
Fuite de Claude Code : 512 000 lignes de code source exposées sur npm
Le 31 mars 2026, un fichier de débogage oublié dans le package npm d'Anthropic a rendu public le code source complet de Claude Code — 512 000 lignes, 1 906 fichiers, l'architecture interne d'un outil IA à 2,5 milliards de revenus annuels. Voilà ce que cette fuite révèle.

Mis à jour le

Fuite de Claude Code : 512 000 lignes de code source exposées sur npm
En matière de sécurité, ce n'est jamais ce que vous savez qui vous trahit. C'est ce que vous avez oublié.
Le 31 mars 2026, le chercheur en sécurité Chaofan Shou a découvert quelque chose d'inhabituel dans le package npm @anthropic-ai/claude-code. La fuite Claude Code npm Anthropic 2026 n'était pas le résultat d'un hack sophistiqué, ni l'œuvre d'un groupe de cybercriminels organisés. C'était quelque chose de bien plus banal — et pour cette raison, bien plus instructif.
Un fichier .map oublié dans la version de production avait exposé, en quelques heures, 512 000 lignes du code TypeScript non obfusqué de l'un des outils d'intelligence artificielle les plus stratégiques du marché. Ce qui s'est passé ce jour-là dépasse largement le seul cas Anthropic : c'est un miroir tendu à toute l'industrie logicielle sur la fragilité de nos processus de publication.
Ce qu'est un fichier source map — et pourquoi ça change tout
Pour comprendre pourquoi cette fuite a été possible, il faut d'abord comprendre ce qu'est un fichier source map. Lorsqu'un développeur écrit du TypeScript, ce code lisible par un humain est transformé — compilé, minifié, parfois obfusqué — avant d'être distribué. Le résultat final ressemble à une longue chaîne de caractères compressés, quasi illisible à l'œil nu.
Un fichier source map (extension .map) est l'outil qui fait le chemin inverse. Il contient la cartographie complète entre le code distribué et le code source original : noms de variables, noms de fonctions, structure des fichiers, commentaires. C'est un outil indispensable en développement et en débogage — il permet aux développeurs de voir exactement quelle ligne de leur code TypeScript correspond à quelle erreur dans le code compilé.
En production, un fichier source map n'a aucune raison d'être présent. Il n'améliore pas les performances. Il ne bénéficie pas à l'utilisateur final. Il est là uniquement pour servir les développeurs qui déboguent. Et s'il est présent dans un package publié publiquement, il revient à livrer les plans architecturaux complets d'un bâtiment à quiconque télécharge la clé.
Ce que les équipes d'Anthropic ont oublié, c'est exactement ce que la majorité des équipes oublient : les fichiers d'outillage de développement ne disparaissent pas automatiquement en production. Il faut des processus explicites pour les exclure. Et ces processus, lorsqu'ils reposent uniquement sur la vigilance humaine, échouent.
Deux fuites en cinq jours : la chronologie complète
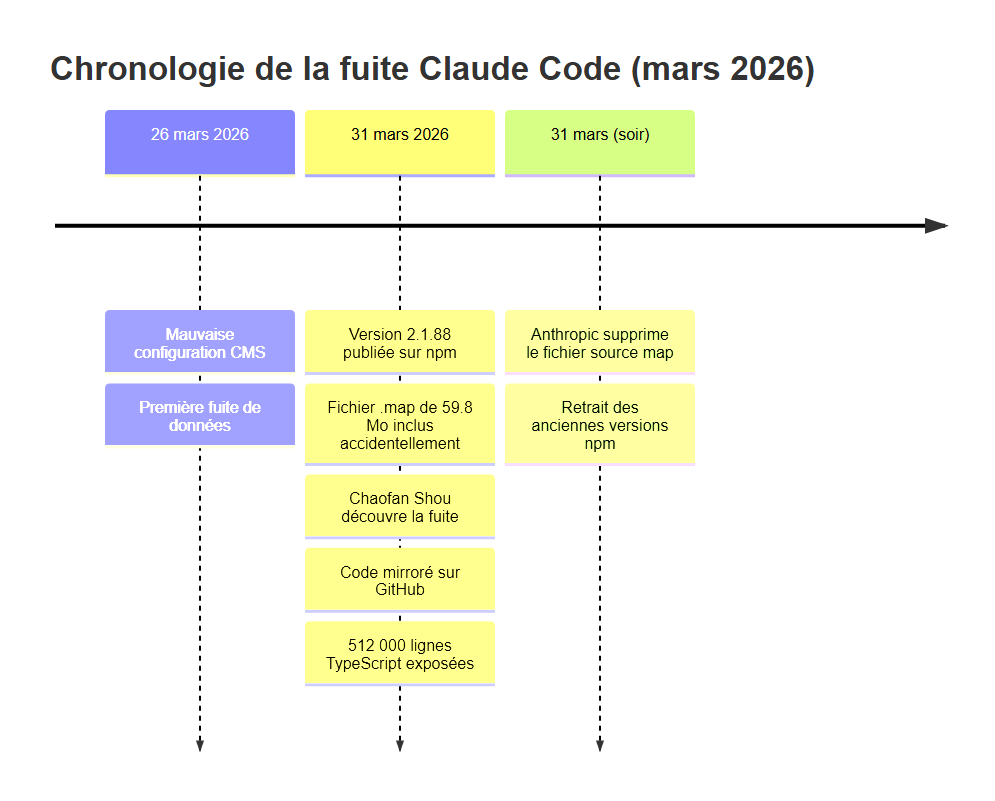
L'incident du 31 mars 2026 n'était pas isolé. Il était la deuxième exposition en cinq jours pour Anthropic. Pour comprendre l'ampleur de ce qui s'est passé, il faut reprendre la chronologie depuis le début.
Le 26 mars 2026, une première fuite se produit. Elle est d'une nature différente : une mauvaise configuration de leur système de gestion de contenu (CMS) expose des informations internes. Cet incident, moins spectaculaire en termes de volume de données, est pourtant révélateur : les processus de contrôle d'Anthropic présentaient des failles systémiques, pas ponctuelles.
 Chronologie de l'incident : double fuite npm d'Anthropic (26-31 mars 2026)
Chronologie de l'incident : double fuite npm d'Anthropic (26-31 mars 2026)
Puis vient le 31 mars 2026. La version 2.1.88 du package @anthropic-ai/claude-code est publiée sur le registre npm. Elle contient, par accident, un fichier source map de 59,8 mégaoctets. Ce fichier, supposé rester dans l'environnement de développement interne, pointe vers un bucket de stockage R2 d'Anthropic contenant le code TypeScript original.
Chaofan Shou — un chercheur en sécurité reconnu — repère l'anomalie. En quelques heures, il documente la découverte publiquement. La communauté des développeurs réagit rapidement : le code est téléchargé, analysé, et plusieurs copies sont mirrorées sur GitHub avant qu'Anthropic ait le temps d'intervenir.
Anthropic réagit en supprimant le fichier source map et en retirant les anciennes versions concernées du registre npm. Mais à ce stade, le mal est fait. Les snapshots existent sur des serveurs tiers. La fuite accidentelle est devenue un fait accompli.
Ce qui frappe dans cette chronologie, c'est la rapidité de la propagation. Entre la publication du package et la mise en miroir publique du code, quelques heures à peine se sont écoulées. Dans l'ère du développement open source, un secret exposé publiquement — même brièvement — cesse d'être un secret.
Anatomie de 512 000 lignes : ce que le code révèle sur l'architecture de Claude Code
Le volume est en lui-même impressionnant. 512 000 lignes de TypeScript réparties sur 1 906 fichiers, c'est une base de code de taille significative — comparable à des projets open source majeurs. Mais au-delà du volume, c'est la structure révélée qui intéresse les observateurs.
Selon les rapports publiés suite à l'incident, trois fichiers concentrent une large part de la logique centrale :
QueryEngine.ts— 46 000 lignes. C'est le moteur de traitement des requêtes, le cœur algorithmique qui orchestre les interactions entre l'utilisateur et les modèles de langage sous-jacents.Tool.ts— 29 000 lignes. Ce fichier décrit l'implémentation des outils agents — la mécanique qui permet à Claude Code d'exécuter des actions concrètes dans un environnement de développement.commands.ts— 25 000 lignes. Il contient la logique des commandes, en particulier les 85 slash commands qui permettent à l'utilisateur d'interagir avec l'outil.
La fuite révèle également l'existence d'une quarantaine d'outils agents distincts. Dans l'architecture des LLM modernes, les outils sont les briques qui permettent au modèle d'interagir avec le monde réel : lire des fichiers, exécuter du code, rechercher des informations, appeler des API externes. Quarante outils, c'est un écosystème substantiel qui explique en partie pourquoi Claude Code s'est imposé comme un outil de développement compétitif.
Ce que cette architecture révèle, selon notre lecture des rapports disponibles, c'est une conception délibérément modulaire. Les fichiers sont séparés par domaine fonctionnel, ce qui facilite la maintenance mais requiert une coordination stricte lors des publications. C'est précisément cette complexité qui rend les oublis plus probables : plus un projet est vaste, plus la surface d'exposition augmente.
Il faut souligner ce que cette analyse ne peut pas faire : nous ne pouvons pas affirmer de manière certaine la logique interne exacte du code, les décisions d'architecture prises délibérément, ou les performances réelles des algorithmes impliqués. Ces éléments restent propriétaires d'Anthropic. Ce que nous savons, c'est ce que les observateurs ont rapporté publiquement suite à la fuite.
KAIROS, autoDream et BUDDY : des fonctionnalités que personne ne connaissait
Parmi les éléments les plus commentés de la fuite, trois fonctionnalités non publiées ont particulièrement retenu l'attention. Leur existence, révélée accidentellement, illustre comment les grandes entreprises développent des capacités en interne avant tout déploiement public.
KAIROS est décrit dans les rapports comme un mode démon — une capacité d'exécution en arrière-plan qui permettrait à Claude Code de fonctionner de manière autonome sans intervention active de l'utilisateur à chaque étape. Ce type de fonctionnalité répond à un besoin réel dans les environnements de développement professionnels, où les pipelines automatisés doivent pouvoir déléguer des tâches longues à un agent IA.
autoDream est un système de consolidation de mémoire. Il est lié au système de mémoire en trois couches que la fuite a également révélé — un mécanisme baptisé MEMORY.md qui permet à Claude Code de maintenir un contexte persistent entre les sessions. La consolidation automatique de cette mémoire représente une ambition technique significative : donner à l'agent une forme de continuité entre les conversations.
BUDDY est d'une nature plus légère. C'est ce que les développeurs appellent un easter egg : un système d'animal virtuel numérique intégré dans le code. Son existence dans une base de code de production témoigne d'une culture d'entreprise qui autorise une forme de créativité et d'humour dans le développement — mais aussi du fait que des développeurs passent du temps significatif sur des fonctionnalités non liées au produit principal.
Les noms internes des modèles chez Anthropic — Capybara, Fennec et Numbat — ont également été exposés. Ces noms de code sont typiquement utilisés en interne avant que les modèles ne reçoivent leurs noms commerciaux définitifs. Leur révélation donne un aperçu de la culture de développement interne, même si elle ne révèle rien de fondamental sur les capacités des modèles eux-mêmes.
L'ironie de l'Undercover Mode
Parmi toutes les découvertes, une se démarque par son ironie particulière, et mérite qu'on s'y attarde longuement.
Anthropic avait construit, selon les rapports disponibles, un système appelé "Undercover Mode" — conçu spécifiquement pour empêcher leur IA de révéler des informations internes dans des dépôts publics. C'est une fonctionnalité de protection délibérée : l'IA elle-même était programmée pour ne pas divulguer de détails sur son architecture ou son fonctionnement interne lorsqu'elle interagissait dans des contextes publics.
C'est une approche de sécurité sophistiquée. Elle reconnaît que les modèles de langage peuvent, dans certaines circonstances, révéler plus d'informations sur leur implémentation qu'il n'est souhaitable. L'Undercover Mode cherchait à créer une barrière comportementale à ce risque.
Ils avaient pensé à tout. Sauf au fichier .map oublié dans le package npm.
L'IA était configurée pour garder les secrets. Mais le processus humain de publication ne l'était pas. C'est exactement le type d'angle mort que l'on retrouve systématiquement dans les projets : la sécurité est pensée dans les couches que les équipes voient et contrôlent. Elle est oubliée dans les couches intermédiaires — les outils de build, les pipelines de publication, les configurations de CI/CD — que tout le monde utilise mais que personne ne vérifie vraiment.
Cette ironie n'est pas anecdotique. Elle pointe vers une vérité fondamentale de la sécurité logicielle : on sécurise ce qu'on perçoit comme un risque. Et les fichiers de débogage qui traînent dans un pipeline de publication ne sont jamais perçus comme un risque — jusqu'au jour où ils le deviennent.
La supply chain npm : un vecteur d'exposition sous-estimé
Pour apprécier pleinement les implications de cet incident, il faut comprendre l'écosystème dans lequel il s'est produit. npm (Node Package Manager) est le plus grand registre de packages logiciels au monde. Des millions de projets l'utilisent quotidiennement pour distribuer et consommer des bibliothèques JavaScript et TypeScript.
 Flowchart d'un pipeline de publication npm sécurisé avec validation automatisée à chaque étape
Flowchart d'un pipeline de publication npm sécurisé avec validation automatisée à chaque étape
La popularité de npm est précisément ce qui en fait un vecteur d'exposition aussi puissant. Lorsqu'un package est publié sur npm, il devient instantanément accessible à des millions de développeurs dans le monde entier. Les gestionnaires de cache et de miroir — comme ceux utilisés par les entreprises pour leur infrastructure interne — téléchargent automatiquement les nouvelles versions.
Dans le cas d'Anthropic, cela signifie que le fichier source map de 59,8 Mo a pu être téléchargé par des centaines ou des milliers de systèmes automatisés dans les minutes suivant sa publication, bien avant que l'anomalie soit détectée et corrigée. C'est la nature même de la supply chain logicielle moderne : la distribution est instantanée et massive.
La sécurité de la supply chain npm est un sujet qui dépasse le seul cas Anthropic. En 2024 et 2025, plusieurs incidents majeurs ont impliqué des packages npm malveillants ou compromis. L'incident Anthropic est d'une nature différente — il ne s'agit pas d'un acteur malveillant, mais d'une erreur interne — mais il illustre le même problème fondamental : la confiance dans l'écosystème npm repose sur des processus de publication rigoureux, et ces processus sont rarement aussi rigoureux qu'ils devraient l'être.
Ce que révèle la fuite Claude Code, c'est que même les entreprises les plus sophistiquées techniquement ne sont pas immunisées contre les erreurs de publication basiques. Et si Anthropic, avec ses équipes de sécurité dédiées et son infrastructure de classe mondiale, peut publier un fichier source map de 59,8 Mo par accident, une startup de dix personnes peut le faire encore plus facilement.
Open source vs propriétaire : ce qu'une fuite accidentelle change
L'un des débats que cet incident a alimenté dans la communauté des développeurs concerne la question fondamentale de la transparence dans l'IA. Anthropic est une entreprise dont les modèles sont propriétaires et le code source n'est pas public. La fuite accidentelle a donc ouvert une fenêtre inédite sur une architecture qui aurait normalement dû rester confidentielle.
Certains observateurs ont argumenté que la fuite démontre les limites du modèle propriétaire : si le code finit par être exposé accidentellement, pourquoi ne pas l'avoir rendu public dès le début et bénéficier des avantages de l'open source ? Les entreprises comme Meta et Mistral ont fait des choix différents avec leurs modèles LLaMA et Mistral, qui sont accessibles sous des licences permissives.
D'autres ont souligné que la fuite ne change pas fondamentalement la dynamique concurrentielle. Le code source de Claude Code n'expose pas les poids des modèles sous-jacents — qui restent la véritable propriété intellectuelle d'Anthropic. L'architecture d'un outil agent, aussi détaillée soit-elle, ne reproduit pas les capacités d'un modèle de langage entraîné sur des milliards de tokens. Les concurrents ont pu observer comment Anthropic a construit son outil, mais pas comment ses modèles fonctionnent à un niveau fondamental.
Ce que la fuite révèle sur la question open source/propriétaire, c'est surtout l'écart entre la rhétorique et la réalité opérationnelle. Anthropic, comme d'autres entreprises d'IA, communique sur la sécurité et le contrôle de son code. L'incident du 31 mars montre que ce contrôle n'est jamais absolu — il dépend de processus humains qui peuvent échouer. C'est une leçon d'humilité pour toute l'industrie, et pas seulement pour Anthropic.
Pour aller plus loin sur ces tensions entre IA ouverte et fermée, notre analyse sur DeepSeek v4 vs GPT-5.5 et la guerre de l'IA ouverte contre fermée en 2026 explore ces dynamiques en profondeur.
Que nous apprend la fuite de Claude Code sur la sécurité des projets npm en 2026 ?
Les équipes sécurisent ce qu'elles voient. Jamais ce qu'elles oublient.
C'est la leçon centrale de cet incident, et elle se décline en plusieurs vecteurs d'exposition qui se répètent sur les projets que j'audite régulièrement.
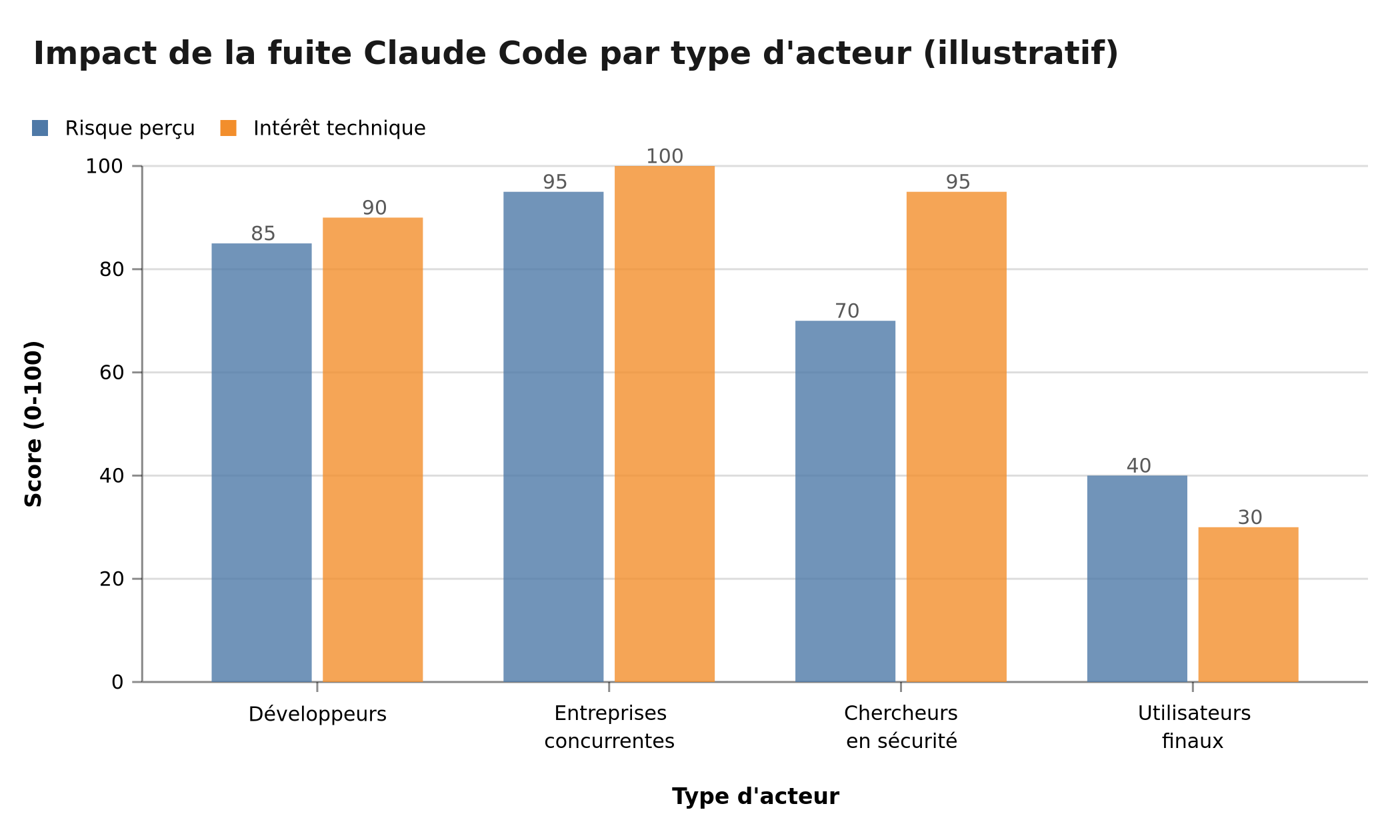 Comparaison du risque perçu et de l'intérêt technique par type d'acteur suite à la fuite Claude Code (données illustratives)
Comparaison du risque perçu et de l'intérêt technique par type d'acteur suite à la fuite Claude Code (données illustratives)
1. Les fichiers de build oubliés
Source maps, fichiers .env.example avec de vraies valeurs, artefacts de CI/CD. Ils traînent en production parce que personne ne vérifie systématiquement le contenu des packages publiés. La convention dans l'industrie est de lister les fichiers à exclure dans .npmignore ou dans le champ files de package.json — mais ces listes sont rarement exhaustives et jamais vérifiées automatiquement.
Solution : pipeline de validation automatisée avant chaque publish. Une étape pre-publish qui scanne les extensions .map, .env, .log dans le bundle de sortie. Cette étape doit être bloquante — c'est-à-dire qu'elle doit empêcher la publication si elle détecte un fichier problématique, et non se contenter de générer un avertissement que personne ne lira.
2. Les variables d'environnement dans les dépôts
Un commit rapide, une clé API dans un commentaire, des credentials dans un fichier de configuration versionné. GitHub a des outils de détection, mais ils arrivent après la publication. Les vulnerabilités OWASP les plus critiques en 2025 classent d'ailleurs la mauvaise gestion des credentials parmi les risques prioritaires.
Solution : hooks pre-commit avec git-secrets ou detect-secrets. Systématiques, pas optionnels. La détection doit se faire avant le commit, pas après.
3. L'absence de processus de release formalisé
Sans checklist de release formalisée, chaque déploiement est une improvisation. Et l'improvisation génère des oublis. La version 2.1.88 d'Anthropic a probablement été publiée dans un contexte de pression temporelle ou par un développeur qui n'était pas au fait de la configuration de build.
Solution : automatiser les releases avec des outils comme n8n ou GitHub Actions. Chaque étape est documentée, chaque check est traçable. L'automatisation ne remplace pas la vigilance humaine — elle la complète en s'assurant que les étapes critiques ne peuvent pas être sautées.
La gestion d'un incident de publication accidentelle : ce qu'il faut faire dans les premières heures
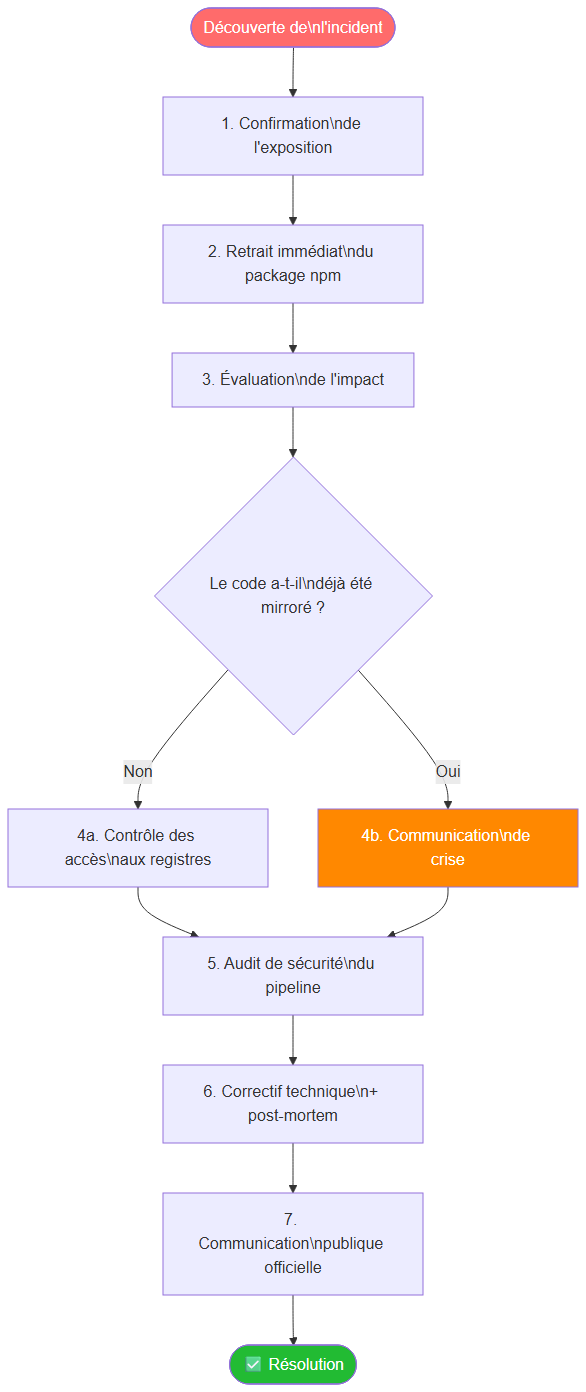
Lorsqu'une publication accidentelle est découverte, chaque minute compte. La réponse d'Anthropic a été rapide, mais le délai entre la publication et la correction a suffi pour que le code soit mirrored sur des plateformes tierces.
 Processus de réponse à incident : les 7 étapes d'une gestion efficace d'une publication accidentelle
Processus de réponse à incident : les 7 étapes d'une gestion efficace d'une publication accidentelle
La première étape est la confirmation. Avant toute action, il faut vérifier que l'exposition est réelle et évaluer son périmètre exact. Quelle version est concernée ? Depuis combien de temps est-elle disponible ? Quels fichiers sont exposés ?
La deuxième étape est le retrait immédiat. npm permet aux auteurs de packages de "déprécier" ou de retirer des versions. Cette action doit être effectuée en priorité, mais en sachant qu'elle ne supprime pas les copies déjà téléchargées.
La troisième étape est l'évaluation de la propagation. Combien de téléchargements a reçu la version concernée ? Le code a-t-il été mirrored ? Ces informations orientent la stratégie de communication.
La quatrième étape est la communication. Une publication accidentelle bien gérée peut se transformer en démonstration de maturité opérationnelle. Anthropic a communiqué publiquement sur l'incident, ce qui est la bonne approche. Le silence, à l'inverse, génère de la méfiance et laisse la place aux spéculations.
La cinquième étape est le post-mortem. Pas pour trouver un coupable, mais pour identifier précisément quel défaut de processus a permis l'erreur — et comment le corriger définitivement.
Les implications pour la confiance dans les outils d'IA
Au-delà de la dimension technique, cet incident soulève une question plus large : comment les entreprises qui construisent des outils d'IA maintiennent-elles la confiance de leurs utilisateurs après ce type d'incident ?
Claude Code est utilisé par des équipes de développement dans des entreprises qui lui confient du code propriétaire, des clés d'API, des logiques métier sensibles. La confiance dans un outil d'IA ne se limite pas à la performance du modèle — elle englobe la confiance dans les pratiques opérationnelles de l'entreprise qui le développe.
L'incident Anthropic n'expose pas de données utilisateurs. La fuite concerne le code source de leur propre outil, pas les données de leurs clients. Mais il révèle que les processus internes d'une entreprise valorisée à plusieurs dizaines de milliards de dollars peuvent présenter des failles basiques dans leur pipeline de publication.
Cette réalité est également visible dans la manière dont Anthropic positionne Claude sur des sujets sensibles. Notre analyse de la position d'Anthropic face au Pentagone et aux utilisations militaires de l'IA montre une entreprise qui réfléchit soigneusement à l'usage de sa technologie — mais qui, comme toute organisation humaine, reste vulnérable aux erreurs opérationnelles.
Si Anthropic peut oublier un fichier .map...
Anthropic est une entreprise valorisée à plusieurs dizaines de milliards de dollars, avec des équipes de sécurité dédiées, une infrastructure de classe mondiale, et une culture d'ingénierie reconnue dans l'industrie. Et pourtant, un fichier de débogage a failli tout compromettre — et dans une certaine mesure, l'a fait.
La leçon n'est pas que cette équipe était incompétente. La leçon est que les processus manuels échouent toujours, tôt ou tard. La pression des deadlines, la rotation des équipes, la complexité croissante des pipelines de build — tous ces facteurs créent des conditions dans lesquelles les erreurs humaines deviennent inévitables.
Ce n'est pas un problème de compétence. C'est un problème de systèmes.
Les équipes qui survivent longtemps sans incident de sécurité majeur ne sont pas celles qui ont des développeurs plus vigilants. Ce sont celles qui ont construit des systèmes qui rendent les erreurs difficiles à commettre — ou qui les détectent et les bloquent automatiquement avant qu'elles atteignent la production.
La fuite Claude Code npm Anthropic 2026 est un rappel brutal que dans l'industrie logicielle, la sécurité n'est pas un état qu'on atteint. C'est une pratique qu'on maintient, à travers des processus automatisés, des audits réguliers et une culture qui normalise la vérification plutôt que la confiance aveugle.
Pour aller plus loin sur l'automatisation de la sécurité dans vos pipelines de déploiement, consultez notre guide sur les bombes à retardement dans la sécurité des déploiements automatiques.
Perspectives : ce qui change après la fuite
Six mois après l'incident, plusieurs évolutions sont à noter dans l'industrie. La communauté npm a renforcé ses recommandations autour de la validation des packages avant publication. Des outils comme npm pack --dry-run — qui simule une publication sans la réaliser — ont été redécouverts et mis en avant comme pratique standard. Des solutions tierces de scanning de packages pré-publication ont également gagné en adoption.
Du côté d'Anthropic, les fonctionnalités révélées par la fuite ont depuis commencé à être déployées ou évoquées publiquement. KAIROS et autoDream ont été mentionnés dans des communications officielles, ce qui suggère que le calendrier de déploiement a peut-être été accéléré par la révélation accidentelle.
L'incident a également relancé le débat sur la transparence dans le développement des outils d'IA. Les développeurs qui utilisent Claude Code au quotidien ont eu une occasion rare de voir comment l'outil qu'ils utilisent est construit. Certains ont été rassurés par la qualité de l'architecture. D'autres ont été surpris par l'existence de fonctionnalités non documentées.
Ce que cette fuite révèle en dernière analyse, c'est moins un échec d'Anthropic qu'une vérité universelle sur le développement logiciel à grande échelle : la complexité génère des angles morts. La vigilance humaine ne suffit pas à les couvrir tous. L'automatisation est la seule réponse scalable — mais elle aussi doit être conçue, testée et maintenue.
Qu'est-ce qui dort en ce moment dans votre infrastructure ?
Chez BOVO Digital, nous construisons les automatisations et les processus qui empêchent ces erreurs — avant qu'elles coûtent cher.
Étiquettes
FAQ
La fuite Claude Code npm Anthropic 2026 était-elle accidentelle ou intentionnelle ?
Elle était entièrement accidentelle. La version 2.1.88 du package npm @anthropic-ai/claude-code contenait un fichier source map (.map) de débogage oublié lors de la publication. Ce fichier pointait vers un bucket R2 stockant le code TypeScript non obfusqué d'Anthropic. Aucun hack n'a été impliqué : c'est une erreur de processus de publication.
Qu'est-ce qu'un fichier source map et pourquoi est-il dangereux en production ?
Un fichier source map (.map) fait le lien entre le code JavaScript/TypeScript compilé et minifié et le code source original lisible. Il est indispensable en développement pour déboguer, mais en production il révèle l'architecture interne, les noms de variables, la logique métier et parfois des commentaires sensibles. Le laisser dans un package publié publiquement revient à livrer les plans d'un coffre-fort avec le coffre-fort.
Quelles fonctionnalités cachées de Claude Code la fuite a-t-elle révélées ?
Selon les rapports publiés suite à l'incident, la fuite a exposé plusieurs fonctionnalités non annoncées : KAIROS (un mode démon pour exécution en arrière-plan), autoDream (un système de consolidation de mémoire), BUDDY (un easter egg sous forme d'animal virtuel numérique), ainsi qu'un système de mémoire en trois couches via MEMORY.md. Les noms internes des modèles — Capybara, Fennec et Numbat — ont également été découverts.
Comment Anthropic a-t-il réagi à la fuite du code source de Claude Code ?
Anthropic a réagi rapidement en supprimant le fichier source map incriminé et en retirant les anciennes versions du package du registre npm. Cependant, comme le code avait déjà été téléchargé et mirrored sur GitHub dans les heures suivant la découverte, la suppression n'a pas pu effacer toutes les copies. La fuite était d'ailleurs la deuxième en cinq jours, après une mauvaise configuration CMS le 26 mars 2026.
Quelles leçons tirer pour la sécurité de la supply chain npm ?
L'incident Anthropic illustre trois angles morts fréquents : l'absence de scan automatique des artefacts de build avant publication, l'inexistence de pipeline pre-publish vérifiant les extensions sensibles (.map, .env, .log), et l'absence d'audit post-publication. La solution passe par l'automatisation systématique de ces contrôles dans la CI/CD plutôt que par la vigilance humaine, qui finit toujours par faillir.
Quel est l'impact concret de cette fuite pour les concurrents d'Anthropic ?
La fuite a exposé l'architecture interne de Claude Code, ses outils agents, ses commandes slash et ses fonctionnalités non publiées. Les entreprises concurrentes ont eu accès à des informations qui leur auraient normalement demandé des années de reverse engineering. L'impact est difficile à quantifier précisément, mais compte tenu des 2,5 milliards de dollars de revenus annualisés générés par Claude Code, la valeur stratégique de l'information exposée était considérable.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
William Aklamavo
Expert en développement web et automatisation, passionné par l'innovation technologique et l'entrepreneuriat digital.


