
Éviter les Hallucinations de l'IA : Le Guide Complet pour les Entreprises (2026)
ChatGPT vous a inventé une loi. Claude a cité une source qui n'existe pas. Comment empêcher votre IA de vous mentir ? Ce guide explique les techniques éprouvées pour éliminer les hallucinations dans vos workflows.

Mis à jour le

Éviter les Hallucinations de l'IA : Le Guide Complet pour les Entreprises (2026)
Une IA qui se trompe avec assurance est plus dangereuse qu'une IA qui dit « je ne sais pas ».
Votre IA vient de vous remettre un rapport qui cite trois études... qui n'existent pas. Votre chatbot client vient de promettre une fonctionnalité que votre produit ne propose pas. Votre agent IA a créé une facture avec des données incorrectes. Éviter les hallucinations IA n'est donc pas un confort de geek : c'est une condition pour déployer l'intelligence artificielle en production sans exposer votre entreprise à des erreurs coûteuses.
Bienvenue dans le monde des hallucinations IA.
Ce n'est pas un bug. C'est une caractéristique fondamentale des modèles de langage — et la comprendre est la première étape pour la contrôler. Dans ce guide, vous allez découvrir ce qu'est exactement une hallucination, pourquoi elle survient, et surtout les techniques concrètes pour la réduire à un niveau maîtrisable : RAG, prompts contraints, validation croisée, supervision humaine, pipeline anti-hallucination, classification du risque et gouvernance. L'objectif n'est pas de promettre le zéro défaut — c'est impossible — mais de transformer une boîte noire imprévisible en un système fiable et auditable.
Qu'est-ce qu'une Hallucination IA ?
Une hallucination IA, c'est quand un modèle de langage génère des informations convaincantes mais factuellement fausses. Le modèle ne « sait » pas qu'il ment — il génère la suite statistiquement la plus probable d'une séquence de mots, qu'elle soit vraie ou non. C'est exactement là qu'est le piège : le texte est grammaticalement parfait, le ton est assuré, la structure est crédible. Rien dans la forme ne signale l'erreur. Un humain qui invente bafouille souvent ; un LLM qui invente le fait avec le même aplomb qu'une réponse correcte.
Il est utile de distinguer deux familles. Les hallucinations intrinsèques contredisent directement une information fournie dans le prompt (le modèle déforme un document qu'on lui a pourtant donné). Les hallucinations extrinsèques ajoutent des faits qui ne sont vérifiables nulle part dans le contexte fourni. Les premières se détectent en comparant la sortie à la source ; les secondes exigent une vérification externe.
Types d'hallucinations les plus fréquents :
- Hallucinations factuelles : Inventer des données, dates, chiffres, statistiques.
- Hallucinations de sources : Citer des articles, livres, jurisprudences ou études inexistants — avec parfois un faux numéro de DOI ou une fausse référence d'arrêt.
- Hallucinations de code : Générer des fonctions, paramètres ou librairies qui n'existent pas (un phénomène si répandu qu'il a donné lieu à une attaque, le « slopsquatting », où des paquets malveillants portent le nom de dépendances hallucinées).
- Hallucinations contextuelles : Mal interpréter une consigne et inventer un contexte ou des hypothèses jamais formulées.
Pourquoi est-ce particulièrement dangereux en entreprise ? Parce que la sortie d'un modèle est souvent consommée sans relecture, puis injectée dans un autre système : un CRM, un email client, un devis, une base de données. Une hallucination isolée devient alors une donnée erronée qui se propage. C'est la différence entre un assistant qui se trompe à l'oral — vite oublié — et un agent autonome qui écrit une fausse information dans vos systèmes de référence. Nous détaillons ce mécanisme dans notre article sur comment une IA invente une loi inexistante, un cas d'école dans le secteur juridique.
Pourquoi les LLM Hallucinent-ils ?
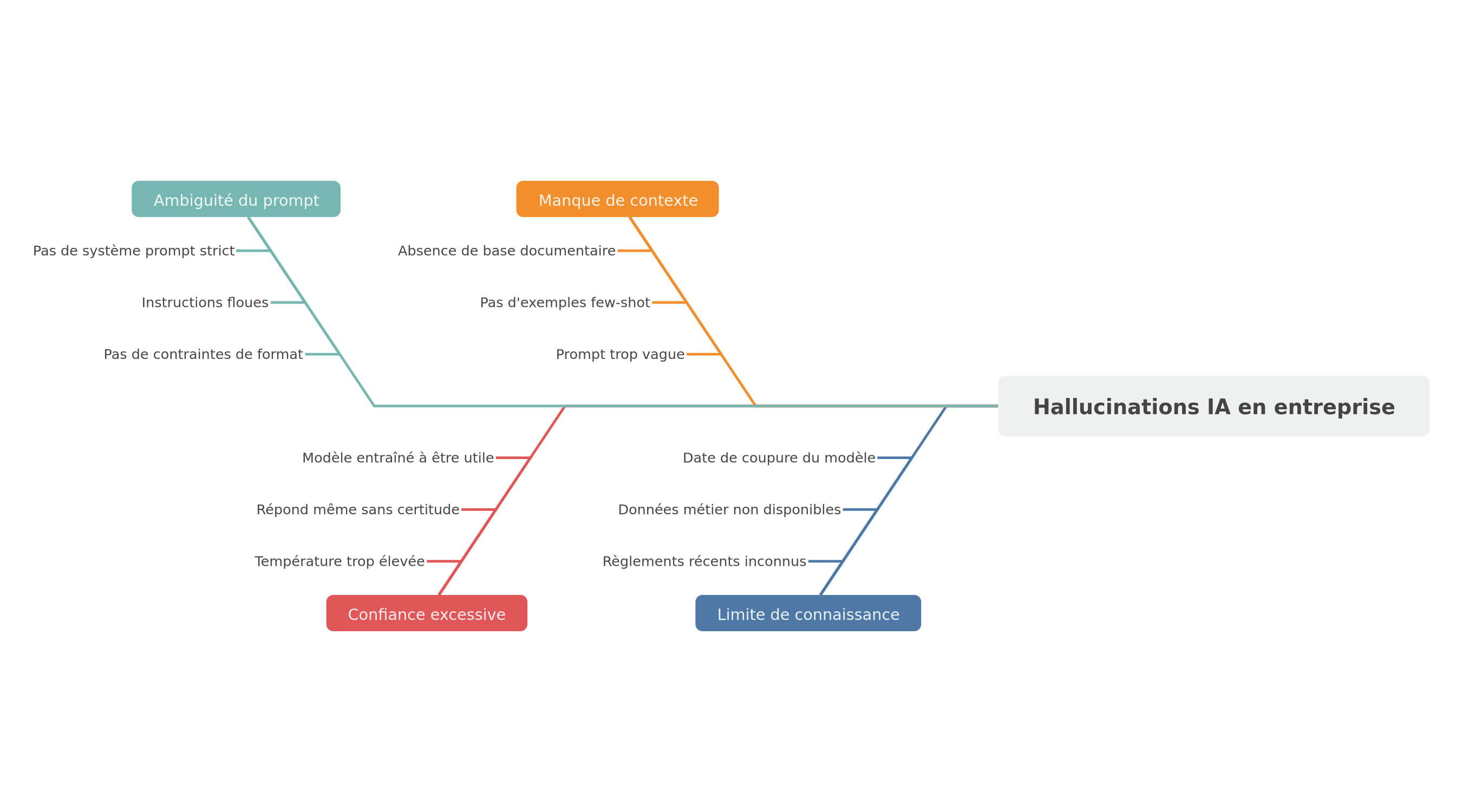 Diagramme en arête de poisson : limite de connaissance, manque de contexte, confiance excessive du modèle et ambiguïté du prompt
Diagramme en arête de poisson : limite de connaissance, manque de contexte, confiance excessive du modèle et ambiguïté du prompt
Les modèles de langage (GPT, Claude, Gemini, Mistral) sont entraînés à prédire le prochain token le plus probable. Ils n'ont pas accès à une « vérité » externe — ils s'appuient sur les régularités statistiques de leur corpus d'entraînement. Comprendre ce mécanisme évite deux erreurs symétriques : croire que le modèle « ment exprès », ou au contraire croire qu'il « connaît » réellement les faits. Ni l'un ni l'autre : il complète une probabilité.
Les 4 causes principales :
1. Limite de connaissance (knowledge cutoff)
Chaque modèle a une date de coupure de son entraînement. Au-delà, il n'a pas vu les événements, les prix, les versions de produits ou les réglementations récentes. Confronté à une question qui dépasse cette frontière, il n'a aucun moyen de « savoir qu'il ne sait pas » : il extrapole à partir de patterns anciens et produit une réponse plausible mais potentiellement périmée. C'est pourquoi un modèle peut décrire avec assurance une fonctionnalité logicielle qui a changé depuis sa coupure.
Solution : RAG (Retrieval-Augmented Generation). Connectez votre LLM à une base de connaissance mise à jour. L'IA cherche d'abord dans votre source de vérité, puis répond en s'appuyant sur le contexte récupéré au lieu de sa mémoire paramétrique.
2. Manque de contexte spécifique
Quand le modèle n'a pas l'information exacte sur votre entreprise — vos tarifs, vos procédures, vos références produits — il « comble les trous » avec ce qui ressemble le plus à une réponse vraisemblable. Le vide n'est jamais laissé vide : il est rempli par la moyenne statistique du corpus. Or la moyenne d'Internet n'est pas la vérité de votre organisation.
Solution : few-shot prompting + instructions de retrait. Donnez des exemples concrets dans votre prompt et autorisez explicitement l'abstention : « Si l'information ne figure pas dans le contexte fourni, réponds : Je ne dispose pas de cette information. » Cette permission de dire « je ne sais pas » est l'un des garde-fous les plus sous-estimés.
3. Confiance excessive du modèle
Les LLM sont optimisés pour être utiles et fluides. L'alignement par renforcement les pousse à toujours fournir une réponse satisfaisante plutôt qu'à exprimer un doute. Résultat : un modèle préférera souvent une réponse fausse mais assurée à un « je ne suis pas certain ». Cette surconfiance est un effet de bord de l'entraînement, pas une intention.
Solution : Chain-of-Thought + calibration explicite. Forcez le raisonnement étape par étape et demandez un niveau de confiance auto-déclaré. Un modèle invité à expliciter son incertitude est plus facile à filtrer en aval.
4. Ambiguïté du prompt
Un prompt flou produit une réponse inventée : face à plusieurs interprétations possibles, le modèle en choisit une et la traite comme acquise. Une question implicite, un acronyme non défini, une consigne contradictoire — autant de portes ouvertes à l'improvisation.
Solution : prompts structurés avec contraintes. Utilisez des formats explicites (JSON, checklists, gabarits), définissez les termes, et précisez ce que le modèle doit faire en cas de doute. Plus la structure est rigide, moins le modèle improvise. Ce principe rejoint l'idée développée dans votre IA est « bête » et c'est normal : un modèle n'est performant que s'il est correctement nourri en contexte.
Comment Éviter les Hallucinations IA : Les 7 Techniques Éprouvées
Aucune technique n'est suffisante seule. La fiabilité naît de la superposition de garde-fous : chaque couche attrape ce que la précédente a laissé passer. Le graphique ci-dessous illustre cette logique d'accumulation — les valeurs sont données à titre indicatif pour montrer la tendance, pas comme un benchmark universel : le gain réel dépend de votre cas d'usage et de la qualité de vos données.
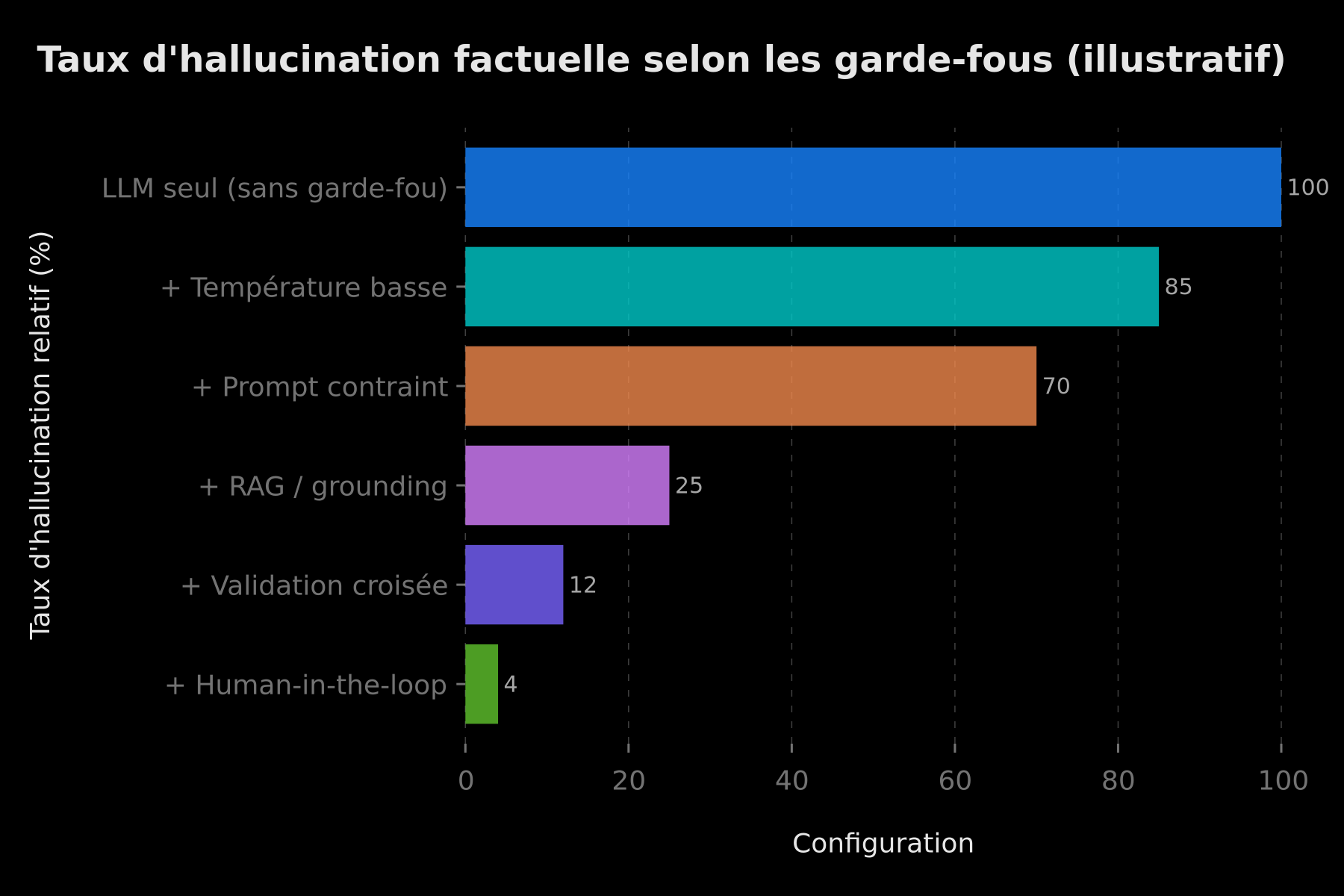 Plus on empile les garde-fous (température, prompt contraint, RAG, validation croisée, supervision humaine), plus le taux d'hallucination relatif diminue — ordre de grandeur illustratif
Plus on empile les garde-fous (température, prompt contraint, RAG, validation croisée, supervision humaine), plus le taux d'hallucination relatif diminue — ordre de grandeur illustratif
Technique 1 : RAG (Retrieval-Augmented Generation)
C'est la technique la plus efficace contre les hallucinations factuelles. Principe : avant de répondre, l'IA consulte votre base de connaissance et appuie sa réponse sur les extraits récupérés.
Implémentation avec n8n :
- Stocker vos documents dans une base vectorielle (Supabase, Pinecone, Qdrant).
- À chaque question, vectoriser la requête.
- Retrouver les 3 à 5 chunks les plus pertinents.
- Injecter ces chunks dans le contexte du LLM, avec la consigne de ne répondre qu'à partir d'eux.
Résultat : une réduction importante des hallucinations factuelles, souvent de l'ordre de 70 à 90 % selon les cas, à condition que la base soit propre, à jour et bien découpée. Attention : le RAG ne supprime pas le risque, il le déplace. Si votre base contient des informations contradictoires ou périmées, l'IA citera fidèlement... une mauvaise source. La qualité du RAG, c'est d'abord la qualité de la donnée indexée.
Technique 2 : Grounding avec sources citées
Demandez explicitement au LLM de citer ses sources et de distinguer ce qu'il sait avec certitude de ce qu'il estime. Le fait d'imposer une citation oblige le modèle à « accrocher » chaque affirmation à un extrait réel, et rend la vérification triviale pour un humain ou un système aval.
Prompt template :
Réponds à la question suivante en t'appuyant UNIQUEMENT sur le contexte fourni.
Pour chaque affirmation factuelle :
- Cite l'extrait exact qui la justifie.
- Si aucun extrait ne la justifie, n'affirme rien et signale-le.
- Distingue [CERTAIN] (justifié par le contexte) de [À VÉRIFIER].
Technique 3 : Validation croisée automatique
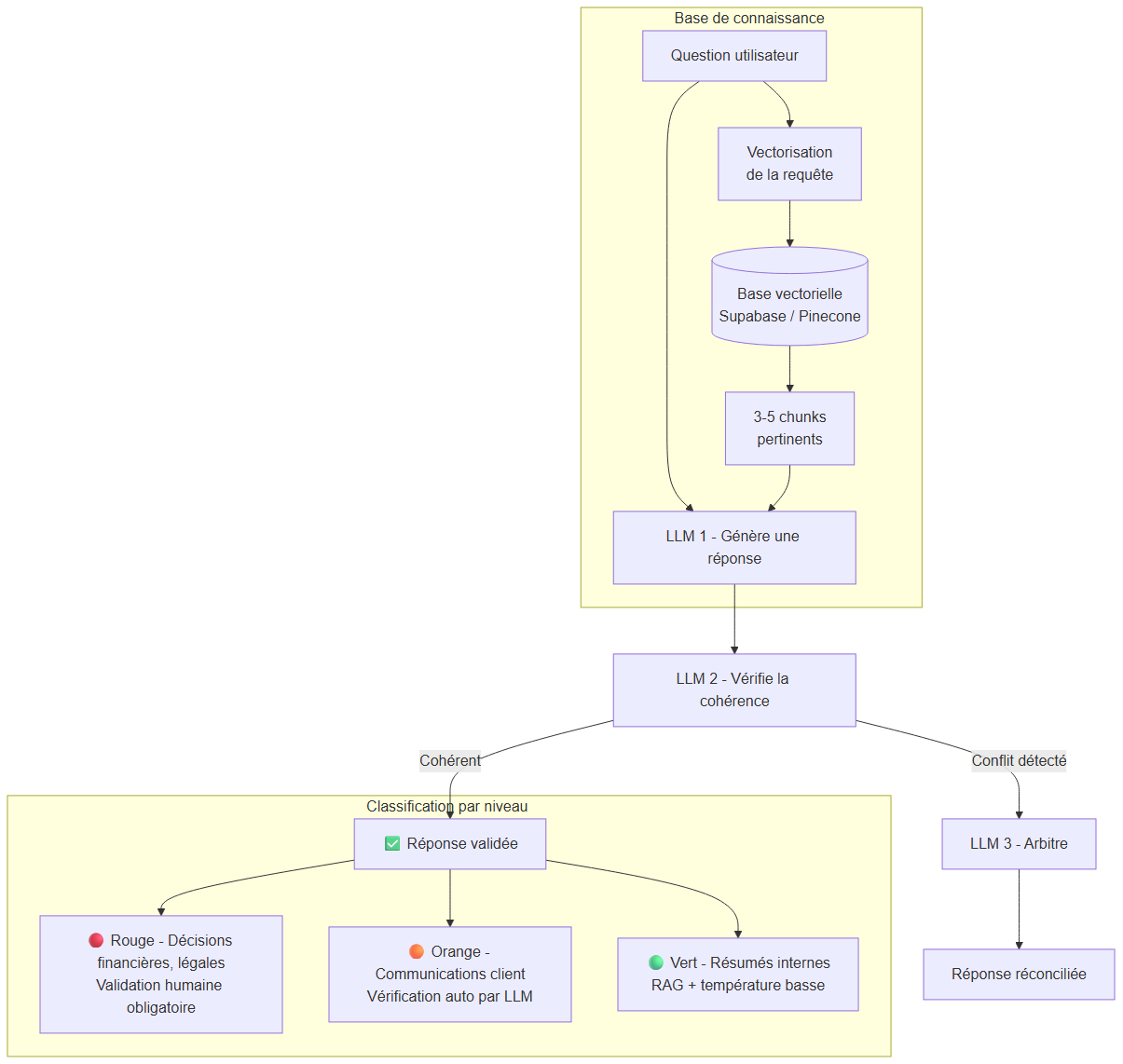 Pipeline complet anti-hallucination : RAG injecte le contexte, LLM 2 vérifie la cohérence, LLM 3 arbitre les conflits, puis classification Rouge/Orange/Vert selon le niveau de risque
Pipeline complet anti-hallucination : RAG injecte le contexte, LLM 2 vérifie la cohérence, LLM 3 arbitre les conflits, puis classification Rouge/Orange/Vert selon le niveau de risque
Dans un workflow n8n ou Make, après chaque réponse IA, ajoutez un second appel LLM dont le seul rôle est de vérifier la cohérence de la première réponse par rapport au contexte. Cette technique — proche du principe « LLM-as-a-judge » — détecte une bonne partie des contradictions internes sans intervention humaine.
Architecture :
Question → LLM 1 (génère) → LLM 2 (vérifie) → Si conflit → LLM 3 (arbitre)
Le surcoût en latence et en tokens est réel ; on le réserve donc aux sorties qui le justifient. C'est là qu'intervient la classification du risque, détaillée plus bas.
Technique 4 : Température et paramètres de sampling
La température contrôle l'aléa du modèle. Pour les tâches factuelles, réduisez-la radicalement :
- Température 0.0 : déterministe, idéal pour l'extraction de données et la classification.
- Température 0.3 : faible variabilité, bon pour les résumés factuels.
- Température 0.7+ : créatif, pour la génération de contenu où l'on souhaite de la diversité.
Important : abaisser la température réduit la variabilité, pas le risque d'erreur de fond. Un modèle à température 0 répétera la même hallucination de façon parfaitement stable si l'information manque. La température est un réglage d'appoint, jamais une protection à elle seule.
Technique 5 : Contraintes de format structuré
Forcez les sorties JSON avec validation par schéma. Un modèle contraint à produire un format précis improvise moins, et toute sortie non conforme est rejetée automatiquement avant d'atteindre vos systèmes.
{
"réponse": "string",
"niveau_de_confiance": "élevé|moyen|faible",
"sources_utilisées": ["string"],
"points_à_vérifier": ["string"]
}
Le champ sources_utilisées est précieux : s'il est vide alors que la question était factuelle, c'est un signal d'alerte exploitable par votre workflow.
Technique 6 : Contexte système strict
Le system prompt fixe les règles du jeu. Instruisez explicitement le modèle à refuser l'invention :
Tu es un assistant factuel. Règles absolues :
- Ne jamais inventer de données, statistiques ou citations.
- Si l'information n'est pas dans le contexte, dire "Je ne dispose pas de cette information".
- Toujours indiquer quand un sujet dépasse ta date de connaissance.
- Préférer "Je ne suis pas certain" à une réponse inventée.
Technique 7 : Human-in-the-loop pour les décisions critiques
Pour les outputs à fort enjeu (contrats, devis, données médicales, légales, financières), intégrez toujours une validation humaine dans le workflow. Dans n8n, un nœud « Wait » ou une approbation par email/Slack permet de suspendre l'agent jusqu'à validation. Cette technique mérite à elle seule une section : c'est le sujet de la partie suivante.
Superviser l'IA : le Human-in-the-Loop
Automatiser ne veut pas dire déléguer aveuglément. La supervision humaine — le human-in-the-loop — consiste à placer une personne au bon endroit de la chaîne, là où le coût d'une erreur dépasse le coût d'une relecture. L'enjeu n'est pas de tout relire (ce qui annulerait le gain de l'automatisation), mais de relire ce qui compte.
Trois modèles de supervision coexistent. Le human-in-the-loop insère une validation bloquante avant l'action : rien ne part sans aval humain. Le human-on-the-loop laisse l'IA agir mais sous surveillance, avec possibilité d'interrompre et de corriger a posteriori. Le human-out-of-the-loop est une autonomie complète, à réserver aux tâches à très faible enjeu et réversibles. Le choix se fait en fonction de l'enjeu et de la réversibilité de l'action.
L'erreur la plus fréquente n'est pas l'absence totale de supervision, mais la supervision théâtrale : un humain qui valide mécaniquement des dizaines de sorties sans vraiment les lire, par excès de confiance dans la machine. C'est le « biais d'automatisation ». La parade : ne demander une validation humaine que sur les cas réellement à risque (classés rouge), présenter à l'humain les éléments de doute mis en évidence par la validation automatique, et tracer chaque décision. Nous avons détaillé l'ampleur de ce risque dans l'article 99 % des entreprises font cette erreur de supervision IA.
Concrètement, une bonne supervision repose sur trois ingrédients : un point de contrôle placé avant toute action irréversible, un contexte de décision fourni à l'humain (la réponse de l'IA, ses sources, son niveau de confiance, les conflits détectés), et une boucle de feedback où les corrections humaines enrichissent la base de connaissance pour réduire les erreurs futures.
Construire un Pipeline Anti-Hallucination de Bout en Bout
Les sept techniques prennent toute leur valeur assemblées en chaîne. Un pipeline anti-hallucination robuste enchaîne typiquement six étapes :
- Réception et clarification de la requête — détecter les ambiguïtés, demander des précisions si nécessaire plutôt que de deviner.
- Récupération (RAG) — interroger la base vectorielle et injecter les extraits pertinents dans le contexte.
- Génération contrainte — produire une réponse au format structuré, avec citations et niveau de confiance, à température adaptée.
- Validation automatique — un second modèle vérifie la cohérence avec le contexte ; un schéma valide le format.
- Classification du risque — router la sortie en rouge / orange / vert selon l'enjeu et le niveau de confiance.
- Action ou escalade — exécution automatique pour le vert, vérification ciblée pour l'orange, validation humaine bloquante pour le rouge ; et journalisation systématique.
Ce type d'orchestration est exactement ce que permettent les plateformes comme n8n, où chaque étape devient un nœud explicite et auditable. Si vous débutez sur ce terrain, notre guide pour transformer vos workflows en systèmes intelligents avec n8n montre comment câbler concrètement un agent IA avec base vectorielle et garde-fous. L'avantage d'un pipeline explicite est double : il rend le comportement reproductible, et il transforme chaque incident en point d'amélioration localisable.
Mesurer le Risque : Classification Rouge / Orange / Vert
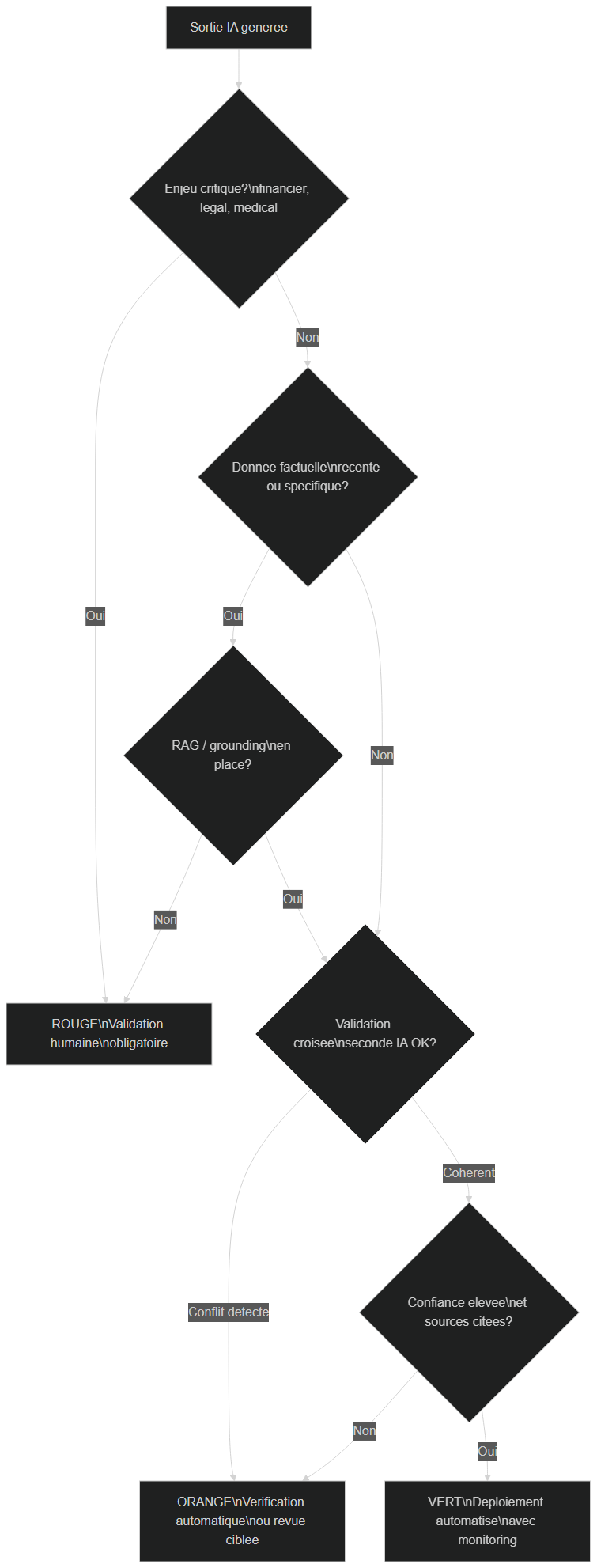 Arbre de décision : selon l'enjeu, la présence de RAG, la validation croisée et la confiance, la sortie est classée Rouge (validation humaine), Orange (vérification) ou Vert (déploiement automatisé avec monitoring)
Arbre de décision : selon l'enjeu, la présence de RAG, la validation croisée et la confiance, la sortie est classée Rouge (validation humaine), Orange (vérification) ou Vert (déploiement automatisé avec monitoring)
On ne traite pas une note de réunion interne comme un devis client. La clé d'une IA fiable en production, c'est de graduer les garde-fous selon l'enjeu. La classification en trois niveaux fournit une grille simple et actionnable :
- Rouge — décisions financières, légales, médicales, ou toute action irréversible. Validation humaine obligatoire avant exécution. Le coût d'une erreur dépasse de loin le coût d'une relecture.
- Orange — communications client, rapports, contenus diffusés en externe. Vérification automatique (validation croisée par un second LLM) et revue humaine par échantillonnage. L'erreur est gênante mais rattrapable.
- Vert — résumés internes, brouillons, suggestions, classifications à faible enjeu. RAG + température basse + monitoring suffisent. L'automatisation complète est acceptable.
L'arbre de décision ci-dessus formalise ce routage : il croise l'enjeu, la présence d'un RAG, le résultat de la validation croisée et le niveau de confiance pour décider si une sortie peut être déployée automatiquement ou doit remonter à un humain. Cette logique évite deux pièges symétriques : tout valider à la main (l'automatisation ne sert plus à rien) ou tout laisser passer (le risque devient incontrôlé).
Pour que cette classification ne reste pas théorique, il faut la mesurer. Constituez un jeu de tests représentatif de vos cas réels, avec des réponses de référence. Faites tourner votre assistant dessus à intervalles réguliers, comparez ses sorties aux faits attendus, et suivez un taux d'erreur factuelle dans le temps. Définissez un seuil cible par catégorie (par exemple plus strict sur le rouge) et déclenchez une alerte dès qu'il est dépassé. Des approches publiques comme les jeux d'évaluation de véracité (par exemple TruthfulQA) ou les classements de fidélité au contexte (comme le leaderboard HHEM de Vectara) donnent un point de repère méthodologique, mais votre métrique la plus utile reste celle calculée sur vos données.
Gouvernance et Conformité
Au-delà de la technique, éviter les hallucinations IA est devenu un sujet de gouvernance. Le règlement européen sur l'IA (AI Act), entré en vigueur en 2024 avec une application échelonnée jusqu'en 2026-2027, impose des obligations croissantes pour les systèmes à haut risque : gestion des risques, qualité des données, traçabilité, transparence et supervision humaine. Une IA qui produit des décisions opaques et invérifiables n'est plus seulement un risque opérationnel — c'est un risque de conformité.
Quelques principes de gouvernance concrets, sans verser dans le juridique :
- Traçabilité — journaliser les entrées, les sorties, les sources utilisées et les décisions humaines, de façon à pouvoir reconstituer pourquoi une réponse a été produite.
- Transparence — informer l'utilisateur final qu'il interagit avec une IA, et signaler les réponses non vérifiées.
- Responsabilité — désigner clairement qui est responsable des sorties de chaque système IA ; l'IA assiste, elle ne porte pas la responsabilité.
- Protection des données — encadrer ce qui est envoyé aux modèles (données personnelles, secrets), surtout avec des API tierces.
Cette dimension n'est pas un frein : une IA gouvernée est une IA dans laquelle on peut investir durablement, parce qu'elle est défendable devant un client, un auditeur ou un régulateur.
Cas d'Entreprise : Trois Situations Typiques
Le support client. Un chatbot branché sur la documentation produit via RAG répond aux questions courantes. Tant qu'il cite la section de doc utilisée et reste sur du vert, il fonctionne en autonomie. Dès qu'une question touche à un engagement contractuel (remboursement, SLA), elle est classée rouge et escaladée à un agent humain. L'IA absorbe le volume, l'humain garde la main sur l'engagement.
Le traitement documentaire. Un agent extrait des informations de factures ou de contrats pour les injecter dans un ERP. Ici, la sortie structurée (JSON validé par schéma) et la validation croisée sont indispensables, car la donnée part directement dans un système de référence. Les montants au-dessus d'un seuil passent en validation humaine.
La veille et la synthèse interne. Un assistant résume des rapports pour les équipes. Enjeu faible, contenu réversible : RAG + température basse + monitoring suffisent. C'est typiquement du vert, où l'automatisation complète apporte un gain net sans exposer l'entreprise.
Le fil rouge de ces trois cas : ce n'est pas le modèle qui fait la fiabilité, c'est l'architecture autour de lui. Le même LLM peut être dangereux dans le premier cas et parfaitement sûr dans le troisième, selon les garde-fous qui l'entourent.
Limites : Ce qu'Aucune Technique ne Résout
Soyons honnêtes sur les bornes. Aucune méthode ne garantit zéro hallucination. Les LLM restent probabilistes ; on réduit le risque, on ne l'annule pas. Trois limites méritent d'être gardées en tête.
D'abord, le RAG ne vaut que ce que vaut sa base : une donnée fausse, périmée ou contradictoire produira une réponse fausse mais bien sourcée — une fausse sécurité. Ensuite, la validation croisée par un second LLM partage des biais avec le premier : deux modèles peuvent halluciner de concert sur un même sujet mal couvert. Enfin, la supervision humaine est faillible : fatigue, biais d'automatisation, surcharge. Empiler les garde-fous réduit la probabilité d'erreur, mais aucun n'est parfait.
La bonne posture n'est donc pas la recherche d'une garantie absolue, mais la gestion d'un risque résiduel : le mesurer, le maintenir sous un seuil acceptable pour chaque usage, et le surveiller dans la durée. C'est exactement la différence entre un gadget impressionnant en démo et un système de production sur lequel une entreprise peut s'appuyer.
Conclusion : L'IA Fiable est une Architecture, pas un Paramètre
Éviter les hallucinations IA n'est pas une question de choisir le « bon » modèle ou de baisser la température jusqu'à zéro. C'est une question d'architecture système, où chaque couche joue son rôle :
- RAG pour ancrer les réponses sur des données réelles et à jour.
- Prompts structurés et citations pour contraindre les sorties et rendre la vérification facile.
- Validation croisée pour attraper les incohérences sans intervention humaine.
- Supervision humaine ciblée sur les décisions critiques, jamais théâtrale.
- Classification du risque pour graduer l'effort de contrôle.
- Gouvernance et mesure pour rendre le tout auditable et durable.
Chez BOVO Digital, chaque workflow IA que nous construisons intègre ces garde-fous dès la conception — pas en tant qu'ajout après coup. C'est ce qui sépare une IA impressionnante d'une IA fiable.
Étiquettes
FAQ
Qu'est-ce qu'une hallucination IA et pourquoi est-ce dangereux en entreprise ?
Une hallucination IA est quand un modèle génère des informations convaincantes mais fausses (données inventées, sources inexistantes, statistiques fictives). En entreprise, cela peut causer des décisions basées sur des données erronées, des communications client incorrectes ou des problèmes légaux.
Quelle est la technique la plus efficace pour éviter les hallucinations IA ?
Le RAG (Retrieval-Augmented Generation) est la technique la plus efficace. Elle connecte votre LLM à une base de données mise à jour en temps réel. L'IA consulte d'abord votre source de vérité avant de répondre, ce qui réduit fortement les hallucinations factuelles (souvent de l'ordre de 70 à 90 % selon les cas et la qualité de la base).
Comment configurer n8n pour minimiser les hallucinations IA dans mes workflows ?
Utilisez la combinaison RAG + température basse (0.1-0.3) + sorties JSON structurées + validation croisée par un second LLM. Dans n8n, connectez un nœud de base vectorielle (Supabase/Pinecone) avant votre agent IA, et ajoutez un nœud de validation en sortie pour les décisions critiques.
Est-ce que réduire la température à 0 élimine complètement les hallucinations ?
Non. La température 0 rend le modèle déterministe (il choisit toujours le token le plus probable) mais ne l'empêche pas d'halluciner si l'information n'est pas dans son corpus d'entraînement. Le RAG est nécessaire pour les données factuelles récentes ou spécifiques à votre domaine.
Peut-on garantir zéro hallucination avec une IA ?
Non, aucune technique ne garantit zéro hallucination à 100 %. Les LLM restent probabilistes par nature. L'objectif réaliste est de réduire le taux d'erreur à un niveau acceptable pour chaque cas d'usage, puis de le contrôler avec de la validation automatique, une supervision humaine sur les décisions critiques et un monitoring continu.
Comment mesurer le taux d'hallucination d'un assistant IA ?
Constituez un jeu de tests représentatif avec des réponses de référence, faites tourner votre assistant dessus, puis comparez ses réponses aux faits attendus (manuellement ou via un LLM évaluateur). Suivez un taux d'erreur factuelle dans le temps et déclenchez une alerte dès qu'il dépasse votre seuil cible.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
William Aklamavo
Expert en développement web et automatisation, passionné par l'innovation technologique et l'entrepreneuriat digital.

