
Tutoriel n8n Agent IA 2026 : Création et Déploiement Sécurisé (B2B)
Comment créer un agent IA dans n8n en 2026 ? Ce guide complet explique l'architecture ReAct, les 5 composants clés, et vous guide étape par étape pour construire votre premier agent autonome avec mémoire et outils.

Mis à jour le

Pourquoi ce tutoriel n8n agent IA 2026 est différent
Ce tutoriel n8n agent IA 2026 ne se contente pas de vous montrer comment relier trois nœuds dans une interface. Il vous donne l'architecture complète, les décisions de configuration qui font la différence entre un agent fragile et un agent en production, et les pièges que chaque débutant rencontre sans jamais comprendre pourquoi son agent se comporte de manière erratique. L'automatisation classique fonctionne en ligne droite : si condition A → action B. C'est puissant, mais limité. Un agent IA n8n fonctionne différemment : il raisonne, décide et agit en boucle jusqu'à atteindre un objectif, en s'adaptant à chaque réponse intermédiaire qu'il reçoit de ses outils.
Concrètement : au lieu d'un workflow qui envoie un email quand un formulaire est rempli, un agent n8n peut qualifier un lead, chercher des informations sur son entreprise, personnaliser un email, et décider s'il faut contacter par email ou WhatsApp — tout seul, sans que vous ayez programmé chaque cas de figure. En 2026, avec l'accès aux LLM puissants comme GPT-4o, Claude 3.5, ou même Gemma 4 en local avec Ollama, la barrière technique s'est effondrée. Ce guide vous donne tout ce qu'il faut pour passer de zéro à un agent opérationnel. Pour aller plus loin sur la vision stratégique, consultez également notre article sur comment les agents IA transforment vos workflows en systèmes intelligents.
Pratiques DevSecOps : Sécuriser vos agents en entreprise
Le déploiement d'un agent IA en environnement B2B ne s'improvise pas. Au-delà du fonctionnement technique, vous devez garantir la confidentialité des données (PII), la robustesse contre les injections de prompts et la haute disponibilité. Chez BOVO Digital, nous appliquons une méthodologie rigoureuse basée sur le chiffrement des credentials au repos, l'isolation réseau des conteneurs et une stratégie stricte de "Human-in-the-loop" pour les actions sensibles (envoi de factures, modification de base de données).
Besoin d'un audit de sécurité pour vos déploiements IA ? Nos experts analysent vos workflows n8n, vérifient la gestion des secrets et optimisent vos architectures ReAct pour garantir une conformité totale avec les standards de votre industrie. Réservez dès maintenant votre audit stratégique avec BOVO Digital.
Prérequis et Installation : Ce Qu'il Faut Avant de Commencer
Avant d'ouvrir n8n, vérifiez que vous disposez de l'environnement minimal. Sur le plan logiciel, n8n nécessite Node.js 18 ou supérieur si vous choisissez l'installation native, mais la méthode la plus robuste — et celle que nous recommandons en 2026 — est Docker. Un simple docker compose up -d lance n8n et PostgreSQL en quelques secondes, sans conflit de dépendances. Si vous partez de zéro, notre guide dédié à l'installation de n8n avec Docker en 2026 couvre l'intégralité du processus, du choix du VPS à la configuration du reverse proxy HTTPS.
Sur le plan des accès, préparez au minimum une clé API OpenAI (depuis platform.openai.com) ou Anthropic (console.anthropic.com) selon le LLM que vous comptez utiliser. Si vous optez pour un modèle local avec Ollama, assurez-vous que le service tourne sur votre machine ou votre serveur avant de configurer le nœud n8n correspondant. Enfin, réfléchissez dès maintenant à l'objectif de votre agent : quel problème doit-il résoudre ? Quelles données doit-il consulter ? Quelles actions doit-il exécuter ? Une heure de réflexion sur ce périmètre avant de toucher l'interface vous économisera plusieurs heures de debugging improductif.
En termes de ressources serveur, un VPS avec 2 vCPU et 4 Go de RAM est suffisant pour un agent en production gérant jusqu'à quelques centaines d'exécutions par jour. Pour des volumes plus importants ou des architectures multi-agents, prévoyez 4 vCPU et 8 Go de RAM, avec PostgreSQL sur un volume SSD dédié.
L'Architecture d'un Agent n8n : 5 Composants Essentiels
Avant de cliquer dans n8n, comprenez la structure. Tout agent n8n est composé de 5 blocs, et la façon dont vous les configurez détermine à 80% la qualité du comportement final de votre agent.
1. Le Déclencheur (Trigger)
C'est ce qui lance l'agent. Trois options courantes :
- Chat Trigger : l'utilisateur envoie un message (chatbot)
- Webhook : un événement externe déclenche l'agent (formulaire, Stripe, CRM)
- Schedule : l'agent tourne automatiquement à heure fixe (toutes les 30 min, chaque nuit)
2. Le Nœud AI Agent
C'est le cerveau. Il reçoit un objectif, consulte ses outils, et décide quoi faire. Le type Tools Agent couvre 90% des cas d'usage — il utilise la boucle ReAct (Reason + Act) : réfléchir → agir → observer → recommencer.
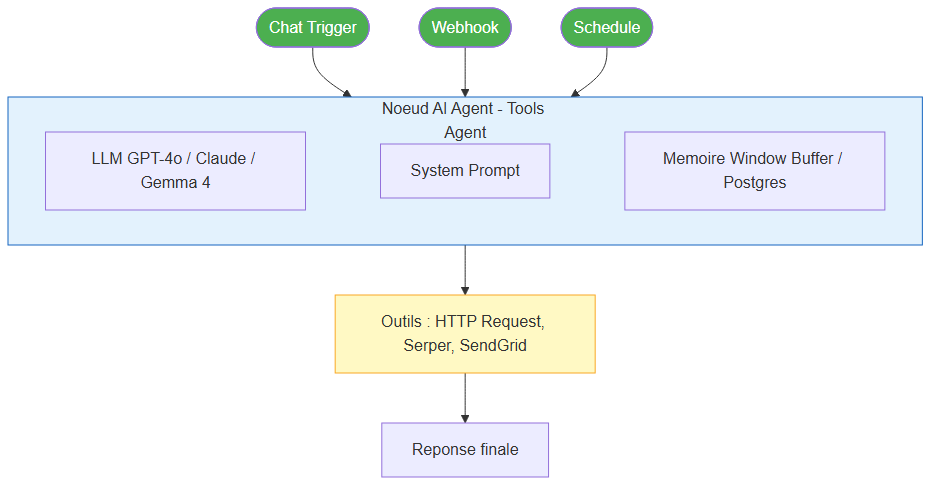 Les 5 blocs essentiels d'un agent n8n : déclencheur, nœud AI Agent, modèle de langage, outils et mémoire
Les 5 blocs essentiels d'un agent n8n : déclencheur, nœud AI Agent, modèle de langage, outils et mémoire
3. Le Modèle de Langage (Chat Model)
Le LLM qui alimente la réflexion de l'agent. Les choix recommandés en 2026 :
- GPT-4o : meilleur équilibre performance/coût pour la production
- Claude 3.5 Sonnet : excellent pour les tâches de rédaction et d'analyse
- Gemma 4 via Ollama : gratuit, local, aucune donnée externe — idéal pour les données sensibles
4. Les Outils (Tools)
Ce sont les actions que l'agent peut exécuter. Exemples :
- Recherche web (Serper, Brave Search)
- Requête HTTP vers une API externe (votre CRM, Notion, Airtable)
- Envoi d'email ou de message WhatsApp
- Lecture/écriture en base de données
- Exécution de code JavaScript ou Python
5. La Mémoire (Memory)
Sans mémoire, chaque message repart de zéro. Deux options principales :
- Window Buffer Memory : conserve les N derniers messages (session unique)
- Postgres Chat Memory : persistance complète entre sessions (chatbot avec historique long)
Le diagramme ci-dessous illustre comment ces 5 composants interagissent lors d'une requête réelle, depuis le déclenchement jusqu'à la réponse finale :
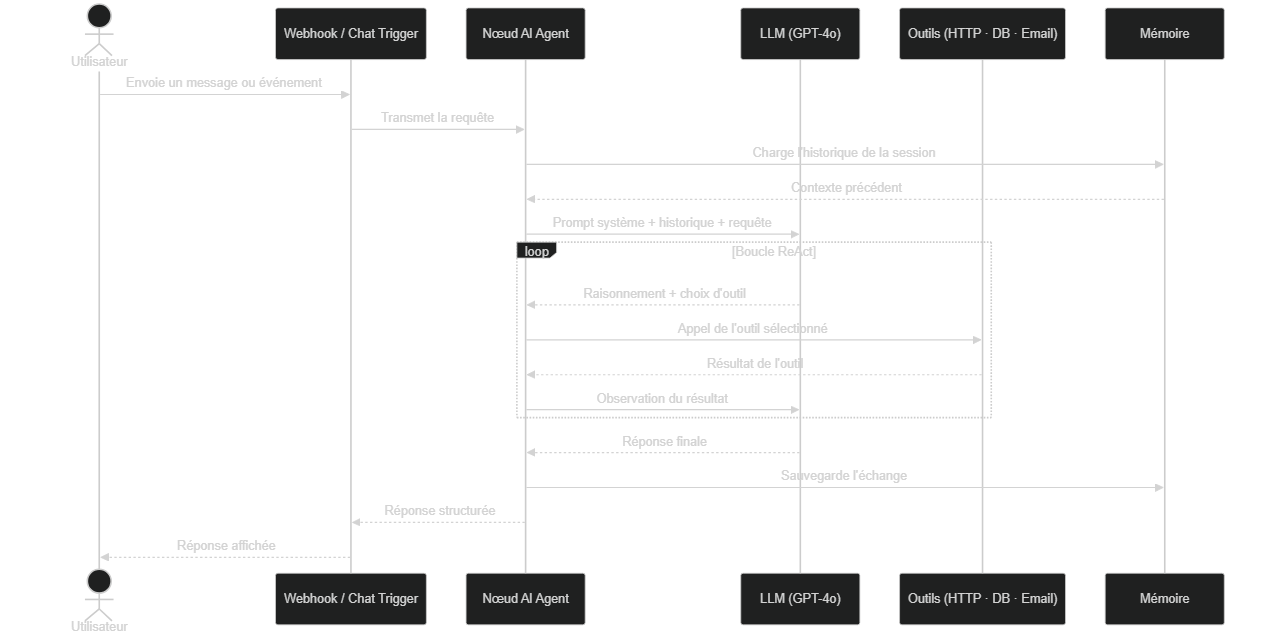 Séquence complète : l'utilisateur envoie un message, l'agent charge la mémoire, interroge le LLM, appelle ses outils en boucle ReAct puis retourne une réponse structurée
Séquence complète : l'utilisateur envoie un message, l'agent charge la mémoire, interroge le LLM, appelle ses outils en boucle ReAct puis retourne une réponse structurée
Tutoriel Pas à Pas : Votre Premier Agent n8n
Le schéma ci-dessous résume les 8 étapes du tutoriel. Nous les détaillons ensuite une par une, sans sauter d'étape.
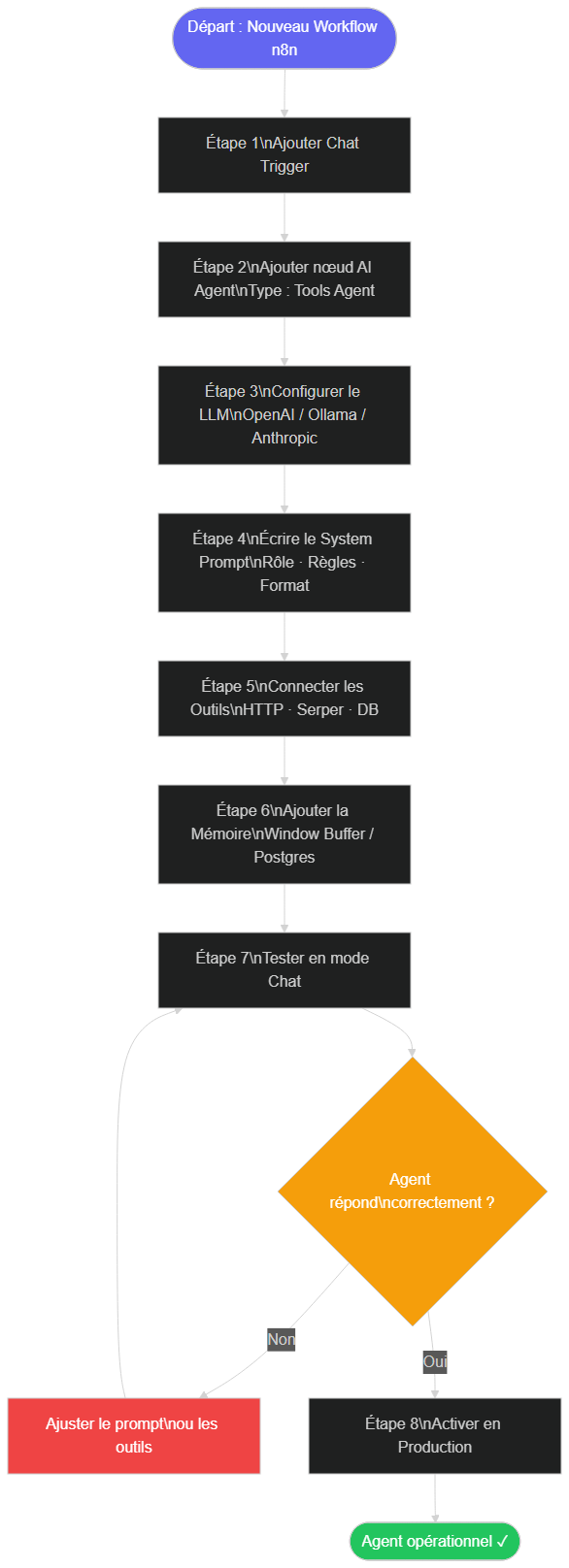 Les 8 étapes du tutoriel n8n agent IA 2026 : Trigger → AI Agent → LLM → System Prompt → Tools → Mémoire → Test → Production
Les 8 étapes du tutoriel n8n agent IA 2026 : Trigger → AI Agent → LLM → System Prompt → Tools → Mémoire → Test → Production
Étape 1 — Créer le workflow et choisir le déclencheur
- Dans n8n, créez un nouveau workflow
- Ajoutez un nœud Chat Trigger (icône bulle de conversation)
- Activez "Make Chat Publicly Available" pour avoir une URL de test
Étape 2 — Ajouter le nœud AI Agent
- Cliquez sur le "+" → cherchez "AI Agent"
- Choisissez Tools Agent (le plus polyvalent)
- Connectez-le au Chat Trigger
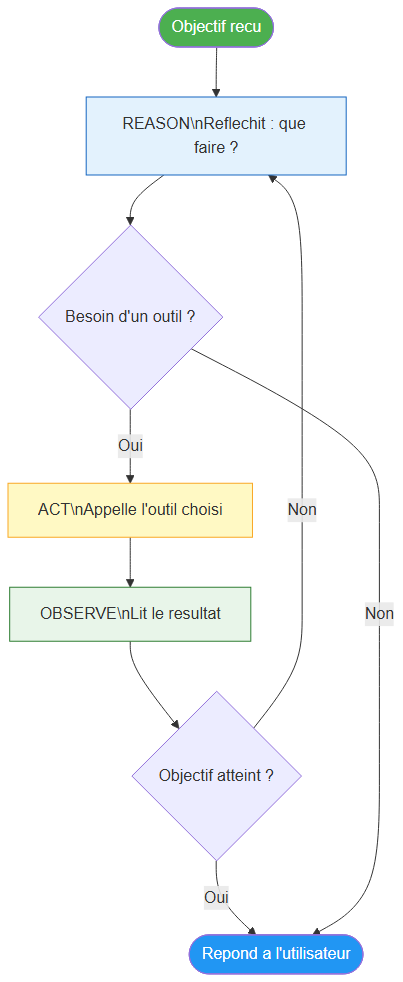 La boucle ReAct : l'agent raisonne, appelle un outil, observe le résultat et recommence jusqu'à répondre à l'objectif
La boucle ReAct : l'agent raisonne, appelle un outil, observe le résultat et recommence jusqu'à répondre à l'objectif
Étape 3 — Configurer le LLM
- Dans le nœud AI Agent, section "Chat Model" → cliquez "+"
- Sélectionnez OpenAI Chat Model (ou Ollama si vous voulez du local)
- Créez vos credentials OpenAI (clé API depuis platform.openai.com)
- Choisissez le modèle :
gpt-4o-minipour les tests,gpt-4opour la production
Étape 4 — Écrire le System Prompt
C'est l'étape que 80% des débutants bâclent. Un bon system prompt définit :
- Le rôle : "Tu es un assistant commercial pour BOVO Digital..."
- Les capacités : "Tu peux chercher des informations sur les entreprises..."
- Les règles : "Réponds toujours en français. Ne promets jamais de délais non confirmés."
- Le format : "Structure tes réponses avec des listes quand tu listes plus de 3 éléments."
Étape 5 — Connecter les outils
Pour un agent de recherche d'entreprises, ajoutez :
- Cliquez "+" sur la section Tools de l'AI Agent
- Ajoutez HTTP Request → configurez-le pour interroger l'API Clearbit ou Pappers
- Donnez un nom descriptif à l'outil : "rechercher_entreprise" (l'agent l'utilisera par son nom)
- Ajoutez une description claire : "Utilise cet outil pour obtenir des informations sur une entreprise à partir de son nom ou SIREN"
Étape 6 — Ajouter la mémoire
- Cliquez "+" sur la section Memory de l'AI Agent
- Sélectionnez Window Buffer Memory
- Configurez "Context Window Length" à 10 (conserve les 10 derniers échanges)
Étape 7 — Tester
- Cliquez "Test Workflow" dans n8n
- Une fenêtre de chat s'ouvre — envoyez un message de test
- Observez les logs : vous verrez l'agent raisonner, appeler ses outils, et répondre
Configuration Avancée du LLM : Paramètres qui Font la Différence
La sélection du modèle n'est que le début. Dans le nœud Chat Model de n8n, plusieurs paramètres avancés influencent directement la qualité des réponses de votre agent. Le paramètre temperature contrôle la créativité du modèle : une valeur de 0 à 0.2 convient aux agents qui doivent être factuels et prévisibles (extraction de données, classification, résumé structuré), tandis qu'une valeur entre 0.5 et 0.8 est préférable pour les agents conversationnels ou créatifs. Ne montez jamais au-dessus de 1.0 pour un agent en production — les réponses deviennent trop imprévisibles.
Le paramètre max_tokens (ou max_completion_tokens selon les versions de l'API) plafonne la longueur des réponses. Pour un agent de qualification de leads qui génère des emails courts, 512 tokens est largement suffisant. Pour un agent d'analyse de documents, prévoyez 2048 tokens ou plus. Attention : chaque token consommé en sortie se facture ; calibrez ce paramètre pour éviter les surcoûts inutiles.
En 2026, la configuration que nous déployons le plus souvent chez nos clients repose sur GPT-4o avec temperature: 0.2 pour les agents B2B qui traitent des données structurées, et Claude 3.5 Sonnet avec temperature: 0.4 pour les agents orientés contenu et communication. Pour les environnements où la confidentialité des données est critique — santé, juridique, finance — nous recommandons systématiquement Gemma 4 via Ollama, qui tourne entièrement sur votre infrastructure sans aucune donnée transitant par des serveurs tiers. Le choix du LLM a plus d'impact sur le comportement de l'agent que n'importe quel autre paramètre de configuration.
Voici un exemple simplifié de configuration JSON pour l'outil HTTP Request d'un agent qui appelle une API externe :
{
"method": "GET",
"url": "https://api.pappers.fr/v2/entreprise",
"authentication": "headerAuth",
"headers": {
"api_token": "={{ $env.PAPPERS_API_KEY }}"
},
"qs": {
"siret": "={{ $json.siret }}"
},
"options": {
"timeout": 10000
}
}
Notez l'utilisation de $env.PAPPERS_API_KEY : ne jamais coder en dur une clé API dans un nœud n8n. Stockez toutes les clés dans les variables d'environnement n8n (Settings → Variables) ou dans les credentials natifs.
Définition Précise des Outils : La Clé d'un Agent Efficace
Un aspect systématiquement sous-estimé par les débutants est la définition des outils. Le LLM n'interagit pas directement avec vos APIs — il lit les noms et les descriptions de chaque outil, et décide lequel appeler en fonction de ces informations. Une description vague ou ambiguë entraîne des appels d'outils incorrects, des hallucinations ou des boucles infinies.
Chaque outil doit répondre à trois questions dans sa description : quand l'utiliser, quelles données il reçoit en entrée, et quel type de résultat il retourne. Par exemple, au lieu de décrire un outil comme "Recherche d'informations", écrivez : "Utilise cet outil pour obtenir les informations légales et financières d'une entreprise française à partir de son numéro SIRET ou SIREN. Retourne le nom, l'adresse, le chiffre d'affaires annuel, l'effectif et le code NAF." Cette précision réduit drastiquement les erreurs de l'agent.
Pour les agents avancés, n8n permet d'utiliser un sous-workflow comme outil : vous créez un workflow n8n séparé, configuré comme outil via le nœud "Execute Workflow", et votre agent peut l'appeler comme n'importe quel autre outil. Cette architecture permet de modulariser des logiques complexes — par exemple, un outil d'envoi d'email qui inclut en interne la gestion des erreurs, les relances et le logging — sans alourdir le workflow principal de l'agent. Nous développons cette architecture en profondeur dans notre tutoriel sur la création d'un premier agent IA autonome avec n8n.
Gestion de la Mémoire : Aller au-delà du Buffer
La mémoire est ce qui transforme un agent sans état en véritable assistant avec contexte. Le Window Buffer Memory natif de n8n conserve les N derniers échanges en mémoire vive : rapide, sans configuration, mais limité à la session en cours. À chaque nouveau démarrage du workflow ou après un délai d'inactivité, la mémoire est perdue. C'est acceptable pour un agent de qualification de leads où chaque requête est indépendante, mais inacceptable pour un chatbot d'assistance client censé se souvenir des échanges précédents.
Pour la persistance inter-sessions, le Postgres Chat Memory est la solution recommandée. Il stocke l'historique complet des conversations dans votre base PostgreSQL, identifiée par un sessionId (souvent l'identifiant de l'utilisateur ou de la conversation). Chaque nouveau message charge automatiquement l'historique correspondant depuis la base, offre à l'agent un contexte complet, puis sauvegarde la réponse avant de la retourner à l'utilisateur. La latence est négligeable (quelques millisecondes par requête) et les données restent sur votre infrastructure.
Pour des cas d'usage encore plus avancés, n8n 2.0 introduit la prise en charge des stores vectoriels (pgvector, Pinecone, Qdrant) qui permettent la RAG (Retrieval-Augmented Generation) : au lieu de tout charger en contexte, l'agent interroge une base de connaissances vectorisée pour récupérer uniquement les passages pertinents à la requête en cours. Cela permet de gérer des historiques de plusieurs milliers d'échanges sans exploser le contexte du LLM. Notre article sur la mémoire persistante, le RAG et le human-in-the-loop dans n8n 2.0 couvre ces architectures en détail.
Test et Débogage : Trouver et Corriger les Comportements Inattendus
Un agent qui fonctionne correctement sur votre message de test peut échouer sur des cas limites que vous n'avez pas anticipés. Le débogage structuré est une compétence à part entière, et n8n fournit des outils précieux pour cela.
Le mode Test Workflow de n8n ouvre une fenêtre de chat en temps réel. Après chaque interaction, cliquez sur chaque nœud de l'exécution pour voir exactement ce qui a transité : l'input reçu, les paramètres envoyés à l'outil ou au LLM, et l'output retourné. Cette vue par nœud vous permet de localiser précisément où la chaîne se brise. L'erreur est-elle dans le system prompt qui guide mal le LLM ? Dans la configuration de l'outil HTTP qui retourne un format inattendu ? Dans la mémoire qui charge un contexte trop long et "noie" les instructions ?
Construisez une suite de tests représentatifs avant de passer en production : couvrez le cas nominal (requête standard), les cas limites (message vide, requête ambiguë, langue incorrecte), et les cas d'erreur (API externe indisponible, données manquantes). Pour chaque cas de test, notez le comportement attendu et le comportement observé. Cette documentation vous servira à chaque fois que vous modifiez le system prompt ou ajoutez un outil.
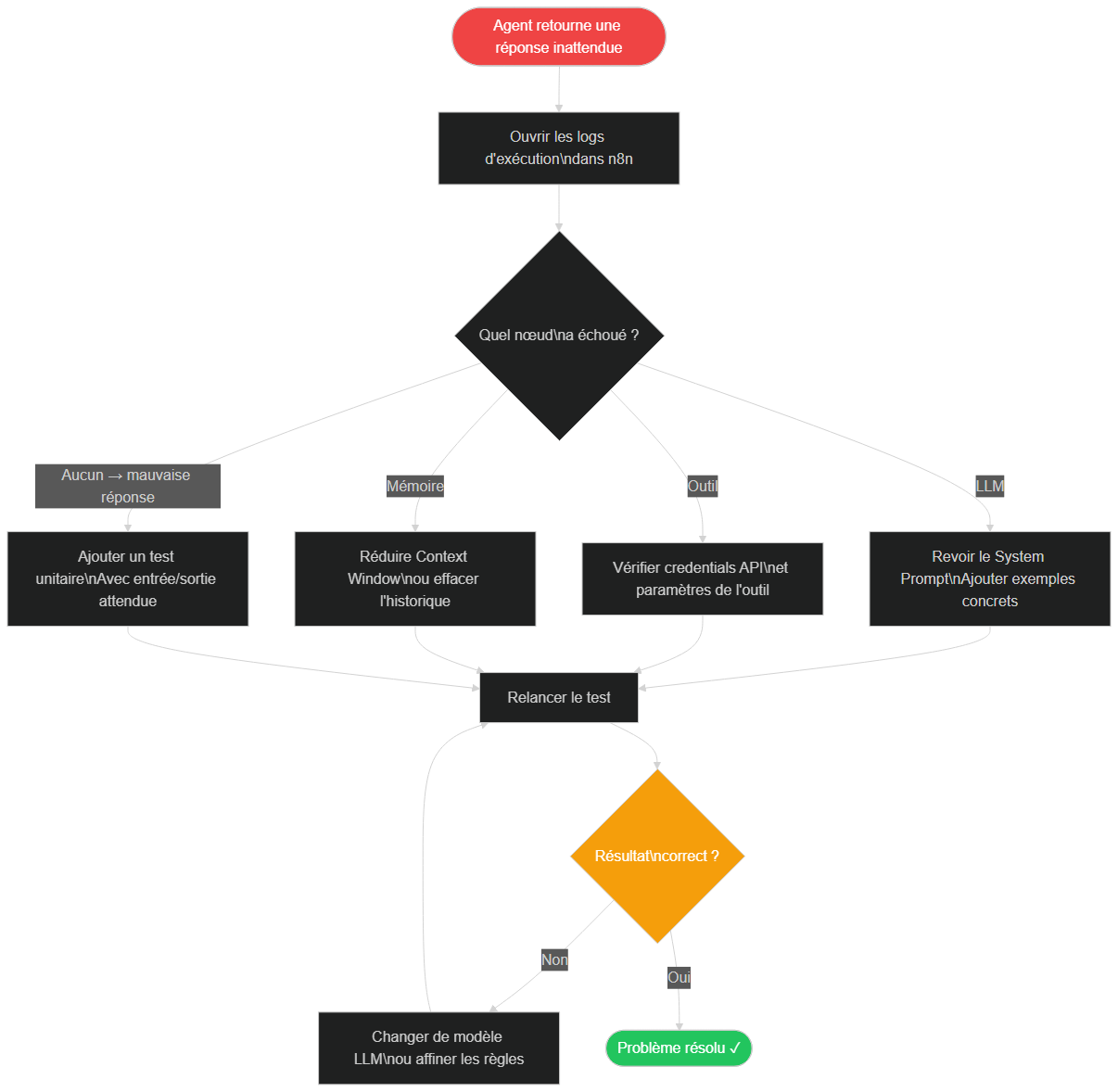 Boucle de débogage : ouvrir les logs, identifier le nœud défaillant (LLM, outil ou mémoire), appliquer la correction et retester jusqu'à stabilisation
Boucle de débogage : ouvrir les logs, identifier le nœud défaillant (LLM, outil ou mémoire), appliquer la correction et retester jusqu'à stabilisation
Un pattern de débogage efficace consiste à isoler chaque variable : si vous suspectez le system prompt, ne changez que le system prompt entre deux tests. Si vous suspectez l'outil HTTP, testez-le isolément hors de l'agent. Les changements multiples simultanés rendent impossible l'identification de la cause réelle d'une amélioration ou d'une régression. Pour les erreurs récurrentes sur un outil spécifique, ajoutez un nœud Error Trigger qui capture les exceptions et les envoie dans un canal Slack ou par email : vous serez alerté en temps réel au lieu de découvrir les pannes a posteriori.
Déploiement en Production : De votre Laptop au Serveur
Tester localement est une chose ; déployer un agent stable en production en est une autre. La figure ci-dessous illustre l'architecture de référence que nous utilisons chez BOVO Digital pour tous nos déploiements n8n en production.
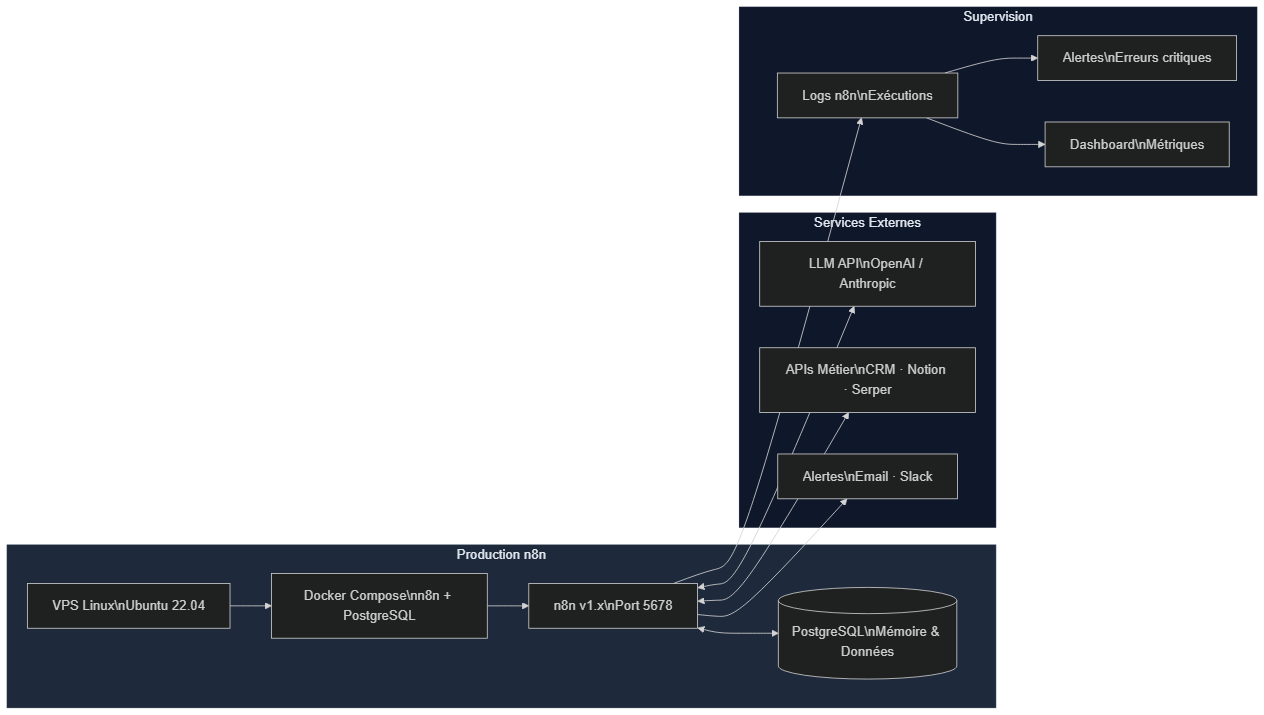 Architecture de production n8n : VPS Ubuntu avec Docker Compose, PostgreSQL dédié, reverse proxy HTTPS, connexions aux LLM et APIs métier, et supervision par logs et alertes
Architecture de production n8n : VPS Ubuntu avec Docker Compose, PostgreSQL dédié, reverse proxy HTTPS, connexions aux LLM et APIs métier, et supervision par logs et alertes
La méthode recommandée est Docker Compose sur un VPS Linux (Ubuntu 22.04 LTS). Votre docker-compose.yml contient au minimum deux services : n8n (image officielle n8nio/n8n) et postgres (image postgres:15). Les deux communiquent via un réseau Docker interne ; seul n8n est exposé vers l'extérieur, derrière un reverse proxy Nginx ou Caddy configuré pour HTTPS avec Let's Encrypt. Toutes les clés API et mots de passe sont injectés via des variables d'environnement dans le fichier .env, jamais en dur dans la configuration.
Avant d'activer votre workflow en production, effectuez une dernière série de validations. Vérifiez que le N8N_ENCRYPTION_KEY est configuré (protège les credentials stockés). Assurez-vous que les volumes Docker (données n8n + données PostgreSQL) sont montés sur des répertoires persistants, hors du conteneur, pour survivre aux redémarrages. Configurez une sauvegarde automatique de la base PostgreSQL (un simple pg_dump planifié via cron suffit pour commencer). Puis, une fois tous ces prérequis vérifiés, activez le workflow en basculant le toggle en haut à droite de l'interface n8n. À partir de ce moment, n8n gère les exécutions en arrière-plan, avec reprise automatique en cas d'erreur transitoire selon la politique de retry que vous avez définie.
Pour les agents exposés via webhook public, ajoutez une couche d'authentification au niveau du webhook n8n (Basic Auth ou Header Auth avec un token secret) et configurez un rate limiting au niveau du reverse proxy. Ces deux mesures suffisent à protéger votre agent contre les abus les plus courants.
Bonnes Pratiques de Supervision en Production
Un agent en production est un système autonome qui prend des décisions à votre place. Cette autonomie est sa force et son risque : sans supervision, un comportement dégradé peut passer inaperçu pendant des heures, voire des jours. La supervision n'est pas optionnelle — c'est une partie intégrante de l'architecture.
n8n conserve un log complet de chaque exécution dans la base PostgreSQL, accessible depuis l'interface "Executions". Configurez une politique de rétention adaptée à votre volume : 30 jours pour un agent à faible trafic, 7 jours pour un agent à fort volume. Les logs d'exécution contiennent l'input reçu, chaque appel d'outil intermédiaire avec ses résultats, et l'output final — une traçabilité complète pour auditer les décisions de l'agent.
Pour les alertes, configurez un nœud Error Trigger au niveau du workflow. Ce nœud se déclenche automatiquement lorsqu'une exécution se termine en erreur, et vous pouvez l'enchaîner à un envoi d'email, un message Slack ou une notification push. Définissez deux niveaux d'alerte : les erreurs critiques (l'agent ne répond plus, API LLM inaccessible, base de données hors ligne) qui nécessitent une intervention immédiate, et les erreurs non critiques (outil HTTP en timeout, résultat inattendu d'une API tierce) qui peuvent être traitées dans les heures suivantes.
Quelques métriques clés à surveiller chaque semaine : le taux de succès des exécutions (objectif >99% pour un agent de production), le temps d'exécution moyen par run (une dérive vers le haut signale souvent un problème de configuration LLM ou d'outil lent), et le coût LLM hebdomadaire (une hausse soudaine peut indiquer une boucle infinie ou une régression du system prompt qui génère des réponses anormalement longues). Ces trois métriques sont extractibles directement depuis les logs n8n avec une requête SQL sur la table execution_entity.
Exemple Concret : Agent Qualificateur de Leads
Voici un cas d'usage réel que nous déployons chez nos clients :
Objectif : Quand un prospect remplit un formulaire Typeform, l'agent recherche automatiquement son entreprise, évalue sa taille et son budget probable, rédige un email personnalisé, et décide si l'équipe commerciale doit être alertée.
Architecture :
- Trigger : Webhook Typeform
- LLM : GPT-4o
- Tools : Requête Pappers (données entreprise France), HTTP Request vers Notion (CRM), SendGrid (email)
- Memory : aucune (chaque lead est indépendant)
- System Prompt : "Tu es un qualificateur de leads B2B. Pour chaque prospect reçu, recherche son entreprise, évalue le potentiel (PETIT/MOYEN/GRAND), rédige un email de prise de contact personnalisé, et si le potentiel est GRAND, crée une tâche urgente dans Notion."
Résultat mesuré : 3h de travail commercial automatisées par jour, taux de réponse sur les leads GRAND amélioré de 40% (email hyper-personnalisé vs template générique).
Cas d'Usage Avancé : Agent Connecté au Protocole MCP
En 2026, une des évolutions les plus significatives de l'écosystème n8n est la compatibilité native avec le protocole MCP (Model Context Protocol). Ce protocole standardisé, initialement développé par Anthropic, permet à un LLM de se connecter à des serveurs d'outils exposant leurs capacités de manière structurée, sans que vous ayez à configurer chaque outil individuellement dans n8n.
Concrètement, un serveur MCP expose une liste de "tools" que votre agent n8n peut interroger dynamiquement : base de code, Notion, Google Workspace, systèmes internes propriétaires... Au lieu de créer un nœud HTTP Request pour chaque API, vous configurez une fois le nœud MCP Client dans n8n, pointez vers l'URL de votre serveur MCP, et l'agent dispose instantanément de tous les outils exposés par ce serveur. Cela réduit considérablement le temps de configuration pour les agents à nombreux outils. Notre guide complet sur connecter n8n à un serveur MCP pour vos agents IA détaille l'installation et la configuration étape par étape, avec des exemples pour les cas d'usage les plus courants.
Cette architecture est particulièrement puissante pour les entreprises qui disposent déjà d'une infrastructure d'outils internes exposée via MCP : le même serveur MCP peut alimenter plusieurs agents n8n différents, sans duplication de la logique d'intégration.
Les 3 Erreurs Classiques des Débutants sur n8n Agent IA
Erreur 1 — System prompt trop vague "Tu es un assistant utile" ne sert à rien. Soyez précis sur le rôle, le contexte, les règles et le format. Un system prompt efficace fait entre 150 et 400 mots et inclut des exemples de comportement attendu pour les cas les plus fréquents.
Erreur 2 — Trop d'outils dès le départ Commencez avec 1 ou 2 outils maximum. Un agent avec 10 outils mal décrits fera des erreurs de sélection systématiques. Ajoutez des outils progressivement, validez le comportement à chaque ajout, et assurez-vous que les descriptions sont suffisamment distinctes pour que le LLM choisisse le bon outil sans ambiguïté.
Erreur 3 — Pas de gestion des erreurs Ajoutez toujours un nœud de fallback : si l'agent échoue (API down, LLM timeout), que se passe-t-il ? Un email d'alerte ? Un message par défaut à l'utilisateur ? Une tâche créée manuellement ? Planifiez-le dès le début, avant même de tester le cas nominal.
n8n Agent vs Automation Classique : Quand Choisir Quoi ?
| Critère | Automation classique | Agent IA n8n |
|---|---|---|
| Cas d'usage | Tâches prévisibles, règles fixes | Tâches avec variabilité, jugement requis |
| Coût | Très faible | LLM : 0,01–0,10 € par run |
| Fiabilité | Très haute | Bonne, à superviser |
| Maintenance | Faible | Nécessite ajustement des prompts |
| Exemples | Sync CRM→email, factures auto | Qualification leads, support IA, recherche |
La règle BOVO Digital : si le workflow peut être exprimé en "si X alors Y", utilisez l'automatisation classique. Si vous écrivez des "si... mais sauf si... sauf quand...", passez à l'agent IA. Les deux approches sont complémentaires, et les meilleurs systèmes combinent des workflows déterministes pour les tâches critiques et des agents IA pour les tâches à haute variabilité.
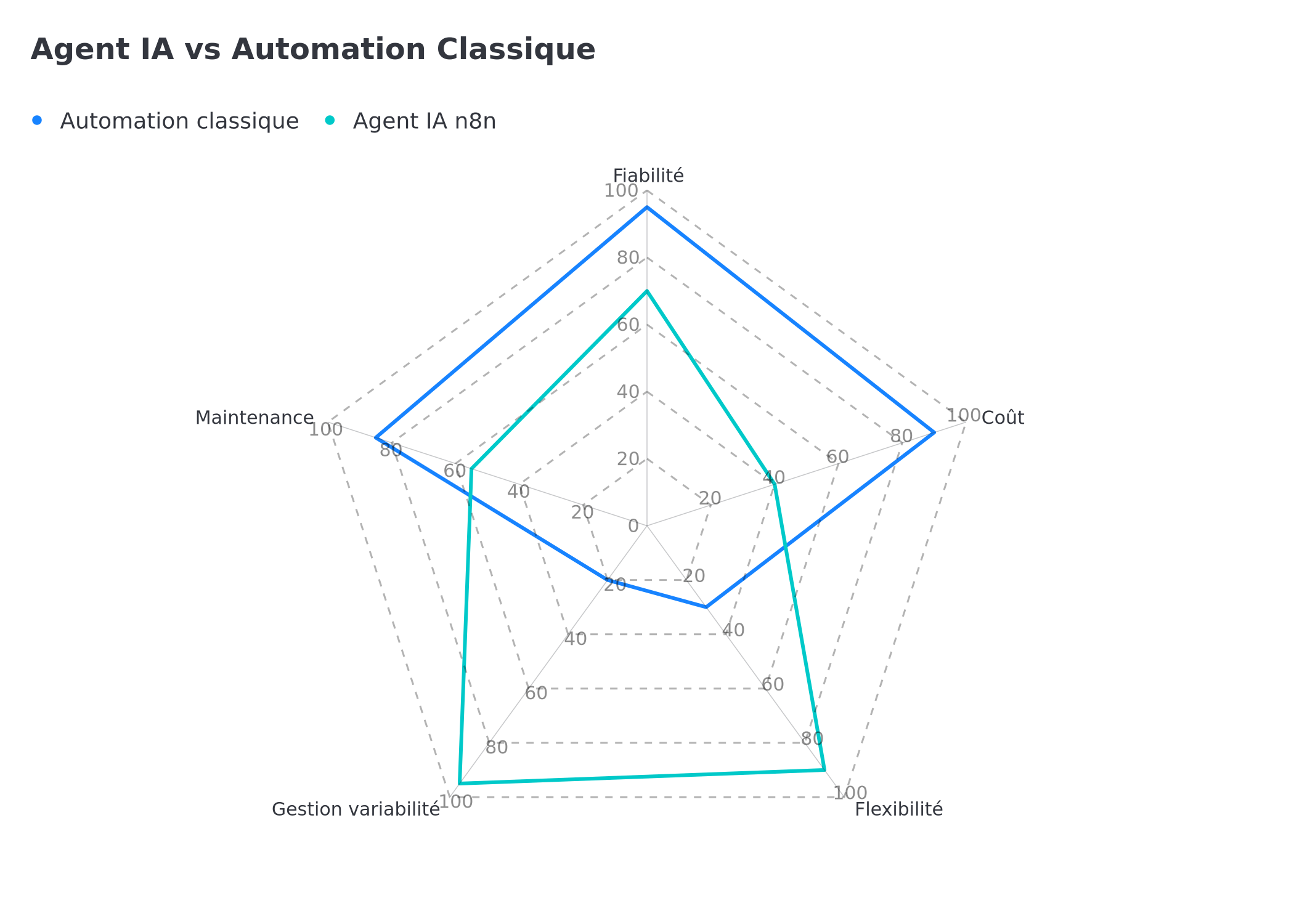 Comparaison radar : l'automation classique excelle en fiabilité et coût, l'agent IA en flexibilité et gestion de la variabilité
Comparaison radar : l'automation classique excelle en fiabilité et coût, l'agent IA en flexibilité et gestion de la variabilité
Le Piège du "Hello World" : Sécuriser ses Agents en Entreprise (DevSecOps)
Créer un agent sur son ordinateur local est une chose. Le déployer en production sur des données d'entreprise en est une autre. Sans isolation des credentials, sans filtrage des sorties LLM, et sans audit des outils exposés, un agent autonome devient une faille de sécurité majeure (le fameux "Agentic Supply Chain Attack"). Les bonnes pratiques exigent de compartimenter les rôles de l'agent, d'utiliser des bases de données de logs distinctes et de mettre en place des "Human-in-the-loop" pour les actions destructrices.
Passez du Tutoriel à la Production avec BOVO Digital
Vous avez réussi le tutoriel, mais vous hésitez à connecter cet agent à votre CRM ou à vos bases de données de production ? BOVO Digital accompagne les entreprises dans la conception et le déploiement d'agents IA sécurisés (DevSecOps). Nous auditons vos workflows et mettons en place les garde-fous nécessaires pour que l'IA agisse de manière autonome, mais sans risque. Contactez-nous pour déployer vos agents en production.
Aller Plus Loin : Agents Multi-Étapes et Sub-Agents
n8n supporte les architectures multi-agents : un agent orchestrateur qui délègue à des agents spécialisés. Par exemple :
- Agent orchestrateur : reçoit une demande client, analyse le contexte et détermine quelle combinaison d'agents spécialisés est nécessaire
- Agent recherche : scrape les données nécessaires via des APIs externes
- Agent rédaction : écrit la réponse personnalisée en fonction des données collectées
- Agent validation : vérifie la conformité avant envoi (ton, format, règles métier)
Cette architecture, que nous appelons une "flotte d'agents", permet de découpler les responsabilités et de remplacer ou améliorer un agent spécialisé sans impacter l'ensemble du système. Elle offre également une meilleure traçabilité : chaque agent spécialisé a ses propres logs d'exécution, ce qui facilite considérablement le débogage lorsqu'une étape de la chaîne produit un résultat inattendu. C'est l'étape naturelle après votre premier agent solo, et elle représente le niveau de maturité que visent nos clients après quelques semaines d'utilisation en production. Pour les données sensibles, combinez cette architecture avec Gemma 4 en local pour que rien ne quitte votre infrastructure.
Vous avez maintenant l'architecture complète, les décisions de configuration, les stratégies de débogage et les pratiques de supervision pour créer et maintenir un agent n8n en production. Le plus important : commencez simple, testez avec des données réelles, et itérez sur le system prompt jusqu'à obtenir le comportement voulu. Un agent imparfait en production vous apprend plus en une semaine que trois mois de planification.
Si vous voulez sauter la courbe d'apprentissage et avoir un agent en production en 48h, l'équipe BOVO Digital construit et déploie des agents n8n sur mesure pour des PME et entrepreneurs. Devis gratuit en 24h.
Étiquettes
FAQ
Quelle différence entre un workflow n8n classique et un agent IA n8n ?
Un workflow classique suit une logique fixe : si A alors B. Un agent IA utilise une boucle ReAct (Reason + Act) : il reçoit un objectif, réfléchit, utilise des outils, observe le résultat, et recommence jusqu'à atteindre l'objectif. Il s'adapte aux situations imprévues qu'un workflow rigide ne peut pas gérer.
Quel LLM utiliser avec n8n pour un agent IA en 2026 ?
Pour la production : GPT-4o (OpenAI) pour le meilleur équilibre performance/coût, ou Claude 3.5 Sonnet (Anthropic) pour la rédaction et l'analyse. Pour les données sensibles ou pour éviter les coûts API : Gemma 4 via Ollama (gratuit, 100% local, Apache 2.0). Commencez avec gpt-4o-mini pour vos tests — moins cher et largement suffisant pour la plupart des cas.
Combien coûte un agent n8n en production ?
Le coût principal est le LLM. Avec GPT-4o-mini : environ 0,001 € par run pour un agent simple, soit 1 € pour 1 000 exécutions. Avec GPT-4o : 0,01 à 0,10 € par run selon la complexité. Avec Gemma 4 en local via Ollama : 0 € de coût LLM. Le reste (hébergement n8n sur VPS) : 5 à 20 €/mois.
Faut-il être développeur pour créer un agent IA avec n8n ?
Non. n8n est une interface visuelle : vous connectez des nœuds sans écrire de code. La compétence principale requise est d'écrire de bons system prompts (en français ou anglais). Pour les intégrations avancées (API custom, base de données), des notions de JSON et HTTP sont utiles mais pas obligatoires.
Comment tester un agent n8n avant de le mettre en production ?
n8n propose un mode 'Test Workflow' avec une fenêtre de chat intégrée. Testez avec des cas réels représentatifs, y compris les cas limites (messages vides, requêtes hors-sujet, données manquantes). Vérifiez les logs de chaque nœud pour voir exactement comment l'agent a raisonné. Une fois stable sur 20-30 tests, activez le workflow en production.
Comment déployer un agent n8n en production sur un VPS ?
La méthode recommandée est Docker Compose sur un VPS Linux Ubuntu 22.04. Vous lancez n8n et PostgreSQL dans des conteneurs isolés, configurez un reverse proxy Nginx ou Caddy pour HTTPS, et stockez vos clés API dans des variables d'environnement. Une fois vos tests validés, activez le workflow en un clic — n8n gère les reprises automatiques en cas d'erreur.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
William Aklamavo
Expert en développement web et automatisation, passionné par l'innovation technologique et l'entrepreneuriat digital.


