
Unsloth Studio et GLM-5.2 : comment lancer l'IA locale la plus puissante en 2026
Unsloth Studio ouvre une interface web pour l'IA locale. GLM-5.2 (744B params, 1M de contexte) tourne en GGUF dynamique dès 223 Go de RAM. Installation, quants, modes Thinking et intégration n8n expliqués.

Unsloth Studio et GLM-5.2 : comment lancer l'IA locale la plus puissante en 2026
L'IA locale ne se limite plus aux modèles 7B sur un laptop. En juin 2026, Unsloth Studio permet d'exécuter GLM-5.2 — 744 milliards de paramètres — depuis votre propre machine.
Unsloth Studio change la donne pour l'IA locale. Jusqu'ici, faire tourner un LLM frontier en local demandait de jongler entre Ollama, llama.cpp, Hugging Face et des fichiers de configuration obscurs. Unsloth condense tout dans une interface web open source : recherche de modèles, téléchargement de quants GGUF, inférence optimisée, tool calling et exécution de code — sur Mac, Windows et Linux.
En parallèle, GLM-5.2 de Z.ai vient d'arriver avec des GGUF dynamiques Unsloth dès le jour J : 744B paramètres, 40B actifs (architecture MoE), 1 million de tokens de contexte. Selon la documentation Unsloth, il rivalise sur plusieurs benchmarks publiés avec Claude 4.8 Opus, GPT-5.5 et Gemini 3.1 Pro — à vérifier sur votre cas d'usage, car les benchmarks éditeurs restent orientés tâches standardisées.
Ce tutoriel vous guide de bout en bout : comprendre Unsloth Studio, dimensionner votre hardware, installer, lancer GLM-5.2, configurer les modes Thinking, optimiser le contexte long, et préparer le pont vers n8n pour vos agents en production.
Unsloth Studio : l'interface web qui simplifie l'IA locale
Unsloth est connu depuis 2024 pour accélérer le fine-tuning (jusqu'à 2× plus rapide, 70 % de VRAM en moins selon leur documentation). En 2026, Unsloth Studio ajoute une couche consommation : une UI web pour l'inférence locale, pas seulement l'entraînement.
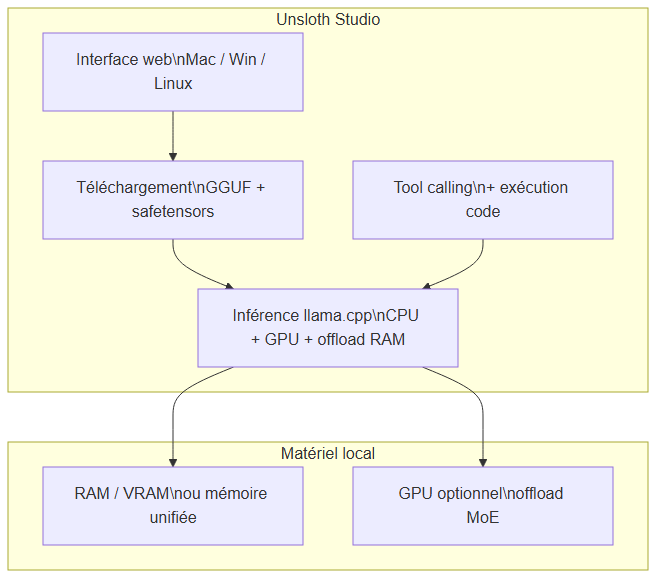 Unsloth Studio : interface web, téléchargement GGUF, inférence llama.cpp avec offload RAM/GPU et tool calling intégré
Unsloth Studio : interface web, téléchargement GGUF, inférence llama.cpp avec offload RAM/GPU et tool calling intégré
Ce que Studio apporte concrètement (selon la doc Unsloth, juin 2026) :
- Recherche, téléchargement et exécution de modèles GGUF et safetensors
- Tool calling auto-réparant + recherche web intégrée
- Exécution de code Python et Bash dans l'interface
- Réglage automatique des paramètres d'inférence (température, top-p…)
- Inférence rapide CPU + GPU via llama.cpp
- Détection multi-GPU et offload automatique vers la RAM
- Option
--secure: tunnel HTTPS gratuit via Cloudflare
 De l'accélération fine-tuning (2024) à Unsloth Studio et GLM-5.2 day-zero (2026)
De l'accélération fine-tuning (2024) à Unsloth Studio et GLM-5.2 day-zero (2026)
Pour les équipes qui veulent rester sur des modèles plus légers (Gemma 4, Llama), notre tutoriel Gemma 4 + Ollama + n8n reste le point d'entrée le plus accessible. GLM-5.2 vise un autre segment : workstations et serveurs haut de gamme avec 256 Go+ de mémoire.
GLM-5.2 : ce qu'il faut savoir avant d'installer
GLM-5.2 est le modèle open source de Z.ai, optimisé pour le code long horizon, le raisonnement et les tâches agentiques. Unsloth publie des Dynamic GGUFs : certaines couches restent en haute précision, d'autres sont compressées agressivement — d'où le compromis taille/qualité.
Prérequis matériels (documentation Unsloth)
La mémoire totale requise dépend de la quantification. Unsloth publie ce tableau (RAM + VRAM, ou mémoire unifiée) :
| Quant | Mémoire totale requise |
|---|---|
| 1-bit (dynamic) | ~223 Go |
| 2-bit (dynamic) | ~245 Go |
| 3-bit | ~290–360 Go |
| 4-bit | ~372–475 Go |
| 5-bit | ~570 Go |
| 8-bit | ~810 Go |
Le quant UD-IQ2_M (2-bit dynamique) occupe ~239 Go sur disque et est présenté comme le meilleur compromis accessibilité/précision. Il tient sur un Mac 256 Go en mémoire unifiée, ou sur 1× GPU 24 Go + 256 Go RAM avec offload MoE.
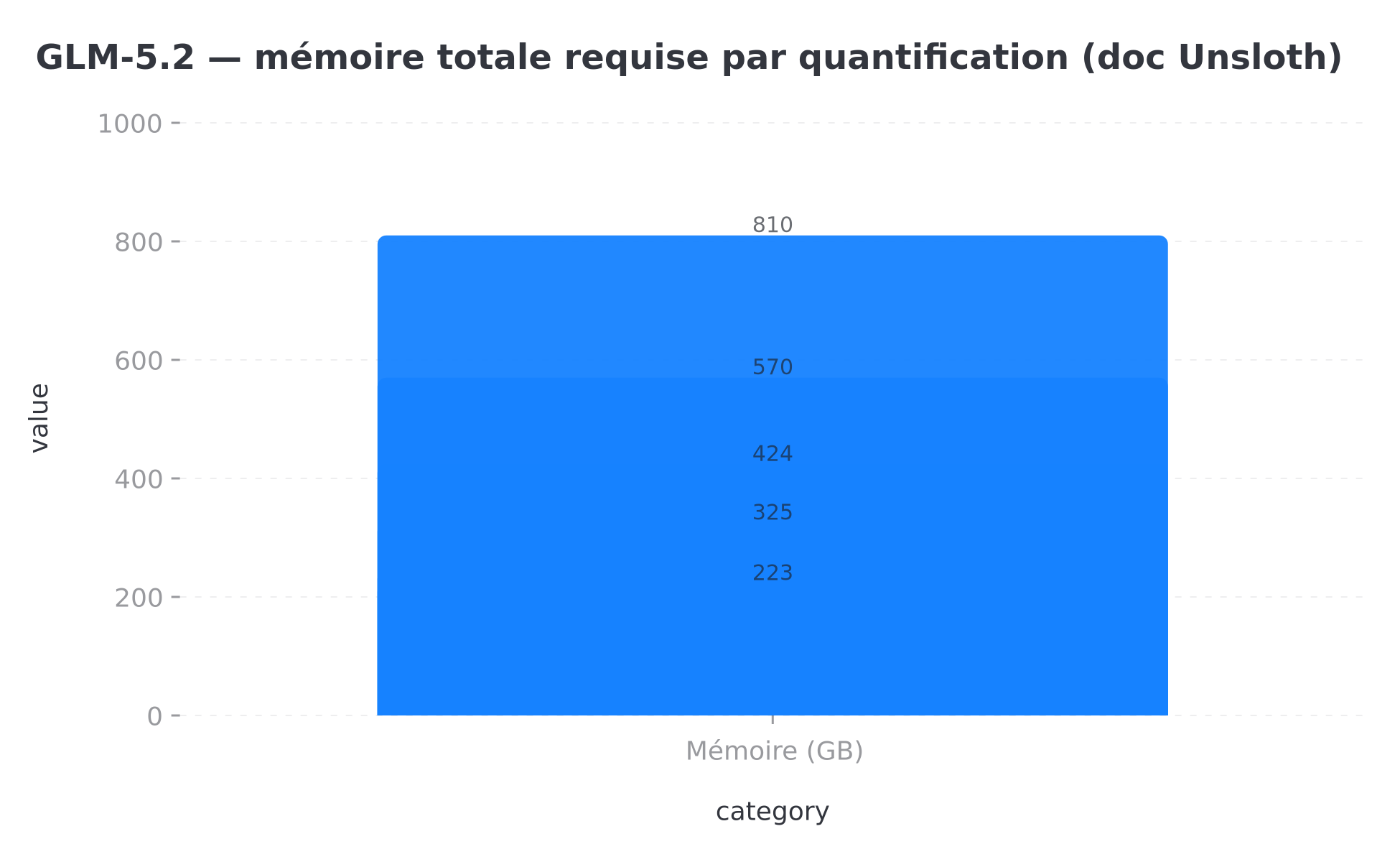 Mémoire totale (RAM+VRAM) selon la quantification GLM-5.2 — données Unsloth, juin 2026
Mémoire totale (RAM+VRAM) selon la quantification GLM-5.2 — données Unsloth, juin 2026
Règle pratique : prévoyez une marge confortable au-dessus de la taille du fichier quant. Un disque plein ou une RAM saturée provoque des swaps qui tuent la latence.
Quants dynamiques : que vaut le 1-bit en vrai ?
Unsloth mesure la qualité via la divergence KL (KLD) entre le modèle quantifié et la référence BF16. Résultats publiés :
- Dynamic 1-bit : ~76,2 % top-1 accuracy, 86 % plus petit
- Dynamic 2-bit : ~82 % top-1 accuracy, 84 % plus petit
- Dynamic 4-bit / 5-bit : quasi lossless selon Unsloth
Le piège classique : croire que « 76 % » signifie 24 % de réponses fausses. Unsloth insiste : ce chiffre reflète la distribution de tokens (mots de liaison, formulations), pas la justesse factuelle. « La capitale de la France est Paris » reste Paris — c'est « Je vais » vs « Voici » qui varie. Pour des tâches très hors distribution, le 4-bit dynamique est plus sûr.
Installation d'Unsloth Studio
 Pipeline : installation, lancement Studio, téléchargement GLM-5.2 et inférence locale
Pipeline : installation, lancement Studio, téléchargement GLM-5.2 et inférence locale
Étape 1 — Installer Unsloth
macOS, Linux, WSL :
curl -fsSL https://unsloth.ai/install.sh | sh
Windows PowerShell :
irm https://unsloth.ai/install.ps1 | iex
Étape 2 — Lancer Studio
unsloth studio -H 0.0.0.0 -p 8888
Ouvrez http://127.0.0.1:8888 dans votre navigateur.
Pour un accès HTTPS sécurisé (notamment en réseau d'équipe), Unsloth propose un tunnel Cloudflare intégré :
unsloth studio --secure
Étape 3 — Premier lancement
Au premier démarrage, Studio vous demande de créer un mot de passe. C'est important : vous exposez un serveur d'inférence sur votre machine — ne le laissez pas ouvert sans authentification sur un réseau partagé.
Étape 4 — Télécharger GLM-5.2
- Allez dans l'onglet Studio Chat
- Recherchez GLM-5.2 dans la barre de recherche
- Sélectionnez votre quant (recommandé : UD-IQ2_M si vous avez ~256 Go de mémoire)
- Lancez le téléchargement — vérifiez l'espace disque avant (plusieurs centaines de Go)
Studio détecte automatiquement les configurations multi-GPU et gère l'offload RAM.
Paramètres d'inférence et modes Thinking
GLM-5.2 propose trois modes de raisonnement :
- Sans thinking — réponses directes, plus rapides
- High Thinking — raisonnement modéré
- Max Thinking — pour les tâches complexes (code, planification, agents)
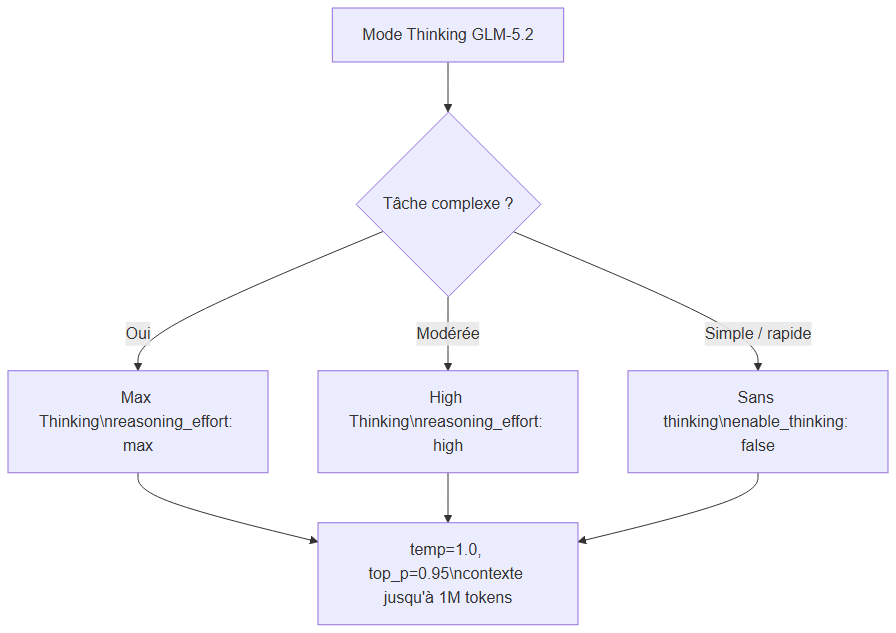 Choisir Max, High ou désactiver le thinking selon la complexité de la tâche
Choisir Max, High ou désactiver le thinking selon la complexité de la tâche
Réglages recommandés (doc Unsloth)
| Paramètre | Tâches générales | SWE-Bench Pro |
|---|---|---|
temperature | 1.0 | 1.0 |
top_p | 0.95 | 1.0 |
| Contexte max | 1 048 576 tokens | idem |
Dans Unsloth Studio, ces paramètres sont pré-configurés automatiquement. Vous pouvez les ajuster manuellement, ainsi que le chat template et la longueur de contexte.
Désactiver ou ajuster le thinking (llama.cpp)
GLM-5.2 raisonne par défaut. Pour le désactiver en ligne de commande :
--chat-template-kwargs '{"enable_thinking":false}'
Sous PowerShell :
--chat-template-kwargs "{\"enable_thinking\":false}"
Pour l'effort de raisonnement :
--chat-template-kwargs '{"reasoning_effort":"max"}'
--chat-template-kwargs '{"reasoning_effort":"high"}'
Llama.cpp supporte aussi --reasoning on / --reasoning off selon les versions récentes.
Alternative CLI : lancer GLM-5.2 avec llama.cpp
Si vous préférez la ligne de commande à l'interface Studio, Unsloth fournit les GGUF sur Hugging Face (unsloth/GLM-5.2-GGUF).
Téléchargement manuel (plus rapide que le pull intégré) :
pip install huggingface_hub
hf download unsloth/GLM-5.2-GGUF \
--local-dir unsloth/GLM-5.2-GGUF \
--include "*UD-IQ2_M*"
Inférence conversationnelle :
./llama.cpp/llama-cli \
--model unsloth/GLM-5.2-GGUF/UD-IQ2_M/GLM-5.2-UD-IQ2_M-00001-of-00006.gguf \
--temp 1.0 \
--top-p 0.95 \
--min-p 0.01
Unsloth montre en démo la génération d'un jeu Flappy Bird fonctionnel avec audio — même en quant 1-bit. Impressionnant pour la démo ; en production métier, restez sur le 2-bit ou 4-bit pour plus de marge.
Contexte long : quantifier le KV cache
Pour exploiter la fenêtre 1M tokens sans saturer la RAM, llama.cpp permet de quantifier le KV cache :
./llama.cpp/llama-cli \
--model unsloth/GLM-5.2-GGUF/UD-IQ2_M/GLM-5.2-UD-IQ2_M-00001-of-00006.gguf \
--temp 1.0 --top-p 0.95 --min-p 0.01 \
--cache-type-k q4_1 \
--cache-type-v q4_1
Avec q4_1 (~5 bits/poids), Unsloth estime un gain de contexte d'environ 3,2× par rapport au f16 par défaut. Un modèle limité à 10K tokens pourrait théoriquement monter vers ~32K — les gains réels dépendent de votre hardware.
Benchmarks : lire les chiffres avec discernement
Unsloth publie un tableau comparatif GLM-5.2 vs Claude 4.8 Opus, GPT-5.5, Gemini 3.1 Pro. Quelques repères (source : documentation Unsloth, juin 2026) :
| Benchmark | GLM-5.2 | Claude 4.8 Opus | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 62,1 | 69,2 | 58,6 |
| Terminal Bench 2.1 | 81,0 | 85,0 | 84,0 |
| AIME 2026 | 99,2 | 95,7 | 98,3 |
| MCP-Atlas | 76,8 | 77,8 | 75,3 |
Lecture honnête : GLM-5.2 est compétitif, parfois devant GPT-5.5 sur le code agentique, parfois derrière Claude sur SWE-bench Pro. Ces scores ne remplacent pas un test sur vos propres données. Pour une vue d'ensemble du paysage modèles ouvert/fermé, voir DeepSeek V4 vs GPT-5.5.
Brancher GLM-5.2 local à vos workflows n8n
Unsloth Studio et llama.cpp ne remplacent pas un orchestrateur. Pour des agents en production, la stack gagnante reste :
- GLM-5.2 local (Unsloth Studio ou
llama-server) pour le raisonnement souverain - n8n pour les triggers, retries, intégrations CRM/email et supervision
- MCP pour exposer vos outils métier de façon standardisée
L'approche est identique à Ollama + n8n, avec une contrainte matérielle bien plus lourde. Exposez llama-server en API compatible OpenAI, puis pointez le nœud AI Agent de n8n vers http://localhost:8080/v1 (port à adapter).
Ressources complémentaires :
Limites et cas où rester sur le cloud
GLM-5.2 local n'est pas pour tout le monde :
- Coût hardware : une machine 256 Go+ coûte plusieurs milliers d'euros
- Électricité et bruit : inférence 24/7 sur un gros MoE consomme
- Mise à jour : vous gérez vous-même les nouvelles versions de modèles
- Latence premier token : même optimisé, un 744B MoE reste lent vs une API cloud
Restez sur le cloud (Claude, GPT, Gemini) si vous avez des pics de charge imprévisibles, une équipe sans ops, ou des besoins < 70B paramètres. Passez au local si la souveraineté des données, le coût à volume constant ou l'absence de dépendance fournisseur sont critiques — thèmes que nous développons dans l'article sur la résilience fournisseur IA.
Conclusion
Unsloth Studio démocratise l'accès à l'IA locale avancée : plus besoin d'être expert llama.cpp pour lancer un frontier model. GLM-5.2 pousse le plafond open source vers des capacités code et agentiques qui rivalisent avec les APIs premium — à condition d'avoir le hardware adéquat et de comprendre les compromis des quants dynamiques.
Checklist rapide :
- Vérifiez votre mémoire totale (cible : 256 Go+ pour UD-IQ2_M)
- Installez Unsloth (
curlouirmselon l'OS) - Lancez
unsloth studio -p 8888(ou--secureen réseau) - Téléchargez GLM-5.2 UD-IQ2_M depuis l'onglet Chat
- Choisissez le mode Thinking selon la tâche
- Branchez n8n + MCP pour industrialiser
BOVO Digital accompagne les entreprises sur le dimensionnement hardware, le déploiement Unsloth/Ollama, la connexion n8n et la mise en production d'agents locaux sécurisés. Contactez-nous pour un audit de faisabilité IA locale.
Étiquettes
FAQ
Qu'est-ce qu'Unsloth Studio ?
Unsloth Studio est une interface web open source pour l'IA locale, développée par Unsloth. Elle permet de rechercher, télécharger et exécuter des modèles GGUF et safetensors, avec inférence via llama.cpp, tool calling, exécution de code Python/Bash et réglage automatique des paramètres d'inférence. Elle fonctionne sur macOS, Windows et Linux.
Quel matériel faut-il pour faire tourner GLM-5.2 en local ?
Selon la documentation Unsloth (juin 2026), la quantification 1-bit requiert environ 223 Go de mémoire totale (RAM + VRAM ou mémoire unifiée), la 2-bit environ 245 Go, et la 8-bit environ 810 Go. Le quant UD-IQ2_M (2-bit dynamique, ~239 Go sur disque) est conçu pour tenir sur un Mac 256 Go de mémoire unifiée ou sur 1 GPU 24 Go + 256 Go de RAM avec offload MoE.
Que signifie « 76 % de précision top-1 » pour un quant 1-bit ?
Unsloth précise que ce chiffre ne signifie pas que le modèle produit 24 % de réponses incorrectes ou du charabia. Il mesure la divergence de distribution de tokens par rapport au modèle BF16 de référence sur un échantillon — les mots-clés factuels restent souvent identiques, c'est la variabilité sur les mots de liaison qui change. Pour des tâches hors distribution extrêmes, Unsloth recommande plutôt le dynamic 4-bit.
Comment désactiver le mode Thinking de GLM-5.2 ?
GLM-5.2 raisonne par défaut. Dans llama.cpp, passez --chat-template-kwargs '{"enable_thinking":false}'. Sous PowerShell Windows, échappez les guillemets : --chat-template-kwargs "{\"enable_thinking\":false}". Dans Unsloth Studio, le basculement se fait depuis l'interface.
Peut-on brancher GLM-5.2 local à n8n ?
Oui, via le serveur d'inférence llama.cpp (llama-server) exposé en API compatible OpenAI, ou en pointant n8n vers l'endpoint local d'Unsloth Studio si vous l'exposez sur le réseau. L'approche est similaire à Ollama + n8n décrite dans notre tutoriel Gemma 4, avec des prérequis matériels bien plus élevés.
BOVO Digital peut-il déployer une stack IA locale en entreprise ?
Oui. Nous dimensionnons le hardware, installons Unsloth Studio ou Ollama, connectons les modèles à n8n pour vos workflows agents, et mettons en place monitoring, sauvegardes et accès sécurisé (HTTPS, tunnel, authentification).
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.

Singbo Davy AGONMA
Développeur Fullstack & Expert IA. Spécialiste automatisation n8n, développement Laravel/Flutter et intégration d'agents IA. Master CS — IFRI.


