
Tutoriel : Gemma 4 en Local avec Ollama + n8n — Votre Premier Agent IA 100% Gratuit et Privé
Vous payez des API OpenAI pour vos automatisations n8n. Chaque workflow coûte. Et vos données partent vers des serveurs externes. Avec Google Gemma 4 (Apache 2.0) + Ollama, vous faites tourner un LLM frontier-level gratuitement en local et vous le branchez à n8n en 20 minutes.

Mis à jour le

Mettre en place un agent IA local Gemma Ollama n8n, c'est se libérer en une seule installation de trois contraintes qui plombent la plupart des automatisations modernes : le coût des API, la dépendance à un fournisseur cloud, et la fuite de vos données vers des serveurs que vous ne contrôlez pas. Dans ce tutoriel, vous allez assembler un agent IA 100 % local, gratuit et privé en branchant le modèle Google Gemma 4 (servi par Ollama) à votre instance n8n. À la fin, vous disposerez d'un assistant capable de classer des emails, de répondre à des questions sur vos documents et d'orchestrer des workflows — sans qu'un seul octet ne quitte votre infrastructure.
Ce guide est volontairement complet : nous couvrons le pourquoi (coût, confidentialité, souveraineté), les prérequis matériels en ordres de grandeur, l'installation pas à pas, la connexion à n8n via le nœud AI Agent, deux cas d'usage concrets (classification d'emails et RAG local), puis les performances réelles, les limites face au cloud, la conformité RGPD et le dépannage des erreurs les plus fréquentes.
Pourquoi choisir un agent IA local plutôt que le cloud ?
Avant de taper la moindre commande, il faut comprendre ce qui rend un agent IA local Gemma Ollama n8n aussi intéressant. Trois raisons reviennent systématiquement chez nos clients.
Le coût d'abord. Une automatisation n8n qui appelle GPT-4o ou Claude paie chaque requête. Tant que vous êtes en phase de prototype, la facture reste discrète. Mais dès qu'un workflow traite des centaines d'emails par jour, classe des tickets en continu ou enrichit une base de données, les appels d'API se comptent en milliers — et la facture grimpe vite. Avec Gemma servi par Ollama, le coût d'inférence tombe à zéro : vous payez l'électricité et le matériel, point. Pour un volume élevé et répétitif, le calcul est souvent imbattable.
La confidentialité ensuite. Quand vous envoyez le contenu d'un email, d'un contrat ou d'un dossier client à une API externe, ces données transitent par un tiers. Même avec les meilleures garanties contractuelles, vous perdez le contrôle physique de l'information. Un agent IA local inverse complètement ce schéma : le texte est traité sur votre propre machine, et rien n'est jamais transmis à l'extérieur. Pour les secteurs sensibles — santé, juridique, finance, RH — cette différence n'est pas un détail, c'est un prérequis.
La souveraineté enfin. Dépendre d'une API cloud, c'est accepter ses changements de tarifs, ses limites de débit, ses dépréciations de modèles et ses interruptions de service. Un modèle open source comme Gemma 4, sous licence Apache 2.0, vous appartient une fois téléchargé. Il continuera de fonctionner exactement de la même façon dans deux ans, indépendamment des décisions d'un fournisseur. Vous maîtrisez votre stack de bout en bout.
Le 2 avril 2026, Google a lancé Gemma 4 sous licence Apache 2.0. Ce n'est ni un modèle de démonstration ni une version bridée : c'est un modèle de niveau frontier — comparable à Claude Haiku et GPT-4o mini — disponible en 4 tailles (2B, 8B, 16B, 31B) et utilisable gratuitement, localement, sans aucune donnée envoyée à l'extérieur.
Combiné à Ollama (le runtime de modèles locaux qui a explosé en popularité en 2025) et branché à n8n, ce setup vous donne :
- Zéro coût d'inférence — aucune API payante
- Confidentialité absolue — vos données ne quittent jamais votre machine
- Débit illimité — pas de rate limits, pas de quotas
- Tool use natif — Gemma 4 supporte nativement les appels d'outils (function calling) pour vos agents n8n
Voici le tutoriel pas à pas. Durée : 20 minutes si vous n'avez jamais installé Ollama.
Quels prérequis matériels pour faire tourner un agent IA local avec Gemma 4 et n8n ?
Nouveau avec les agents n8n ? Commencez par notre tutoriel sur la création de votre premier agent IA avant de passer aux modèles locaux.
La première question que tout le monde se pose : « Est-ce que ma machine est assez puissante ? » La réponse dépend de la taille du modèle que vous choisissez. Voici les ordres de grandeur à retenir, valables à la date de publication et susceptibles d'évoluer avec les futures quantifications d'Ollama.
Hardware minimum :
- Pour Gemma 4 2B : 8 GB de RAM (tourne même sur un ordinateur portable de 2022, sans carte graphique dédiée)
- Pour Gemma 4 8B : 16 GB de RAM ou une GPU dédiée (NVIDIA avec 8 GB de VRAM)
- Pour Gemma 4 16B et 31B : GPU dédiée recommandée (16-24 GB de VRAM)
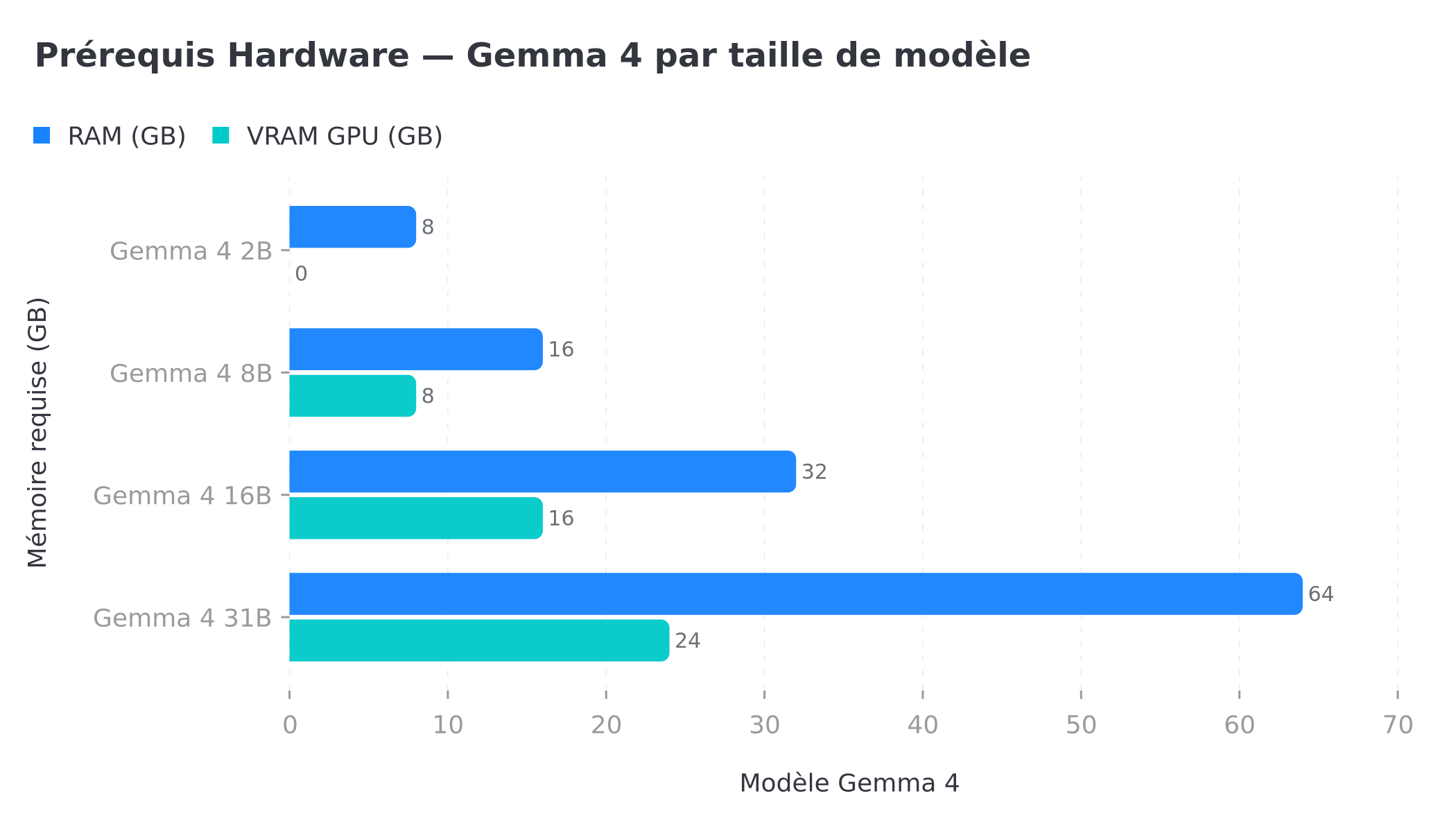 Prérequis hardware Gemma 4 : RAM et VRAM GPU nécessaires pour les versions 2B, 8B, 16B et 31B
Prérequis hardware Gemma 4 : RAM et VRAM GPU nécessaires pour les versions 2B, 8B, 16B et 31B
Concrètement, deux mécanismes expliquent ces chiffres. D'une part, un modèle doit être chargé intégralement en mémoire pour être exécuté : plus il a de paramètres, plus il occupe de RAM (ou de VRAM si vous l'exécutez sur GPU). D'autre part, Ollama applique une quantification — il compresse les poids du modèle (souvent en 4 bits) pour réduire son empreinte mémoire sans dégrader sensiblement la qualité. C'est grâce à cette quantification qu'un modèle de 8 milliards de paramètres peut tenir dans 16 GB de RAM.
Si vous travaillez uniquement sur CPU, restez sur la version 2B : elle reste fluide et suffit pour la majorité des tâches d'automatisation (classification, résumé, extraction). Dès que vous disposez d'une GPU NVIDIA récente, passez au 8B : le gain de qualité est net, et la vitesse devient confortable. Les versions 16B et 31B sont à réserver aux machines équipées d'une carte graphique professionnelle ou d'un GPU grand public haut de gamme.
Software :
- macOS, Linux ou Windows 10/11
- n8n installé localement ou en cloud (n8n.cloud, VPS avec Docker)
- 5 GB d'espace disque libre pour le modèle 2B (15 GB pour le 8B)
Si vous n'avez pas encore n8n, commencez par notre tutoriel pour créer votre premier agent IA avec n8n — il vous guide de l'installation à votre premier workflow. Et si vous prévoyez d'héberger l'ensemble sur votre propre serveur, notre guide d'installation de n8n auto-hébergé sur VPS détaille la configuration Docker idéale pour faire cohabiter n8n et Ollama.
Le parcours complet, de l'installation d'Ollama jusqu'au premier workflow connecté, suit toujours la même logique en cinq étapes. La voici résumée avant de plonger dans le détail.
 Les cinq étapes : installer Ollama, télécharger Gemma, tester le modèle, connecter n8n, lancer le premier workflow
Les cinq étapes : installer Ollama, télécharger Gemma, tester le modèle, connecter n8n, lancer le premier workflow
Étape 1 : Installer Ollama
Ollama est un runtime qui simplifie radicalement l'exécution de LLMs locaux. Il gère pour vous le téléchargement des modèles, leur quantification et l'exposition d'une API locale — vous n'avez aucune configuration bas niveau à faire. C'est exactement la brique qui transforme un modèle open source brut en service prêt à l'emploi pour votre agent IA local.
Sur macOS / Linux :
curl -fsSL https://ollama.com/install.sh | sh
Sur Windows : Téléchargez l'installeur depuis ollama.com et exécutez-le. Ollama s'installe comme un service Windows et démarre automatiquement en arrière-plan, écoutant sur le port 11434.
Vérifier l'installation :
ollama --version
# → ollama version 0.3.x ou supérieur
Une fois Ollama installé, un petit serveur tourne en permanence sur votre machine. C'est lui qui recevra les requêtes de n8n et renverra les réponses générées par Gemma. Vous pouvez à tout moment vérifier qu'il répond en ouvrant http://localhost:11434 dans un navigateur : vous devriez lire « Ollama is running ».
Étape 2 : Télécharger et choisir le bon modèle Gemma
# Version 2B — recommandée pour les machines sans GPU
ollama pull gemma4:2b
# Version 8B — meilleure qualité, nécessite 16 GB RAM ou GPU
ollama pull gemma4:8b
Le téléchargement prend 5 à 15 minutes selon votre connexion (2 à 5 GB selon la version). Ollama télécharge le modèle une seule fois, le stocke localement, puis le réutilise pour toutes les requêtes suivantes — y compris hors ligne.
Comment choisir la bonne taille ? Partez du cas d'usage, pas de la fiche technique. Pour du triage d'emails, de la classification de tickets, de l'extraction de champs ou du résumé court, la version 2B suffit largement et reste rapide même sur CPU. Pour des tâches qui demandent plus de finesse — rédaction de réponses nuancées, raisonnement sur plusieurs critères, compréhension de documents techniques — le 8B apporte un vrai saut qualitatif. Notre recommandation : commencez avec le 2B pour valider votre workflow, puis basculez sur le 8B uniquement si la qualité l'exige. Changer de modèle dans n8n se résume à modifier une seule ligne.
Vous pouvez lister à tout moment les modèles installés avec ollama list, et libérer de l'espace disque en supprimant ceux dont vous ne vous servez plus avec ollama rm <modèle>.
Étape 3 : Tester Gemma 4 en local
Avant de l'intégrer dans n8n, vérifiez que le modèle fonctionne correctement en discutant directement avec lui :
ollama run gemma4:2b
Vous entrez dans un chat interactif. Tapez quelques questions pour évaluer la qualité et la vitesse des réponses sur votre machine. C'est aussi le moment de vérifier que la latence est acceptable pour votre cas d'usage. Pour quitter : /bye
Test de tool use (function calling) : le function calling est ce qui transforme un simple modèle de chat en véritable agent. Au lieu de répondre uniquement en texte, Gemma peut décider d'appeler un outil (une fonction) avec des paramètres structurés. Vérifions que cela fonctionne :
curl http://localhost:11434/api/chat -d '{
"model": "gemma4:2b",
"messages": [{ "role": "user", "content": "Quel temps fait-il à Paris ?" }],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtient la météo pour une ville",
"parameters": {
"type": "object",
"properties": { "city": { "type": "string" } },
"required": ["city"]
}
}
}]
}'
Gemma 4 doit retourner un appel d'outil structuré (avec name: "get_weather" et city: "Paris") — preuve que le function calling fonctionne. C'est précisément ce mécanisme que le nœud AI Agent de n8n exploitera pour donner à votre agent local l'accès à des outils : recherche web, base de données, envoi d'email, etc.
Comment connecter Ollama à n8n ? (Étape 4)
Ollama expose une API REST compatible avec celle d'OpenAI sur http://localhost:11434. C'est ce qui rend l'intégration si simple : n8n croit parler à OpenAI, alors qu'en réalité tout reste local. Trois approches sont possibles selon votre installation.
Si n8n tourne en local (même machine qu'Ollama) :
Dans votre workflow n8n, ajoutez un nœud HTTP Request avec la configuration suivante :
- Method : POST
- URL :
http://localhost:11434/api/chat - Body (JSON) :
{
"model": "gemma4:2b",
"messages": [
{ "role": "system", "content": "Tu es un assistant utile et précis." },
{ "role": "user", "content": "{{ $json.message }}" }
],
"stream": false
}
Si n8n tourne dans le cloud ou sur un VPS :
Vous devez exposer Ollama sur le réseau. Sur le serveur hébergeant Ollama :
# Lancer Ollama en exposant sur toutes les interfaces
OLLAMA_HOST=0.0.0.0:11434 ollama serve
Puis dans n8n, remplacez localhost par l'IP de votre serveur Ollama. Attention : exposer Ollama sur le réseau sans protection est risqué. En production, placez-le toujours derrière un reverse proxy (Nginx, Caddy, Traefik) avec authentification, ou limitez l'accès à votre réseau privé. Si n8n et Ollama tournent sur le même VPS via Docker, le plus propre reste de les faire communiquer sur le réseau interne Docker sans rien exposer publiquement.
Approche recommandée — le nœud AI Agent avec un modèle compatible OpenAI :
C'est l'option la plus puissante. n8n intègre un nœud « AI Agent » qui orchestre raisonnement, mémoire et appels d'outils. Branchez-y un sous-nœud « Chat Model (OpenAI) » pointant vers Ollama. Configurez une credential « OpenAI API » avec :
- Base URL :
http://localhost:11434/v1 - API Key :
ollama(n'importe quelle valeur, Ollama n'en requiert pas) - Model :
gemma4:2b
Avec cette configuration, vous bénéficiez de toute la machinerie d'agent de n8n — chaînage d'outils, mémoire de conversation, sorties structurées — tout en gardant l'inférence 100 % locale. Pour aller plus loin et donner à votre agent l'accès à des outils externes via le protocole MCP, consultez notre guide pour connecter n8n à un serveur MCP.
Comprendre l'architecture d'un agent IA local
Avant de construire votre premier workflow, prenons un instant pour visualiser comment les pièces s'assemblent. C'est cette image mentale qui vous permettra de déboguer sereinement plus tard.
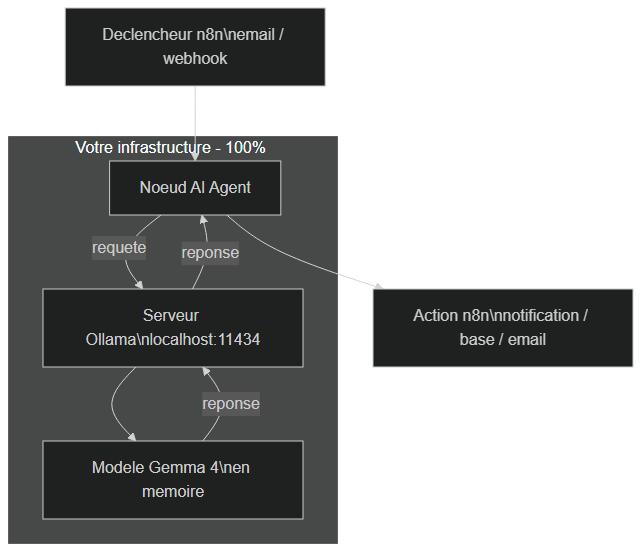 Architecture locale : déclencheur n8n → nœud AI Agent → API Ollama → modèle Gemma 4, sans aucune sortie réseau externe
Architecture locale : déclencheur n8n → nœud AI Agent → API Ollama → modèle Gemma 4, sans aucune sortie réseau externe
Le schéma est volontairement simple, et c'est tout l'intérêt. Un déclencheur (un nouvel email, un webhook, une planification) lance le workflow dans n8n. Le nœud AI Agent formule une requête et l'envoie au serveur Ollama, qui exécute le modèle Gemma 4 chargé en mémoire. La réponse remonte exactement par le même chemin, puis n8n poursuit son workflow : notification, écriture en base, envoi d'email, etc.
Le point crucial : la flèche qui sortirait vers un cloud externe n'existe pas. Là où une architecture classique enverrait vos données à l'API d'OpenAI, ici tout le traitement reste confiné dans votre périmètre. C'est exactement ce qui fait la valeur d'un agent IA local pour les données sensibles.
Étape 5 : Premier workflow agent — classer ses emails
Voici un exemple concret et immédiatement utile : un agent qui résume les emails entrants et les classe par priorité, entièrement en local.
Structure du workflow :
- Trigger : Gmail / IMAP — déclenché à chaque nouvel email
- HTTP Request → Ollama/Gemma 4 avec le prompt :
"Analyse cet email et retourne un JSON avec: {sujet: string, priorité: 'haute'|'moyenne'|'basse', résumé: string (max 2 phrases), action_requise: boolean}. Email : {{ $json.body }}" - JSON Parse → Extrait les champs du JSON retourné
- Switch → Branche sur la priorité
- Slack / Email → Notification pour les emails haute priorité uniquement
Ce workflow tourne en local, classe vos emails sans qu'une seule donnée parte vers OpenAI, et coûte 0 €/mois.
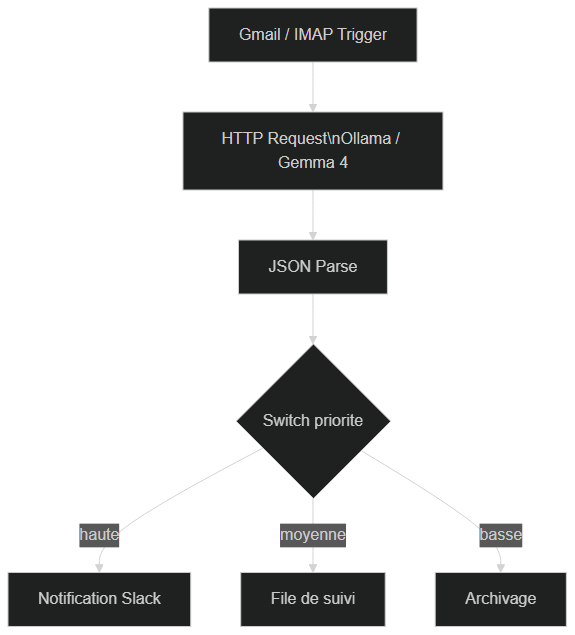 Workflow n8n : Gmail Trigger → Ollama/Gemma 4 → JSON Parse → Switch priorité → notifications Slack ou archivage
Workflow n8n : Gmail Trigger → Ollama/Gemma 4 → JSON Parse → Switch priorité → notifications Slack ou archivage
Pour bien comprendre ce qui se passe à l'exécution, voici la séquence des échanges entre les composants, étape par étape, pour un seul email traité.
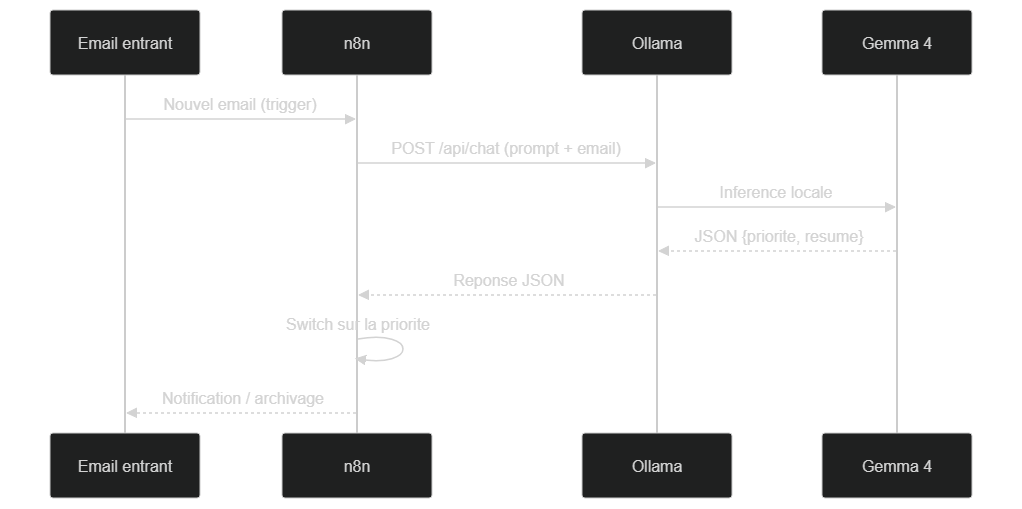 Diagramme de séquence : n8n envoie le prompt à Ollama, Gemma génère le JSON, n8n route selon la priorité — le tout en local
Diagramme de séquence : n8n envoie le prompt à Ollama, Gemma génère le JSON, n8n route selon la priorité — le tout en local
Ce patron est généralisable à une multitude de cas : tri de tickets de support, qualification de leads entrants, extraction d'informations depuis des formulaires, modération de commentaires. Le principe reste identique — un déclencheur, un appel à Gemma pour la partie « intelligence », puis une logique de routage classique dans n8n. Pour explorer des scénarios plus avancés, ce patron se combinerait très bien avec un serveur MCP connecté à n8n pour étendre les capacités de l'agent.
Aller plus loin : un RAG 100 % local sur vos documents
Le cas d'usage qui justifie à lui seul le passage au local, c'est le RAG (Retrieval-Augmented Generation) : permettre à votre agent de répondre à partir de vos documents internes — contrats, procédures, base de connaissances — sans jamais les envoyer dans le cloud.
Le principe est le suivant. Vous découpez vos documents en petits morceaux (chunks), vous les convertissez en vecteurs grâce à un modèle d'embeddings (Ollama sait aussi servir des modèles d'embeddings, là encore en local), puis vous les stockez dans une base vectorielle. Quand une question arrive, n8n recherche les passages les plus pertinents, les injecte dans le prompt de Gemma, et le modèle formule une réponse ancrée dans vos données réelles plutôt que dans ses connaissances générales.
Voici le squelette d'un workflow RAG local dans n8n (exemple simplifié) :
1. Ingestion (une fois) : Lire les documents → découper en chunks →
embeddings via Ollama → stocker dans une base vectorielle
2. Requête (à la demande) : Question utilisateur → embedding de la question →
recherche des chunks proches → injection dans le prompt →
génération de la réponse par Gemma 4
Pour une PME qui manipule des documents confidentiels, ce schéma est radicalement différent d'une solution cloud : la base de connaissances reste sur votre serveur, les embeddings sont calculés en local, et la génération aussi. Aucun maillon de la chaîne ne fuit à l'extérieur. C'est le genre d'architecture que nous mettons en place pour des clients qui ne peuvent tout simplement pas, pour des raisons légales ou contractuelles, confier leurs documents à un tiers.
Performances et limites : local vs cloud
Soyons honnêtes : le local n'est pas magique, et il ne remplace pas le cloud dans tous les cas. Voici ce qu'il faut savoir pour décider en connaissance de cause.
Ce que Gemma 4 2B fait bien :
- Classification, résumé, extraction d'informations structurées
- Réponses dans plus de 20 langues (support de 140 langues)
- Raisonnement sur des contextes longs (jusqu'à 250 000 tokens)
Ce que Gemma 4 2B fait moins bien :
- Raisonnement mathématique complexe (préférez le 8B ou le 16B)
- Code complexe multi-fichiers (le 8B est nettement meilleur)
- Vitesse : de l'ordre de 15 à 30 tokens/seconde sur CPU, et de 80 à 150 tokens/seconde sur GPU récente (ordres de grandeur, variables selon le matériel)
La vraie question n'est pas « local ou cloud ? » mais « local et cloud, selon le besoin ». Le graphique ci-dessous résume les arbitrages typiques entre une stack locale et une stack cloud sur les critères qui comptent le plus — à lire comme une tendance illustrative, pas comme un benchmark chiffré.
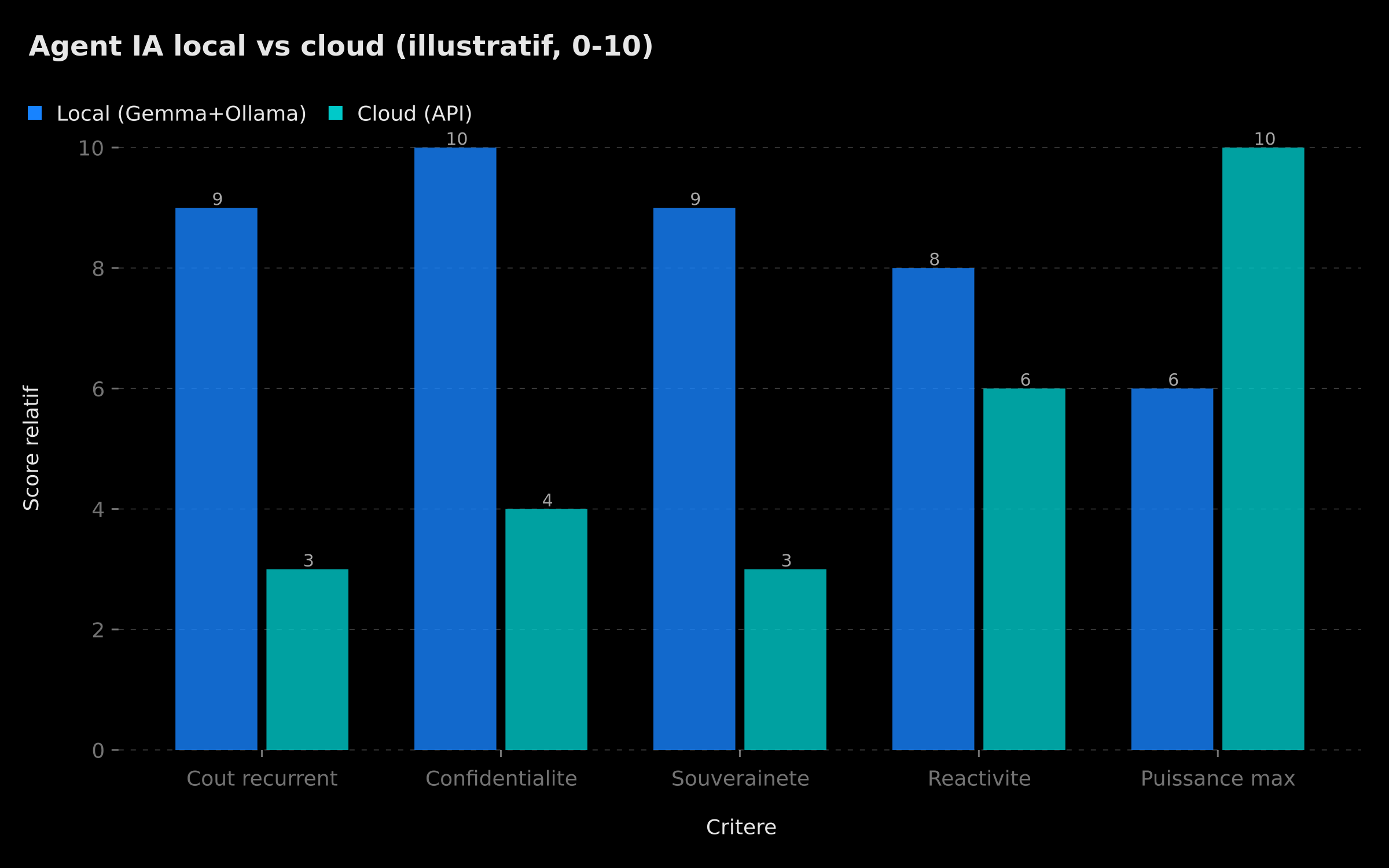 Comparaison local vs cloud : le local domine sur le coût récurrent et la confidentialité, le cloud sur la puissance de raisonnement maximale
Comparaison local vs cloud : le local domine sur le coût récurrent et la confidentialité, le cloud sur la puissance de raisonnement maximale
Pour la production : Gemma 4 2B est parfait pour le prototypage et les cas d'usage simples à moyens. Pour des agents en production avec des volumes élevés ou des cas complexes, nous recommandons soit le modèle 8B sur GPU, soit une architecture hybride locale + cloud : le local traite la masse des requêtes courantes et sensibles, et le cloud n'est sollicité que pour les rares cas qui exigent un raisonnement de pointe. C'est ce type d'architecture équilibrée que nous concevons régulièrement chez BOVO Digital.
Confidentialité et RGPD : pourquoi le local est imbattable
Pour une entreprise européenne, l'argument confidentialité dépasse largement la simple précaution : il touche directement à la conformité réglementaire. Lorsque vous envoyez des données personnelles à une API cloud, vous déclenchez tout un appareillage juridique — sous-traitance, clauses contractuelles, et souvent un transfert hors de l'Union européenne à encadrer.
Un agent IA local Gemma Ollama n8n court-circuite tout cela. Puisque l'inférence se déroule sur votre propre machine ou votre propre serveur, aucune donnée personnelle n'est transmise à un tiers. Vous restez seul responsable de traitement, il n'y a pas de sous-traitant IA à auditer, et la question du transfert international ne se pose tout simplement pas. Pour un délégué à la protection des données, cette simplification est considérable.
Cela ne vous dispense évidemment pas de vos autres obligations : minimisation des données, durée de conservation, sécurité du serveur, journalisation des accès. Mais vous éliminez d'emblée le maillon le plus délicat — l'exfiltration de données vers un service externe. Pour les secteurs où la confidentialité est non négociable (santé, droit, RH, finance), c'est souvent ce qui fait la différence entre « projet IA bloqué par le juridique » et « projet IA validé ».
Dépannage : les erreurs les plus fréquentes
Quelques problèmes reviennent régulièrement lors de la mise en place. Voici comment les diagnostiquer rapidement.
« Connection refused » depuis n8n. Le symptôme le plus courant. Il signifie qu'Ollama ne reçoit pas la requête. Vérifiez d'abord qu'Ollama tourne (ollama list doit répondre). Si n8n est dans un conteneur Docker, localhost ne pointe pas vers votre machine hôte mais vers le conteneur lui-même : utilisez http://host.docker.internal:11434 (macOS/Windows) ou l'IP de la passerelle Docker (Linux) à la place.
Le modèle répond très lentement. Si vous êtes sur CPU avec un modèle 8B, la lenteur est normale — repassez sur le 2B ou ajoutez une GPU. Vérifiez aussi qu'aucune autre application ne sature votre RAM : si le modèle ne tient plus en mémoire, le système se met à utiliser le disque (swap) et les performances s'effondrent.
Le function calling ne renvoie pas de JSON propre. Les petits modèles sont sensibles à la formulation du prompt. Soyez explicite : demandez « réponds uniquement avec un objet JSON valide, sans texte avant ni après ». Activez si possible le mode « JSON » d'Ollama ("format": "json") pour forcer une sortie structurée, et ajoutez un nœud de validation dans n8n pour gérer les rares cas mal formés.
Ollama n'est pas joignable depuis un autre serveur. Par défaut, Ollama n'écoute que sur localhost. Pour l'exposer, démarrez-le avec OLLAMA_HOST=0.0.0.0:11434 — mais uniquement derrière un pare-feu ou un reverse proxy authentifié, jamais en accès public direct.
De la démo à la production
Ce setup est idéal pour prototyper rapidement sans budget. Quand vous avez validé votre cas d'usage et que vous voulez passer à l'échelle — avec de la haute disponibilité, de la mémoire persistante, du RAG sur vos documents, et un monitoring —, c'est là qu'une architecture de production entre en jeu.
Lisez notre article sur n8n vs Make pour comprendre comment choisir votre stack d'automatisation selon votre volume et votre contexte. Et pour transformer un workflow isolé en véritable système intelligent, notre guide n8n AI Agent : transformez vos workflows en systèmes intelligents montre comment industrialiser l'approche.
Vous avez validé votre cas d'usage en local et vous voulez passer en production ?
Découvrez nos services d'automatisation IA et agents intelligents — et le profil de William Aklamavo qui livre ces architectures en production.
Étiquettes
FAQ
Quel hardware est nécessaire pour faire tourner Gemma 4 en local ?
Gemma 4 2B nécessite 8 GB de RAM et tourne sur n'importe quel ordinateur portable récent sans GPU. Gemma 4 8B requiert 16 GB de RAM ou une GPU NVIDIA de 8 GB VRAM. Les versions 16B et 31B nécessitent une GPU dédiée de 16-24 GB VRAM pour une performance acceptable.
Gemma 4 supporte-t-il les appels d'outils (function calling) pour les agents n8n ?
Oui. Gemma 4 intègre le tool use natif dès sa version 2B. Dans n8n, vous pouvez utiliser le nœud 'AI Agent' avec les outils intégrés (recherche web, base de données, email) en pointant vers l'API Ollama locale, exactement comme avec l'API OpenAI.
Puis-je utiliser Ollama avec n8n Cloud ou un VPS ?
Oui. Il faut démarrer Ollama avec OLLAMA_HOST=0.0.0.0:11434 pour l'exposer sur le réseau, puis utiliser l'IP du serveur dans la configuration n8n. Pour la sécurité en production, mettez Ollama derrière un reverse proxy avec authentification.
Gemma 4 est-il comparable à GPT-4o pour les cas d'usage d'automatisation ?
Gemma 4 8B est comparable à GPT-4o mini sur les tâches de classification, résumé, extraction d'information et tool use. Pour le raisonnement complexe et le code avancé, GPT-4o et Claude Sonnet restent supérieurs. Pour 80% des cas d'usage d'automatisation (triage, résumé, classification), Gemma 4 8B est suffisant.
La licence Apache 2.0 de Gemma 4 permet-elle une utilisation commerciale ?
Oui, la licence Apache 2.0 autorise l'utilisation commerciale, la modification et la distribution, y compris dans des produits commerciaux et des services SaaS. Vous pouvez intégrer Gemma 4 dans vos agents de production sans royalties ni restrictions commerciales.
Un agent IA local Gemma Ollama n8n est-il vraiment conforme au RGPD ?
Oui, et c'est même l'un de ses plus gros avantages. Comme l'inférence se fait sur votre propre machine ou votre propre serveur, aucune donnée personnelle n'est transférée vers un sous-traitant tiers ni hors de l'UE. Vous restez seul responsable de traitement, sans transfert international à encadrer, ce qui simplifie radicalement votre conformité.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
William Aklamavo
Expert en développement web et automatisation, passionné par l'innovation technologique et l'entrepreneuriat digital.


