à ce jour.
1 million de tokens : qu'est-ce que ça change concrètement ?
La fenêtre de contexte d'1 million de tokens de DeepSeek V4 n'est pas qu'un chiffre marketing. En pratique, elle redéfinit l'utilité du RAG. Un pipeline RAG classique découpe les documents en chunks, les indexe dans une base vectorielle, et en récupère une fraction avant chaque requête — un processus introduisant des approximations et des pertes d'information entre les passages. Avec 1 million de tokens, il devient possible d'injecter directement un rapport annuel de 400 pages, une base de code de 150 000 lignes, ou six mois de tickets support dans une seule requête, sans découpage, sans perte de cohérence.
Cela ouvre trois cas d'usage qui étaient inaccessibles il y a 12 mois : l'audit complet de codebase en une seule passe, la synthèse de documentation légale ou réglementaire massive sans pré-filtrage, et la modélisation de personas à partir d'historiques de conversation très longs. Pour en savoir plus sur les architectures RAG et leurs limites, consultez notre article Votre IA est bête et c'est normal — RAG.
HumanEval, MATH et GSM8K : ce que les benchmarks de code et de raisonnement révèlent
Plusieurs benchmarks standardisés permettent d'évaluer les modèles sur des dimensions spécifiques au-delà de MMLU-Pro. Sur HumanEval (résolution de problèmes de code Python), les modèles de la génération DeepSeek V4 et GPT-5.5 se situent tous deux dans la gamme haute d'après les données publiques disponibles à la date de publication — avec GPT-5.5 maintenant un avantage sur les tâches nécessitant de l'exécution et du debugging multi-étapes, et DeepSeek V4 se montrant compétitif sur la complétion de code pur.
Sur MATH (raisonnement mathématique avancé) et GSM8K (problèmes de mathématiques primaires), la génération DeepSeek a historiquement démontré des performances solides, cohérentes avec ses scores MMLU-Pro. Cependant, les chiffres précis pour V4 sur ces benchmarks n'étaient pas tous disponibles dans la documentation officielle au moment de la rédaction de cet article — nous recommandons de consulter directement les benchmarks officiels publiés par DeepSeek et OpenAI pour des comparaisons à jour.
7. IA ouverte vs IA fermée : ce que les licences impliquent vraiment
La distinction entre IA ouverte et fermée va bien au-delà du droit de télécharger des poids. Elle touche directement la gouvernance, la sécurité, la personnalisation et le contrôle réglementaire.
 Comparaison structurée IA ouverte vs fermée : hébergement souverain, personnalisation, coût à volume, lock-in, MLOps, fiabilité agentique
Comparaison structurée IA ouverte vs fermée : hébergement souverain, personnalisation, coût à volume, lock-in, MLOps, fiabilité agentique
Ce que la licence MIT change vraiment
Sous licence MIT, DeepSeek V4 peut être commercialisé, modifié, intégré dans des produits SaaS, et redistribué sans restriction et sans redevance. Cela signifie qu'une entreprise peut fine-tuner le modèle sur ses propres données propriétaires, l'intégrer dans un produit qu'elle commercialise, et conserver une pleine propriété intellectuelle sur les adaptations réalisées — ce qu'aucune licence propriétaire ne permet.
Du point de vue RGPD, l'hébergement sur site des poids d'un modèle MIT apporte une certitude juridique que les modèles en API ne peuvent pas garantir : les données de vos utilisateurs ne transitent jamais hors de votre infrastructure, aucun fournisseur tiers ne peut y accéder, et vous maîtrisez intégralement les journaux d'accès. Pour des secteurs comme la santé, la banque, le droit ou la défense, c'est un prérequis non négociable.
Audit de sécurité et confiance
Un avantage souvent sous-estimé de l'open source est l'auditabilité. Avec un modèle MIT, votre équipe de sécurité peut inspecter les poids, analyser les comportements, et instrumenter l'inférence à chaque couche. Avec un modèle propriétaire, vous faites confiance aux certifications SOC 2 et aux politique de confidentialité de l'éditeur — sans possibilité de vérification indépendante. Pour des applications critiques (analyse de contrats, détection de fraude, modération de contenu sensible), cet écart de transparence est un argument de poids en faveur de l'open source.
Le fine-tuning comme avantage concurrentiel
La licence MIT permet également de spécialiser le modèle sur un domaine métier avec du fine-tuning supervisé. Un cabinet juridique peut entraîner V4 sur des milliers de contrats sectoriels. Un acteur de l'e-commerce peut l'adapter à son catalogue produit et à ses politiques de retour. Un opérateur de santé peut créer une version conforme aux nomenclatures médicales locales. Ce niveau de personnalisation est impossible avec des modèles propriétaires, où le fine-tuning — lorsqu'il est proposé — reste partiel, coûteux et non auditable.
Pour explorer comment des modèles open source comme Gemma peuvent être auto-hébergés avec Ollama et intégrés à n8n, consultez notre tutoriel pratique Gemma 4 + Ollama + n8n : agent IA local gratuit et privé.
8. L'écosystème IA ouverte s'accélère en 2026
La sortie de DeepSeek V4 n'est pas un événement isolé. Elle s'inscrit dans une dynamique de fond qui s'accélère depuis 24 mois : l'écosystème open source IA rattrape le propriétaire à une vitesse que peu d'analystes avaient anticipée.
L'effet Hugging Face et la normalisation des poids
Hugging Face dépasse en 2026 les 800 000 modèles publiés publiquement. L'infrastructure d'hébergement, de versionnage et de déploiement de modèles s'est industrialisée : Hugging Face Inference Endpoints, vLLM, TGI (Text Generation Inference) et Ollama permettent désormais à une équipe technique de taille modeste de déployer un modèle de plusieurs dizaines de milliards de paramètres en quelques heures, sans expertise MLOps de niveau recherche.
Ollama en particulier a démocratisé l'exécution locale de grands modèles sur du matériel grand public — MacBook Pro M3, PC gaming, serveurs d'entrée de gamme — rendant l'IA locale accessible à des indépendants et des PME qui n'avaient aucun budget cloud IA il y a 18 mois.
L'adoption enterprise s'accélère
Les grandes entreprises européennes — banques, assureurs, industriels — intègrent l'open source IA dans leurs feuilles de route 2026 avec une logique de souveraineté qui n'était pas aussi explicite en 2024. La question n'est plus « est-ce que l'open source est prêt ? » mais « quelle partie de ma stack doit rester sur du propriétaire ? ». Les réponses convergent vers un modèle hybride : propriétaire pour les agents critiques orientés client, open source hébergé en interne pour les traitements de données sensibles et les gros volumes.
La prochaine frontière : les modèles de raisonnement spécialisés
Au-delà des modèles généralistes comme V4 et GPT-5.5, 2026 voit émerger des modèles open source spécialisés — chimie computationnelle, génomique, droit, finance quantitative — qui surpassent les généralistes sur leurs domaines tout en étant bien plus économiques à l'usage. Cette tendance vers la spécialisation verticale va redéfinir les critères de choix des équipes techniques dans les 12 prochains mois. Pour les équipes qui automatisent leurs workflows avec des agents IA, cette pluralité de modèles spécialisés impose une capacité d'orchestration intelligente que les outils comme n8n permettent justement de construire.
Comment BOVO Digital peut vous aider
Chez BOVO Digital, nous accompagnons depuis plus de 4 ans des entreprises sur trois axes que cette guerre des modèles vient de bouleverser :
- Architecture IA multi-modèles : conception de stacks où DeepSeek V4, GPT-5.5, Claude et modèles open source sont routés intelligemment selon le cas d'usage. En savoir plus.
- Agents conversationnels et chatbots sur-mesure (WhatsApp, web, voix) avec sélection du modèle optimal pour chaque conversation. Découvrir notre offre.
- SaaS et applications IA-natives : développement Next.js + Flutter avec intégration profonde des modèles, déployées sur des projets référents comme MaxSEO AI et Illico Voice AI.
Nous publions un devis détaillé sous 24 heures après un appel de cadrage gratuit de 30 minutes.
Conclusion
La sortie simultanée de GPT-5.5 et DeepSeek V4 ne change pas l'IA — elle change votre rapport de force avec les fournisseurs IA. Pour la première fois, un modèle open source rivalise sérieusement au sommet, à un prix divisé, sur du matériel non-américain. Le bon réflexe en 2026 n'est pas de choisir un camp. C'est de construire une stack pluraliste, mesurer les coûts réels par cas d'usage, et garder la liberté de basculer quand le marché tournera à nouveau.
Les licences, les benchmarks et les architectures matérielles ne sont pas des détails techniques réservés aux équipes IA — ils définissent votre autonomie stratégique pour les trois prochaines années. Une dépendance à un fournisseur unique, c'est un risque business que les événements de 2026 ont rendu quantifiable et évitable.
Et il tournera. La prochaine bascule arrivera dans 3 à 6 mois — pas 18.
Discutons de votre stratégie IA 2026 ou consultez nos projets IA livrés.
Étiquettes
FAQ
DeepSeek V4 est-il vraiment meilleur que GPT-5.5 ?
Pas globalement. GPT-5.5 reste devant sur le tool-calling agentique, l'opération de logiciels (78,7 % sur OSWorld-Verified) et le browsing web. DeepSeek V4 rattrape sur les benchmarks de raisonnement (86-87 % MMLU-Pro), domine sur le rapport qualité-prix (1,74 $/M tokens contre plusieurs fois plus pour GPT-5.5), et sur la multimodalité native avec 1 million de tokens de contexte. La bonne stratégie est de les utiliser ensemble selon le cas d'usage.
Puis-je vraiment héberger DeepSeek V4 chez moi ?
Oui, les poids sont publiés sous licence MIT sur Hugging Face. Mais c'est un MoE 1,6 trillion de paramètres : prévoyez plusieurs serveurs GPU haut de gamme et une équipe MLOps. Pour la majorité des PME, l'API DeepSeek officielle reste plus rentable. L'auto-hébergement n'a de sens que sur des contraintes de souveraineté fortes (RGPD, données médicales, secret bancaire) ou sur des volumes très élevés.
Pourquoi DeepSeek tourne-t-il sur des puces Huawei plutôt que Nvidia ?
Pour deux raisons : contourner les restrictions d'export américaines sur les puces haut de gamme à destination de la Chine, et bâtir un écosystème logiciel + matériel autonome. Les puces Huawei Ascend 950PR offrent 2,8 fois la performance d'un Nvidia H20, à un prix d'environ 6 900 $. Alibaba, ByteDance et Tencent ont passé des commandes massives en anticipation.
Faut-il abandonner OpenAI et GPT-5.5 pour DeepSeek ?
Non. La bonne approche est une architecture multi-modèles : GPT-5.5 pour les agents critiques et le browsing, DeepSeek V4 pour les gros volumes et l'analyse documentaire, Claude Opus 4.7 pour le code, et des modèles open source plus petits pour les tâches simples à haut débit. Cette pluralité réduit la dépendance à un fournisseur et optimise le coût par cas d'usage.
Combien d'argent puis-je économiser en passant à DeepSeek V4 ?
Selon votre profil de consommation, entre 60 % et 85 % de votre facture API actuelle. À titre d'ordre de grandeur : V4-Pro à 1,74 $/3,48 $ par million de tokens contre Claude Opus 4.7 à 5 $/25 $ et des grilles GPT-5.5 dans la même fourchette haute. Pour une consommation d'1 milliard de tokens/mois, l'économie peut atteindre 15 000 à 25 000 € annuels.
Comment BOVO Digital aide à choisir et intégrer ces modèles ?
Nous concevons des architectures multi-modèles avec routage intelligent (n8n, LangGraph, orchestrateurs maison) qui aiguillent chaque requête vers le modèle le plus adapté en coût/qualité/sensibilité. Nous intégrons les modèles dans des SaaS Next.js, des apps Flutter, des chatbots WhatsApp et des automatisations Make/n8n. Démarrez avec un appel de cadrage gratuit via /agence-automatisation-n8n.
Quelle est la différence entre DeepSeek V4-Pro et V4-Flash ?
V4-Pro (1,6T paramètres, 49B activés) est conçu pour les tâches complexes nécessitant raisonnement profond et contexte long. V4-Flash (284B paramètres, 13B activés) cible les cas à haut volume et faible latence — idéal pour des chatbots, des classifications ou des résumés simples. Sur les benchmarks publics, V4-Pro performe sensiblement mieux sur les tâches de raisonnement.
L'IA open source est-elle aussi sécurisée que les modèles propriétaires ?
La réponse dépend de la définition de « sécurisé ». Les modèles open source permettent un audit complet du code et des poids — ce que les modèles propriétaires n'offrent pas. Mais ils requièrent que vous sécurisiez vous-même l'infrastructure d'hébergement. Un modèle propriétaire délègue cette responsabilité à son éditeur. Pour les données très sensibles, l'open source auto-hébergé sur infrastructure maîtrisée est souvent le choix le plus sûr.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
William Aklamavo
Expert en développement web et automatisation, passionné par l'innovation technologique et l'entrepreneuriat digital.


