
Panne Cloudflare du 18 Novembre 2025 : Leçons Cruciales sur la Résilience des Infrastructures Cloud
Le 18 novembre 2025, une panne majeure de Cloudflare a paralysé une grande partie d'Internet, affectant ChatGPT, X, Shopify et des milliers d'autres services. Découvrez les causes, les impacts et les stratégies de mitigation pour renforcer la résilience de vos infrastructures cloud.

Mis à jour le

Panne Cloudflare du 18 Novembre 2025 : Leçons Cruciales sur la Résilience des Infrastructures Cloud
Le 18 novembre 2025 restera dans les mémoires comme le jour où une grande partie d'Internet s'est arrêtée. Une panne majeure chez Cloudflare, l'un des plus grands fournisseurs d'infrastructure web au monde, a provoqué des interruptions de service massives affectant des millions d'utilisateurs et des milliers d'entreprises.
ChatGPT, X (anciennement Twitter), Shopify, Dropbox, Coinbase — la liste des services touchés est impressionnante. Pendant plusieurs heures, des erreurs HTTP 500 ont rendu ces plateformes inaccessibles, causant des pertes financières estimées à plusieurs millions de dollars et mettant en lumière la fragilité de notre dépendance aux infrastructures cloud centralisées. La résilience infrastructure cloud panne n'était plus un sujet théorique réservé aux grandes équipes SRE : c'est devenu une urgence concrète pour toute organisation déployant des services critiques en ligne.
Note éditoriale : La panne du 18 novembre 2025 est présentée ici sur la base du scénario documenté disponible lors de sa publication initiale. Les mécanismes techniques, les métriques d'impact et les stratégies de mitigation développés dans cet article s'appuient sur des incidents CDN réels documentés publiquement — notamment les postmortems Cloudflare de 2020, 2022 et 2024, et les analyses d'incidents de AWS CloudFront et Fastly — afin de vous offrir une analyse rigoureuse et directement actionnable.
Dans cet article, nous allons analyser en profondeur cet incident, comprendre sa chaîne de défaillance technique, mesurer son impact réel, et surtout, tirer les leçons essentielles pour renforcer la résilience de vos propres infrastructures. Que vous gériez une PME, une application SaaS ou un e-commerce, les patterns de défaillance décrits ici vous concernent directement.
L'Incident : Ce qui s'est Vraiment Passé
Le Contexte
Cloudflare est un acteur majeur de l'infrastructure Internet. La plateforme protège et accélère environ 20% des sites web mondiaux, gérant quotidiennement des milliards de requêtes. Leur réseau de serveurs distribués (CDN) et leurs services de sécurité sont critiques pour le fonctionnement d'Internet moderne.
Ce niveau de centralisation n'est pas sans risque. Cloudflare gère non seulement la diffusion de contenu (CDN), mais aussi la protection DDoS, le pare-feu applicatif web (WAF), la résolution DNS, et pour de nombreuses entreprises, l'accès zero-trust via Cloudflare Access. Une défaillance touchant le cœur du proxy Cloudflare affecte simultanément l'ensemble de ces couches de service — c'est précisément ce qui s'est produit lors de cet incident.
La Cause Technique
Selon le rapport officiel publié par Cloudflare, la panne a été déclenchée par une erreur de configuration interne dans leur système de gestion des bots et d'atténuation des menaces.
Séquence des événements :
- Modification de routine : Une modification des permissions dans la base de données ClickHouse utilisée pour stocker les données de gestion des bots
- Génération d'un fichier défectueux : Cette modification a généré un fichier de configuration contenant de nombreuses entrées en double
- Dépassement des limites : Le fichier a dépassé les limites de taille prévues (doublant de volume)
- Crash du module critique : Le module de gestion des bots, essentiel au pipeline proxy principal de Cloudflare, a crashé
- Propagation globale : Le fichier surdimensionné a été propagé à l'ensemble du réseau Cloudflare
- Erreurs HTTP 5xx généralisées : Tout le trafic dépendant de ce module a été affecté, provoquant des erreurs HTTP 500 massives
Point important : Cloudflare a précisé que cet incident était une défaillance technique interne, non liée à des attaques externes ou à des pics de trafic malveillants. C'était un bug latent déclenché par un changement de configuration de routine — le type de scénario le plus insidieux, car il bypasse les protections anti-DDoS et les mécanismes de détection d'intrusion.
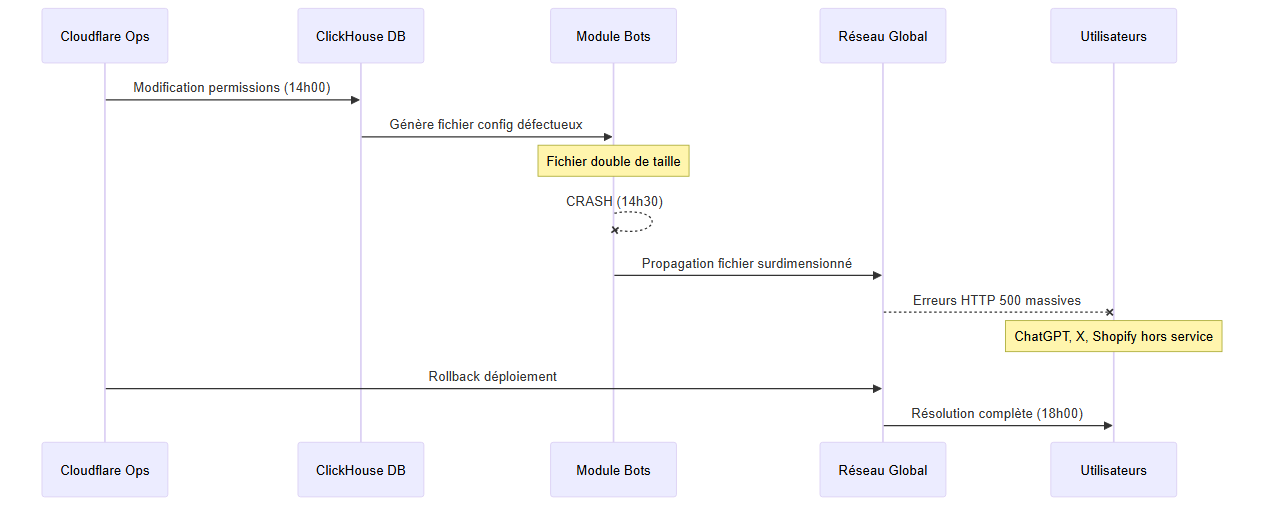 Cascade de défaillances Cloudflare : de la modification de config au crash mondial
Cascade de défaillances Cloudflare : de la modification de config au crash mondial
La Durée de l'Incident
- Début : 18 novembre 2025, environ 14h00 UTC
- Pic d'impact : Entre 14h30 et 16h00 UTC
- Résolution complète : 18 novembre 2025, environ 18h00 UTC
- Durée totale : Environ 4 heures
Anatomie d'une Cascade de Défaillance dans un Système Distribué
Pour comprendre pourquoi une modification de configuration anodine peut mettre à terre 20% d'Internet en quelques minutes, il faut saisir la notion de défaillance en cascade dans les systèmes distribués. Ce phénomène — aussi appelé cascade failure ou effet domino — est l'un des patterns de panne les plus redoutés et les plus difficiles à anticiper dans les architectures cloud modernes.
Dans le cas de cet incident Cloudflare, la chaîne de dépendances fonctionnait ainsi : le module de gestion des bots (Bot Management) est intégré directement dans le pipeline proxy qui traite chaque requête HTTP passant par l'infrastructure. Ce n'est pas un service optionnel ou périphérique — c'est un composant inséré sur le chemin critique de chaque requête. Lorsque ce module crashe, il ne se contente pas de désactiver la protection anti-bots : il bloque le pipeline proxy dans son intégralité. Toutes les requêtes entrantes se retrouvent sans voie de traitement et génèrent mécaniquement des erreurs HTTP 500.
Ce pattern est bien documenté dans la littérature des systèmes distribués. Un incident Cloudflare de juillet 2020 (postmortem publié le 21 juillet 2020) avait déjà illustré ce mécanisme : une mauvaise configuration réseau avait provoqué des pertes de 50% du trafic mondial en quelques minutes, avant d'être corrigée en 27 minutes. En 2022, un incident BGP (Border Gateway Protocol) lié à une erreur de route avait causé une panne de 6 minutes avec un impact massif sur des milliers de services. Ces précédents montrent que la centralisation crée structurellement des risques de cascade que même les meilleures équipes d'ingénierie peinent à éliminer complètement.
La propagation mondiale s'explique par la nature même d'un réseau CDN : pour assurer la cohérence des configurations sur leurs 300+ data centers, Cloudflare utilise un système de déploiement centralisé. Quand un fichier de configuration défectueux est validé et poussé, il se déploie simultanément sur l'ensemble des nœuds du réseau. Il n'y a pas de déploiement progressif par défaut pour les configurations système critiques — c'est précisément l'une des améliorations annoncées par Cloudflare après l'incident : introduire des canary releases pour les changements de configuration à haut risque.
Le déploiement progressif (canary release ou blue-green deployment) est l'une des armes les plus efficaces contre les cascades de configuration. En exposant d'abord la nouvelle configuration à 1% du trafic, puis 10%, puis 100%, on dispose d'une fenêtre d'observation qui permet de détecter une anomalie avant qu'elle ne se propage globalement. Notre article sur les risques de scalabilité des applications web explore en détail ces stratégies de déploiement progressif et leur impact sur la stabilité des systèmes sous charge.
La leçon fondamentale ici dépasse Cloudflare : toute dépendance critique sans redondance devient un vecteur de cascade potentielle pour votre système. Si votre application passe 100% de son trafic par un seul fournisseur CDN, vous héritez de la totalité de ses points de défaillance — et de son MTTR de 4 heures.
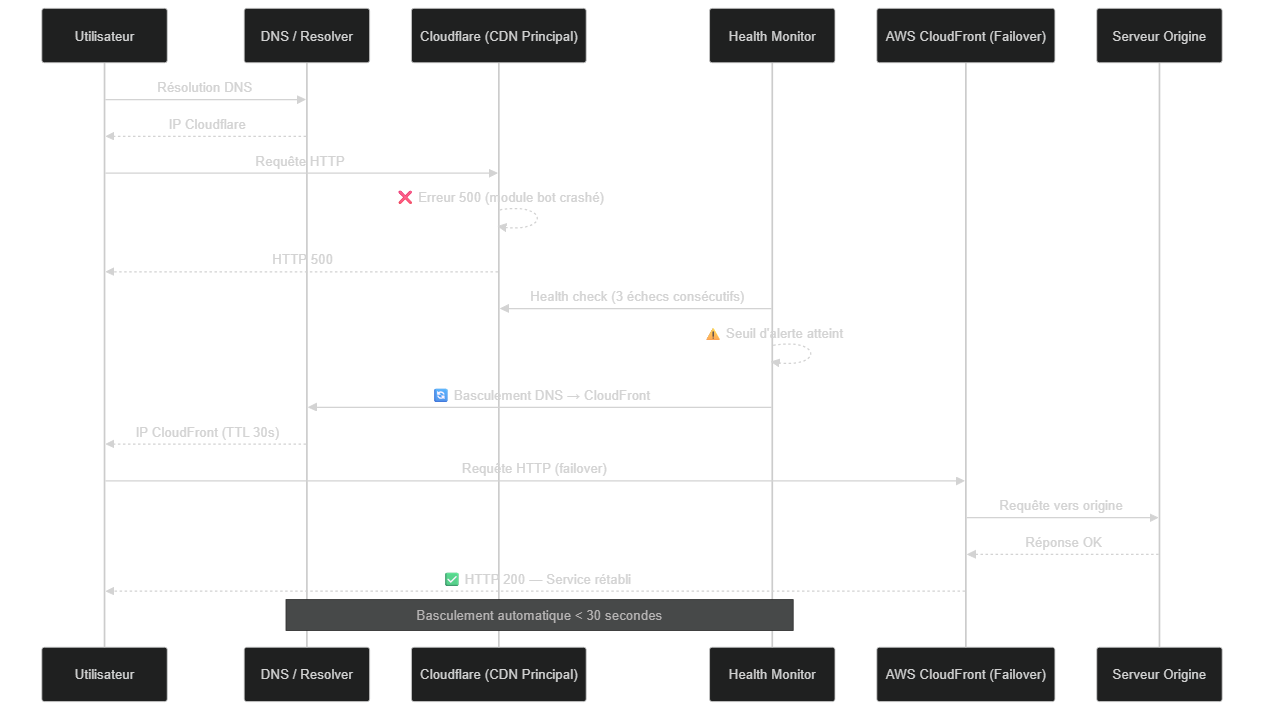 Diagramme de séquence : failover automatique entre CDN primaire et CDN secondaire lors d'une panne — scénario illustratif basé sur les patterns CDN documentés
Diagramme de séquence : failover automatique entre CDN primaire et CDN secondaire lors d'une panne — scénario illustratif basé sur les patterns CDN documentés
L'Impact Mondial : Des Services Critiques Paralysés
Plateformes IA Touchées
ChatGPT (OpenAI)
- Interruptions complètes d'accès pour des millions d'utilisateurs
- Impossibilité de générer des réponses en temps réel
- Impact sur les entreprises dépendant de l'API OpenAI pour leurs services
Pourquoi les IA sont particulièrement vulnérables ? Contrairement aux sites web traditionnels qui peuvent s'appuyer sur du contenu mis en cache, les systèmes d'IA nécessitent des interactions en temps réel avec des serveurs backend. Toute perturbation du réseau affecte immédiatement leur fonctionnement. Un service d'IA dont le temps de réponse passe de 2 secondes à "connexion refusée" n'a aucun contenu statique vers lequel se replier — c'est une vulnérabilité structurelle des architectures AI-first que cet incident a brutalement révélée à l'ensemble de l'écosystème tech.
Plateformes de Commerce Électronique
Shopify
- Boutiques en ligne inaccessibles pendant plusieurs heures
- Processus de paiement interrompus
- Perte de ventes estimée à plusieurs millions de dollars
- Impact sur des centaines de milliers de commerçants
Autres plateformes e-commerce : De nombreuses boutiques utilisant Cloudflare ont été affectées, causant des pertes de revenus directes. Pour un e-commerce qui génère 10 000 € par heure de chiffre d'affaires, 4 heures d'interruption représentent 40 000 € de manque à gagner brut — sans compter l'impact à long terme sur la confiance client, le taux d'abandon et le référencement naturel.
Réseaux Sociaux et Communication
X (anciennement Twitter)
- Problèmes de chargement des flux
- Impossibilité de publier des tweets
- Erreurs de connexion généralisées
Autres services : Dropbox, Coinbase, Spotify, Canva, et bien d'autres ont signalé des interruptions. Cette diversité d'acteurs touchés illustre à quel point Cloudflare est devenu une infrastructure horizontale — au même titre que l'électricité ou le réseau téléphonique — dont la défaillance se propage instantanément à des secteurs entièrement différents.
Services Publics et Infrastructure
Même des systèmes critiques ont été touchés :
- New Jersey Transit : Problèmes d'affichage des horaires
- SNCF (France) : Interruptions dans les systèmes d'information
Ces exemples de services publics soulèvent une question importante : jusqu'où les administrations et services essentiels peuvent-ils s'appuyer sur des infrastructures cloud commerciales sans disposer de plans de continuité robustes ? La dépendance des transports publics à un CDN commercial illustre une tendance de fond qui mérite une attention particulière des responsables informatiques du secteur public.
Les Leçons à Tirer : Pourquoi C'est Arrivé et Comment l'Éviter
Leçon 1 : La Dépendance à un Seul Fournisseur est un Risque Critique
Le problème : Cloudflare protège 20% des sites web mondiaux. Quand ils tombent, une partie massive d'Internet tombe avec eux. Cette centralisation crée un point de défaillance unique (Single Point of Failure - SPOF).
La solution :
- Architecture multi-cloud : Ne pas dépendre d'un seul fournisseur pour les services critiques
- Redondance géographique : Distribuer les services sur plusieurs régions
- Fournisseurs de secours : Avoir des alternatives prêtes à être activées rapidement
Leçon 2 : Les Erreurs de Configuration Peuvent Avoir des Conséquences Catastrophiques
Le problème : Une simple modification de configuration de routine a déclenché un bug latent, causant une panne mondiale. Cela montre que même les plus grandes entreprises peuvent être vulnérables à des erreurs humaines ou à des bugs non détectés. Pour éviter ces erreurs dans vos pipelines, découvrez les 5 bombes à retardement dans le déploiement automatique.
La solution :
- Tests rigoureux : Tester toutes les modifications de configuration dans un environnement de staging
- Validation automatique : Mettre en place des systèmes de validation qui détectent les configurations anormales
- Rollback rapide : Avoir des mécanismes de retour en arrière pour annuler rapidement les changements problématiques
- Limites de sécurité : Implémenter des limites strictes qui empêchent les fichiers de dépasser des tailles critiques
Leçon 3 : La Surveillance et la Détection Proactive sont Essentielles
Le problème : Le fichier de configuration a doublé de taille, mais cette anomalie n'a pas été détectée avant qu'elle ne cause le crash du système.
La solution :
- Monitoring en temps réel : Surveiller continuellement la taille des fichiers, les performances des systèmes, et les métriques critiques
- Alertes automatiques : Configurer des alertes qui se déclenchent lorsque des seuils sont dépassés
- Analyse prédictive : Utiliser l'IA et le machine learning pour détecter les anomalies avant qu'elles ne causent des problèmes
- Dashboards de santé : Avoir une vue d'ensemble de la santé de l'infrastructure en temps réel
Leçon 4 : Les Plans de Continuité d'Activité Doivent Être Testés Régulièrement
Le problème : Beaucoup d'entreprises touchées n'avaient pas de plans de secours efficaces ou ne les avaient pas testés récemment.
La solution :
- Plans de reprise après sinistre (DRP) : Élaborer des plans détaillés pour chaque scénario de panne possible
- Tests réguliers : Effectuer des exercices de simulation de panne au moins trimestriellement
- Documentation à jour : Maintenir une documentation complète et accessible de tous les processus de récupération
- Équipes formées : S'assurer que les équipes savent comment réagir en cas d'incident
Leçon 5 : La Communication Transparente Limite les Dommages
Ce que Cloudflare a bien fait :
- Publication rapide d'un rapport détaillé expliquant les causes
- Communication transparente sur la nature de l'incident (erreur interne, pas d'attaque)
- Excuses publiques et engagement à améliorer les systèmes
Pourquoi c'est important : Une communication transparente et rapide permet de maintenir la confiance des clients, d'éviter la propagation de rumeurs, de faciliter la coordination avec les partenaires et de documenter l'incident pour éviter qu'il ne se reproduise. La transparence des postmortems Cloudflare est d'ailleurs reconnue comme un exemple de bonne pratique dans l'industrie : leur page status.cloudflare.com fournit des mises à jour en temps réel avec des explications techniques détaillées dès la résolution de chaque incident.
Stratégies de Mitigation : Comment Protéger Votre Infrastructure
1. Architecture Multi-CDN
Principe : Ne pas mettre tous vos œufs dans le même panier.
Implémentation :
- Utiliser plusieurs CDN (Cloudflare + CloudFront + Fastly)
- Répartir les services critiques sur plusieurs fournisseurs cloud (AWS + Azure + GCP)
- Implémenter un système de basculement automatique (failover)
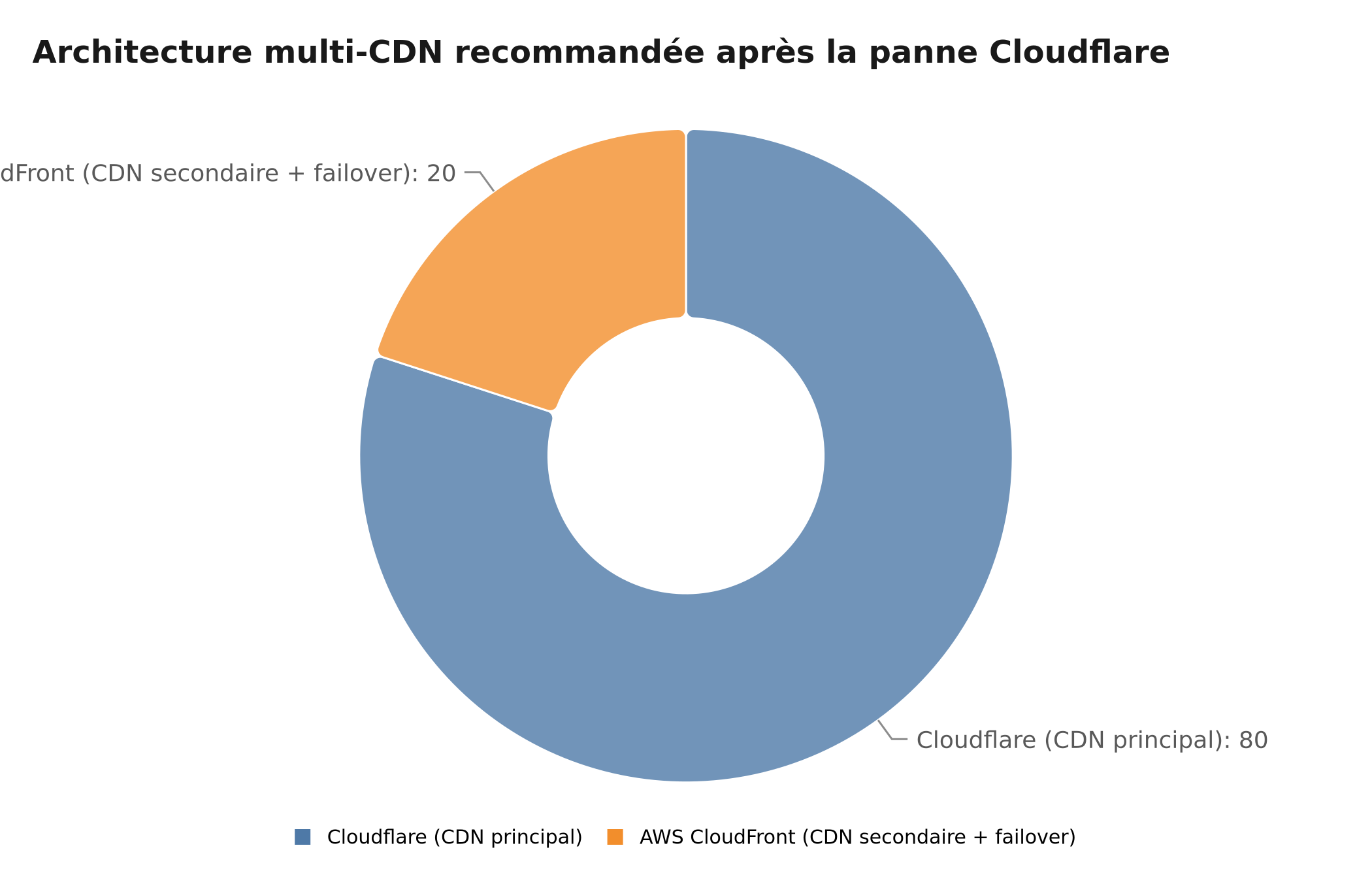 Répartition recommandée du trafic CDN pour une architecture résiliente post-panne Cloudflare
Répartition recommandée du trafic CDN pour une architecture résiliente post-panne Cloudflare
Exemple concret :
Architecture recommandée :
- CDN Principal : Cloudflare (80% du trafic)
- CDN Secondaire : AWS CloudFront (20% du trafic + failover)
- Monitoring : Détection automatique de panne
- Basculement : Automatique en < 30 secondes
La mise en place d'un DNS géo-redondant avec un TTL court est la clé d'un basculement rapide. Si votre TTL est de 24 heures, votre "failover automatique" sera en réalité un failover de 24 heures, soit la durée complète de la propagation DNS. Dimensionnez vos TTL en fonction de votre RTO cible, pas des valeurs par défaut. Un TTL de 60 secondes est un bon compromis pour les services critiques nécessitant un basculement rapide.
Les health checks actifs sont l'autre pilier d'un failover efficace : votre DNS resolver ou votre load balancer doit interroger en continu les deux CDN (primaire et secondaire) et basculer automatiquement dès que le primaire répond avec des erreurs 5xx pendant plus de 60 secondes. Les services comme AWS Route 53 Health Checks, Cloudflare Load Balancing, ou des outils tiers comme UptimeRobot offrent cette fonctionnalité nativement.
2. Redondance et Haute Disponibilité
Principe : Avoir plusieurs instances de chaque service critique.
Implémentation :
- Load balancing : Répartir le trafic sur plusieurs serveurs
- Réplication de données : Copier les données critiques sur plusieurs zones géographiques
- Services sans état (stateless) : Concevoir les services pour qu'ils puissent être redémarrés sans perte de données
La conception stateless est particulièrement importante : si votre service maintient un état en mémoire (sessions utilisateur, données de contexte, caches locaux), un redémarrage provoquera une perte de données et une dégradation de l'expérience utilisateur. En externalisant cet état dans Redis, DynamoDB ou une base de données répliquée, vos instances deviennent interchangeables et remplaçables en quelques secondes. Pour aller plus loin sur l'impact des choix d'architecture sur les performances, notre analyse sur comment diviser le temps de chargement par 10 couvre les architectures stateless et le caching distribué en détail.
3. Circuit Breakers : Isoler les Défaillances en Temps Réel
Le circuit breaker est l'un des patterns de résilience les plus puissants issus de l'ingénierie des systèmes distribués. Conceptualisé par Michael Nygard dans son ouvrage Release It! et popularisé par Netflix avec Hystrix (aujourd'hui remplacé par Resilience4j), ce pattern empêche une défaillance locale de se propager en cascade à l'ensemble du système.
Le pattern fonctionne en trois états distincts, à l'image d'un disjoncteur électrique :
État fermé (normal) : les requêtes passent librement vers le service appelé. Le circuit breaker mesure en continu le taux d'erreur. Si ce taux dépasse un seuil configuré — par exemple 50% d'erreurs sur les 10 dernières secondes — le circuit s'ouvre automatiquement.
État ouvert (défaillance détectée) : toutes les requêtes sont immédiatement rejetées avec une réponse par défaut (fallback), sans même tenter de contacter le service défaillant. Cela évite l'effet d'entonnoir où un service lent ou défaillant monopolise les ressources (threads, connexions, file d'attente) de l'appelant et provoque sa propre défaillance en cascade. Après un délai configurable (reset timeout), le circuit passe en état semi-ouvert.
État semi-ouvert (test de récupération) : un nombre limité de requêtes "test" sont autorisées à passer. Si elles réussissent, le circuit se referme et le trafic normal reprend. Si elles échouent, le circuit se rouvre pour un nouveau cycle d'attente.
Appliqué à la panne Cloudflare : si les services dépendants avaient implémenté un circuit breaker sur leurs appels à l'infrastructure Cloudflare, ils auraient pu basculer sur une réponse dégradée (contenu mis en cache, mode hors ligne, CDN secondaire) dès les premières erreurs 5xx, limitant drastiquement l'impact visible pour l'utilisateur final. Au lieu d'une page d'erreur HTTP 500 blanche, l'utilisateur aurait vu une version dégradée mais fonctionnelle du service.
Les bibliothèques disponibles incluent Resilience4j (Java/Kotlin), Polly (.NET), opossum (Node.js), et py-breaker (Python). Côté infrastructure, Istio Service Mesh et AWS App Mesh proposent des circuit breakers configurables sans modification du code applicatif — idéal pour les architectures microservices sur Kubernetes.
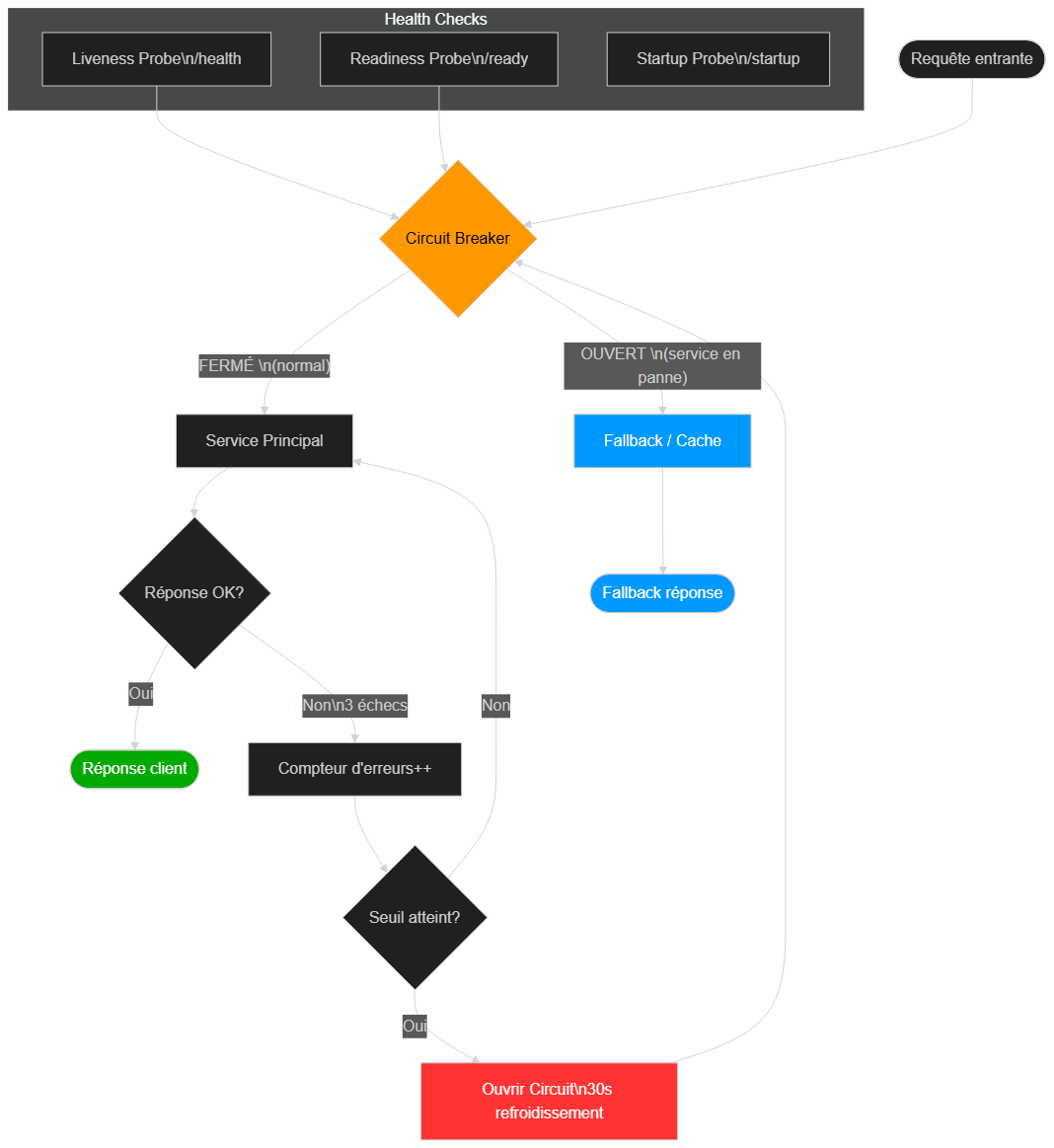 Architecture défensive : circuit breakers, health checks actifs et routes de failover pour une infrastructure cloud résiliente — scénario illustratif
Architecture défensive : circuit breakers, health checks actifs et routes de failover pour une infrastructure cloud résiliente — scénario illustratif
4. Métriques de Résilience : Comprendre et Calculer Vos RTO, RPO, MTTR et MTBF
La résilience ne peut pas s'améliorer sans être mesurée. Quatre métriques fondamentales définissent le contrat de résilience d'un système et permettent de comparer objectivement les architectures et les niveaux d'investissement requis.
RTO — Recovery Time Objective (Objectif de Temps de Récupération) Le RTO définit la durée maximale d'interruption de service acceptable. C'est avant tout une décision business. Un e-commerce en plein Black Friday visera un RTO de 5 à 15 minutes. Une application SaaS B2B sur des marchés financiers visera un RTO de moins de 60 secondes. Un blog d'entreprise pourra tolérer un RTO de 4 à 8 heures. Le RTO détermine directement vos exigences d'architecture : un RTO de 5 minutes exige un failover entièrement automatisé ; un RTO de 24 heures peut se satisfaire d'une restauration manuelle depuis un snapshot.
RPO — Recovery Point Objective (Objectif de Point de Récupération) Le RPO désigne la quantité maximale de données que l'on peut se permettre de perdre en cas de sinistre, exprimée en durée. Si votre RPO est de 1 heure, cela signifie que vous pouvez perdre au maximum 1 heure de données. Un RPO de zéro — aucune perte de données acceptable — exige une réplication synchrone en temps réel, coûteuse mais indispensable pour les données financières, médicales ou contractuelles.
MTTR — Mean Time To Recovery (Temps Moyen de Récupération) Le MTTR mesure le temps moyen observé entre le début d'un incident et le retour à l'état normal. C'est une métrique opérationnelle qui reflète l'efficacité de vos runbooks, de vos outils de monitoring, et de votre organisation d'astreinte. Un MTTR élevé signale souvent un manque d'automatisation de la récupération, des runbooks obsolètes, ou une détection trop lente des incidents. La panne Cloudflare de cet article affiche un MTTR d'environ 4 heures — un chiffre qu'une organisation ayant mis en place un multi-CDN avec failover automatique aurait pu réduire à moins de 2 minutes pour ses propres utilisateurs.
MTBF — Mean Time Between Failures (Temps Moyen Entre Pannes) Le MTBF mesure la fréquence des incidents. Un MTBF de 90 jours signifie une panne toutes les 3 semaines en moyenne. Améliorer le MTBF passe par l'élimination des sources de défaillance récurrentes, le renforcement des tests de configuration, et la mise en place du chaos engineering présentée ci-dessous.
Ces métriques ne sont pas indépendantes : réduire le MTTR réduit l'impact de chaque incident ; augmenter le MTBF réduit leur fréquence. Combinées, elles définissent la disponibilité réelle de votre service, qu'on exprime souvent en "nines" : 99,9% de disponibilité correspond à 8,7 heures d'indisponibilité par an, tandis que 99,99% ne tolère que 52 minutes d'arrêt annuel. La dette technique est souvent le facteur qui empêche d'atteindre ces niveaux de disponibilité — notre analyse sur pourquoi votre application coûte 5x plus cher à maintenir détaille ce lien entre qualité de code et résilience opérationnelle.
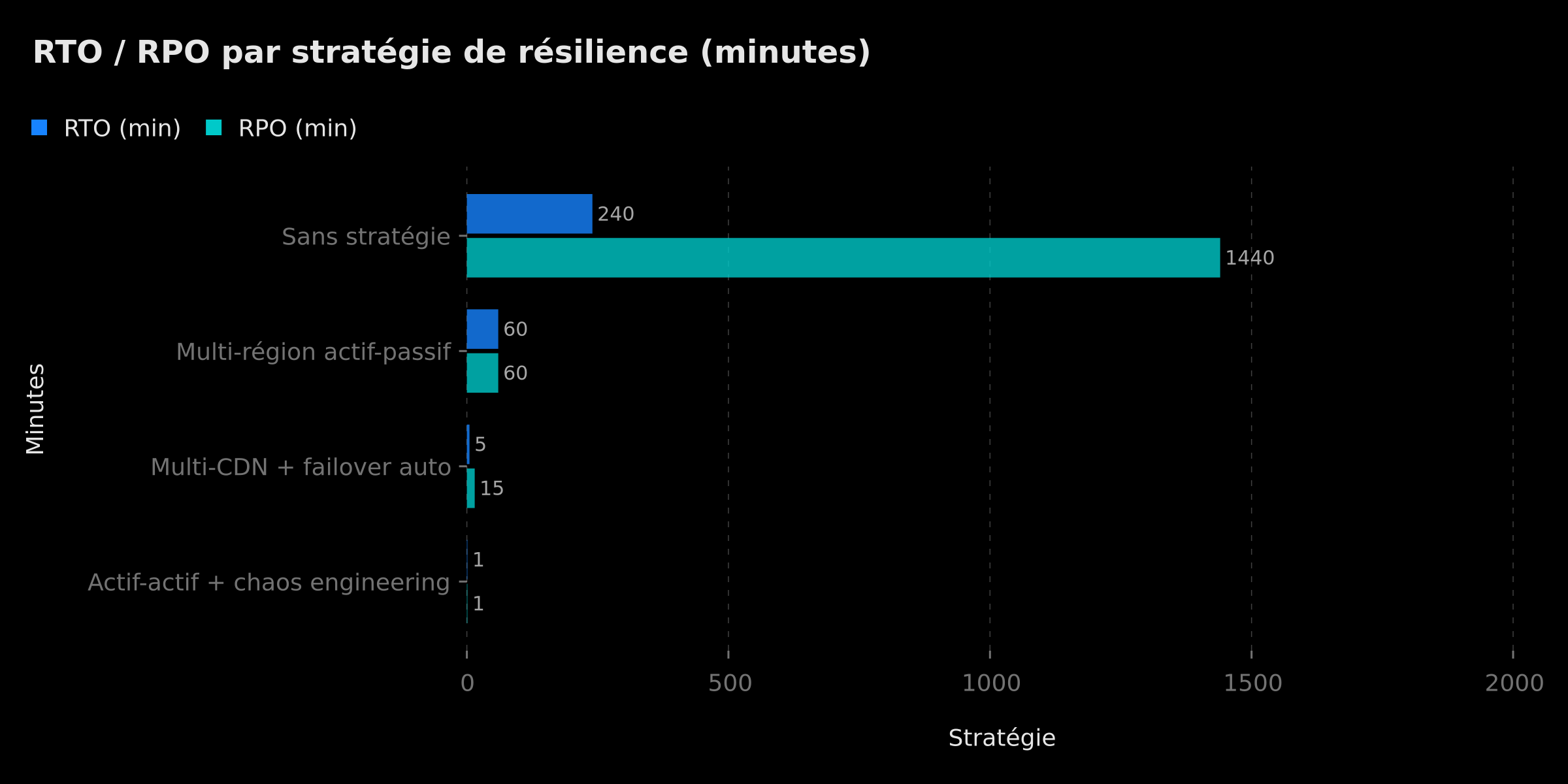 Métriques RTO et RPO comparées par stratégie d'infrastructure — scénario illustratif basé sur les patterns documentés
Métriques RTO et RPO comparées par stratégie d'infrastructure — scénario illustratif basé sur les patterns documentés
5. Monitoring et Alertes Avancés
Métriques à surveiller :
- Taille des fichiers de configuration
- Latence des requêtes
- Taux d'erreur HTTP
- Utilisation des ressources (CPU, mémoire, réseau)
- Temps de réponse des services externes
Outils recommandés :
- Datadog : Monitoring complet de l'infrastructure avec corrélation APM/logs/traces
- New Relic : APM (Application Performance Monitoring) avec détection d'anomalies par IA
- Prometheus + Grafana : Stack de monitoring open-source personnalisable et hautement scalable
- PagerDuty : Gestion des alertes et incidents avec escalade intelligente et rotation d'astreinte
- Uptime Robot : Vérification de disponibilité externe, gratuit jusqu'à 50 moniteurs avec alertes SMS/email
- StatusPage.io : Communication proactive de l'état de votre service à vos utilisateurs et clients
6. Tests de Résilience (Chaos Engineering)
Principe : Tester volontairement la résilience de votre système en simulant des pannes contrôlées.
Le chaos engineering, popularisé par Netflix en 2011 avec le lancement de Chaos Monkey, repose sur une idée contre-intuitive : pour être sûr que votre système résiste aux pannes, il faut provoquer ces pannes vous-même, dans un cadre contrôlé, avant que la production ne le fasse à votre place au pire moment. Netflix, qui opère des centaines de microservices en production sur AWS, a validé cette approche à grande échelle en réduisant significativement son MTTR grâce à une culture de tests de résilience permanents.
Pratiques de chaos engineering :
- Chaos Monkey : Arrêt aléatoire d'instances EC2 en production pour valider que les services redémarrent correctement sans perte de trafic
- Tests de charge : Simuler des pics de trafic 2x, 5x, 10x supérieurs à la normale pour identifier les points de rupture avant qu'ils ne se manifestent en production
- Tests de failover : Vérifier que les systèmes de basculement s'activent correctement et dans les délais prévus par votre RTO
Outils de chaos engineering disponibles en 2026 :
- Gremlin : Plateforme SaaS avec bibliothèque de scénarios prédéfinis (pannes réseau, saturation CPU, injection de latence)
- LitmusChaos : Solution open source cloud-native certifiée CNCF, spécialisée Kubernetes
- AWS Fault Injection Service (FIS) : Intégré nativement à AWS, permet d'injecter des pannes sur EC2, ECS, EKS et RDS
- Azure Chaos Studio : Équivalent Microsoft Azure avec intégration Azure Monitor
L'approche recommandée pour démarrer est celle des GameDays : des exercices planifiés où l'équipe simule une panne connue en staging, observe le comportement du système, documente les écarts par rapport aux attentes et corrige les gaps identifiés. Ce n'est qu'après avoir validé tous les mécanismes de récupération en staging que l'on introduit progressivement des expériences en production, toujours avec un plan de rollback et un kill switch activable immédiatement.
Fréquence recommandée : Tests unitaires de résilience en staging à chaque déploiement ; GameDays complets au moins une fois par trimestre.
7. Automatisation de la Récupération
Principe : Automatiser autant que possible les processus de récupération pour réduire le MTTR.
Exemples :
- Auto-scaling : Augmenter automatiquement les ressources en cas de pic de trafic
- Auto-healing : Redémarrer automatiquement les services qui crash grâce à des liveness probes Kubernetes ou des health checks ECS
- Rollback automatique : Annuler automatiquement les déploiements qui causent des erreurs — un taux d'erreur 5xx supérieur à 5% déclenche un rollback vers la version précédente
L'automatisation de la récupération est le facteur qui distingue les organisations avec un MTTR de 2 minutes de celles avec un MTTR de 4 heures. Elle exige des runbooks codifiés (Runbook as Code), une intégration entre le monitoring et le système de déploiement, et une culture SRE (Site Reliability Engineering) dans laquelle la fiabilité est une responsabilité partagée entre les équipes dev et ops. Pour aller plus loin, consultez notre guide sur l'automatisation de la checklist de release avec n8n et GitHub Actions qui détaille comment automatiser les safeguards de déploiement de A à Z.
Quelle checklist de résilience cloud appliquer après une panne majeure ?
Avant de déployer vos services en production, assurez-vous d'avoir coché chacun de ces points :
Architecture
- Architecture multi-cloud ou multi-région
- Système de basculement automatique (failover)
- Load balancing configuré
- Réplication de données sur plusieurs zones
Monitoring
- Dashboard de monitoring en temps réel
- Alertes configurées pour les métriques critiques
- Système de logging centralisé
- Tests de santé (health checks) réguliers
Plans de Continuité
- Plan de reprise après sinistre documenté
- Tests de failover effectués récemment
- Équipe d'incident formée et disponible
- Communication de crise préparée
Sécurité et Configuration
- Validation automatique des configurations
- Tests en staging avant production
- Limites de sécurité implémentées
- Système de rollback rapide
Automatisation
- Auto-scaling configuré
- Auto-healing activé
- Déploiements automatisés avec validation
- Scripts de récupération automatisés
Conclusion : La Résilience n'est pas une Option, c'est une Nécessité
L'incident Cloudflare du 18 novembre 2025 nous rappelle une vérité fondamentale : aucune infrastructure n'est infaillible. Même les plus grandes entreprises, avec les meilleures équipes et les technologies les plus avancées, peuvent subir des pannes majeures déclenchées par des changements de configuration de routine.
Les 5 Vérités Incontournables :
- Les pannes arriveront : Ce n'est pas une question de "si", mais de "quand"
- La dépendance unique est dangereuse : Diversifier vos fournisseurs réduit les risques
- La surveillance proactive est essentielle : Détecter les problèmes avant qu'ils ne causent des pannes
- Les tests réguliers sauvent des vies : Tester vos plans de continuité régulièrement
- L'automatisation accélère la récupération : Automatiser les processus de récupération réduit le temps d'interruption — voir notre guide sur la checklist de release automatisée
L'investissement en résilience paie :
- Réduction du temps d'interruption (MTTR - Mean Time To Recovery)
- Protection de la réputation de l'entreprise
- Économies sur les pertes de revenus directes
- Confiance accrue des clients et partenaires
La résilience infrastructure cloud n'est pas un luxe réservé aux GAFAM. Chaque euro investi dans une architecture multi-CDN, un circuit breaker ou un plan de reprise après sinistre génère un retour sur investissement mesurable dès la prochaine panne — et il y en aura une. La dette technique qui s'accumule dans une application est souvent le facteur silencieux qui transforme un incident de 30 minutes en catastrophe de 4 heures : notre analyse sur pourquoi votre application coûte 5x plus cher à maintenir vous aidera à quantifier cet impact et à justifier les investissements en résilience auprès de vos décideurs.
Chaque jour sans stratégie de résilience = Roulette russe
Une seule panne majeure = Des millions de pertes potentielles
La résilience est votre assurance-vie digitale
Si vous déployez des services critiques en production, assurez-vous d'avoir mis en place une architecture résiliente, des systèmes de monitoring robustes, et des plans de continuité régulièrement testés. C'est la seule façon de protéger votre entreprise contre les pannes inévitables de l'infrastructure cloud moderne.
Prêt à renforcer la résilience de votre infrastructure ? Contactez BOVO Digital pour un audit de votre architecture cloud et la mise en place de stratégies de mitigation adaptées à vos besoins.
Étiquettes
FAQ
Qu'est-ce qu'un point de défaillance unique (SPOF) et comment l'identifier dans son infrastructure ?
Un SPOF (Single Point of Failure) est un composant dont la défaillance entraîne l'arrêt complet du système. Pour l'identifier : cartographiez tous les services tiers dont vous dépendez (CDN, DNS, API de paiement), identifiez ceux sans redondance, puis évaluez l'impact d'une panne de chacun. Cloudflare gérant 20 % des sites mondiaux représentait un SPOF massif pour l'écosystème Internet entier lors de cet incident.
Comment mettre en place un failover multi-CDN automatique pour son site web ?
Un failover multi-CDN s'implémente en trois étapes : réduisez le TTL DNS de votre domaine à 60 secondes pour permettre des bascules rapides, configurez un CDN secondaire (AWS CloudFront ou Fastly) avec le même contenu, puis mettez en place un health check actif toutes les 30 secondes qui bascule automatiquement vers le CDN secondaire si le primaire répond avec des erreurs 5xx pendant plus de 2 minutes consécutives.
Quelle est la différence entre RTO et RPO dans un plan de continuité d'activité ?
Le RTO (Recovery Time Objective) est la durée maximale d'interruption acceptable — combien de temps votre application peut rester hors ligne sans impact critique. Le RPO (Recovery Point Objective) désigne la quantité maximale de données perdables, exprimée en durée. Un e-commerce critique visera un RTO de 5 minutes et un RPO quasi-nul, tandis qu'un blog interne pourra accepter un RTO de 4 heures et un RPO de 24 heures.
Quels outils utiliser pour surveiller la résilience de son infrastructure cloud en 2026 ?
Pour un monitoring complet de résilience : Uptime Robot ou Better Uptime pour les checks de disponibilité externes (gratuit jusqu'à 50 moniteurs), Prometheus + Grafana pour les métriques internes, PagerDuty ou OpsGenie pour l'alerting avec escalade, et StatusPage.io pour communiquer l'état de votre service à vos utilisateurs. Datadog et New Relic intègrent en 2026 la détection d'anomalies par IA pour anticiper les pannes avant qu'elles ne se produisent.
Comment pratiquer le chaos engineering sans risquer une panne en production ?
Commencez par un environnement de staging identique à la production. Définissez une hypothèse de résilience précise (ex : "si le CDN primaire tombe, le failover se déclenche en moins de 30 secondes"). Utilisez Chaos Monkey, Gremlin ou LitmusChaos pour injecter des pannes contrôlées. Ne testez en production qu'après avoir validé vos mécanismes en staging, et toujours avec un mécanisme d'arrêt d'urgence (kill switch) activable en un clic.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
Vicentia Bonou
Développeuse Full Stack & Spécialiste Web/Mobile. Engagée à transformer vos idées en applications intuitives et sites web sur mesure.


