
Gemma 4 Apache 2.0, OpenClaw Payant, Claude Opus 4.6 : La Semaine qui Rebalance l'IA
En une semaine : Google ouvre tout avec Gemma 4 (Apache 2.0), Anthropic ferme les robinets sur l'usage agressif d'agents avec OpenClaw, et Claude Opus 4.6 passe à 1M de tokens. Trois signaux qui révèlent l'économie réelle de l'IA en 2026.

Mis à jour le

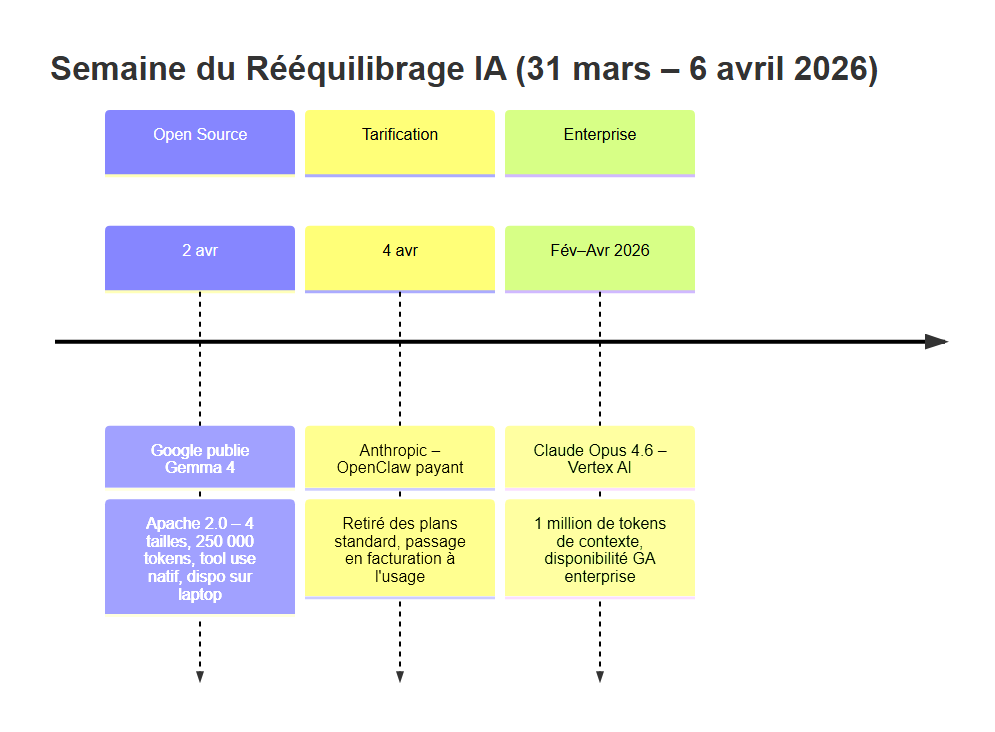
La semaine du 31 mars au 6 avril 2026, racontée comme elle s'est passée
Mercredi 2 avril, 14h GMT. Google publie Gemma 4 sur Hugging Face. Licence Apache 2.0. Quatre tailles. Tool use natif. 250 000 tokens de contexte. Disponible immédiatement pour téléchargement sur n'importe quel ordinateur portable.
Vendredi 4 avril, 18h GMT. Anthropic envoie un email à ses abonnés Claude Code : OpenClaw — l'outil d'exécution de code agressif intégré à Claude Code — est retiré des plans d'abonnement standard. Il passe en facturation à l'usage (pay-as-you-go), avec un tarif qui fait mal aux builders qui en abusaient.
Dans ce contexte : Claude Opus 4.6, disponible sur Google Vertex AI depuis février 2026 avec 1 million de tokens de contexte, change silencieusement la manière dont les équipes enterprise construisent leurs pipelines d'analyse.
Trois mouvements en apparence contradictoires. En réalité, ils racontent la même histoire : l'IA entre dans une phase de maturité économique où les règles du jeu se stabilisent, et où les choix techniques d'aujourd'hui déterminent les marges de demain.
 Semaine du rééquilibrage IA : Gemma 4 Apache 2.0 (2 avr.), OpenClaw payant Anthropic (4 avr.), Claude Opus 4.6 1M tokens
Semaine du rééquilibrage IA : Gemma 4 Apache 2.0 (2 avr.), OpenClaw payant Anthropic (4 avr.), Claude Opus 4.6 1M tokens
Acte 1 : Gemma 4 et la stratégie open source de Google
Pour comprendre Gemma 4, il faut comprendre pourquoi Google donne quelque chose d'aussi précieux gratuitement.
Google n'est pas une ONG. Gemma 4 Apache 2.0 est une décision stratégique calculée.
Le calcul de Google : Si les développeurs du monde entier construisent leurs agents, leurs apps, leurs workflows sur un modèle Google, ils ont besoin d'infrastructure pour les faire tourner à l'échelle. Infrastructure cloud = Google Cloud. Chaque workflow Gemma 4 qui passe en production sur GCP est une victoire pour Google, même si le modèle lui-même est gratuit.
C'est exactement la stratégie d'Android : donner l'OS gratuitement pour dominer l'écosystème mobile.
Ce que ça change pour vous :
- Gemma 4 2B tourne sur un Raspberry Pi. Ce n'est pas un détail — c'est une déclaration d'intention sur l'edge computing.
- 400 millions de téléchargements cumulés pour la famille Gemma depuis 2024. L'adoption est réelle et massive.
- La licence Apache 2.0 permet l'utilisation commerciale sans restriction. Vous pouvez construire un produit et le vendre sans royalties.
Nous avons publié un tutoriel complet pour faire tourner Gemma 4 avec Ollama et n8n — si vous voulez commencer aujourd'hui.
Gemma 4 en profondeur : les quatre tailles et leurs cas d'usage réels
La sortie de Gemma 4 ne se résume pas à "un nouveau modèle gratuit". Ce qui change fondamentalement avec cette génération, c'est l'existence de quatre tailles cohérentes qui couvrent le spectre complet des déploiements, du dispositif embarqué à la production cloud.
La version 2B est conçue pour l'edge et les appareils contraints. Elle tourne sur un Raspberry Pi 4, un smartphone Android haut de gamme, ou dans un worker Cloudflare. Sa fenêtre de contexte de 250 000 tokens reste très capable pour des tâches de classification, résumé court, ou extraction d'entités. L'inférence coûte quasi rien : quelques centimes d'électricité par heure. Pour des automatisations légères en local, c'est un changement de paradigme complet.
La version 9B est le point d'équilibre que nous recommandons d'emblée pour la majorité des cas d'usage professionnels. Elle nécessite 16 Go de VRAM pour une inférence fluide (une RTX 3080 Ti suffit), produit des résultats comparables à GPT-3.5 Turbo sur la plupart des benchmarks de tâches pratiques, et supporte le tool use natif. C'est la taille qui rend le self-hosting économiquement rationnel pour une équipe tech de 2-10 développeurs.
La version 27B pousse les performances vers le territoire de GPT-4o Mini sur les tâches complexes. Elle nécessite deux GPU (ou un seul A100 en cloud) pour tourner confortablement. À ce niveau, vous entrez dans le territoire des analyses multi-étapes, de la génération de code non trivial, et du raisonnement sur des problèmes structurés. Le coût d'infrastructure reste inférieur aux API cloud équivalentes à partir de quelques millions de tokens par mois.
La version 76B — la plus grande — rivalise avec les modèles propriétaires haut de gamme sur les benchmarks de raisonnement avancé. Elle nécessite un cluster GPU dédié pour l'inférence et n'est pas destinée au self-hosting individuel. Son intérêt réside surtout dans le fine-tuning : des organisations avec des données propriétaires abondantes peuvent créer des versions spécialisées sur leur domaine métier.
Le tool use natif : l'élément différenciant
Ce qui rend Gemma 4 vraiment remarquable pour les builders d'agents, c'est l'intégration native du tool use dès la version 2B. Dans les générations précédentes, le tool use était réservé aux modèles premium ou nécessitait des prompts d'ingénierie complexes. Avec Gemma 4, vous pouvez construire des agents qui appellent des APIs, exécutent des recherches web, ou interagissent avec des bases de données — et ce, depuis un modèle qui tourne en local sans frais d'API.
Pour les workflows n8n et Make que nous construisons chez BOVO Digital, d'après notre lecture du marché, cela représente un basculement : pour les automatisations de données non sensibles, Gemma 4 9B peut remplacer GPT-4o Mini avec un coût opérationnel proche de zéro une fois l'infrastructure en place.
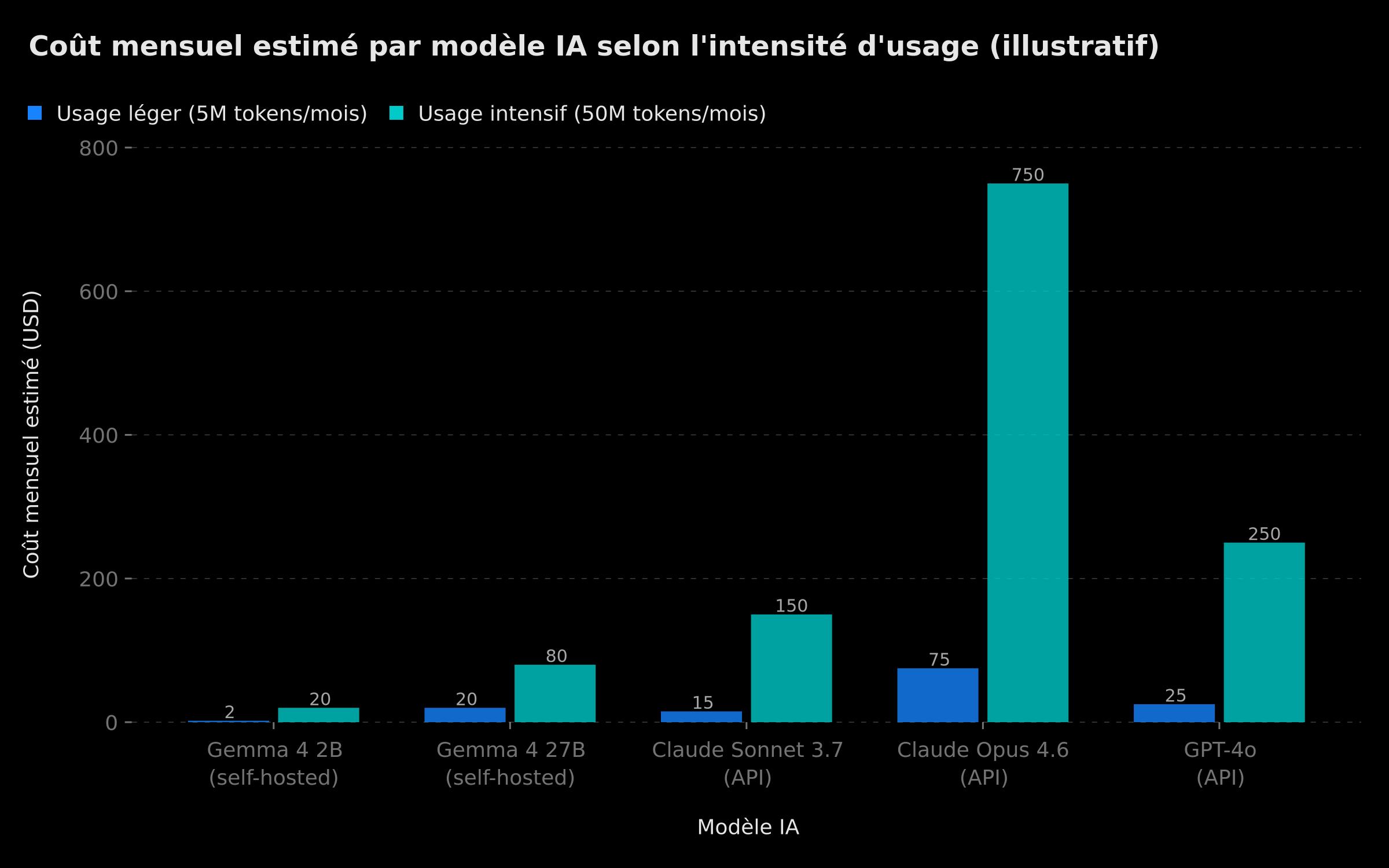 Coût mensuel estimatif (USD) : Gemma 4 self-hosted vs Claude Sonnet, Opus 4.6, GPT-4o en API — usage léger vs intensif (données illustratives)
Coût mensuel estimatif (USD) : Gemma 4 self-hosted vs Claude Sonnet, Opus 4.6, GPT-4o en API — usage léger vs intensif (données illustratives)
Ce graphique illustratif met en évidence la rupture économique : à usage intensif (50M tokens/mois), la différence entre Gemma 4 auto-hébergé et Claude Opus 4.6 en API peut atteindre un facteur 9 à 37. Le seuil de rentabilité du self-hosting se situe généralement autour de 20-30M tokens mensuels, selon les coûts d'infrastructure locaux.
Acte 2 : Anthropic serre les boulons — et c'est logique
La décision d'Anthropic sur OpenClaw a surpris beaucoup de gens dans la communauté. À tort.
Rappelez-vous que Claude Code a leaké 512 000 lignes de code en mars 2026. Dans ce leak, des chercheurs ont découvert qu'Anthropic avait déjà identifié des patterns d'usage "insoutenables" de certains outils d'agents. OpenClaw en faisait partie.
Le problème d'OpenClaw :
OpenClaw permettait à Claude Code d'exécuter des boucles d'agents complexes — des dizaines voire des centaines d'appels LLM par session, avec exécution de code, recherche web, et modification de fichiers en parallèle. Pour un utilisateur humain, c'est puissant. Pour un pipeline automatisé qui tourne 24h/24, c'est une consommation d'inférence que les $20/mois d'abonnement ne couvrent pas.
Anthropic a fait le choix économiquement rationnel : les usages scalables paient à l'usage, les usages ponctuels restent en forfait.
Ce que ça révèle sur l'économie de l'inférence IA :
L'inférence LLM coûte cher à grande échelle. OpenAI, Anthropic, Google — tous ces acteurs subventionnent leurs prix actuels avec leurs levées de fonds. À mesure que les pipelines d'agents automatisés se multiplient, cette subvention devient insoutenable.
La décision d'Anthropic sur OpenClaw est la première d'une série qui viendra dans les prochains mois. Les tarifs d'abonnement fixes pour des usages agressifs d'agents sont une anomalie temporaire.
Lisez notre analyse sur les fonctionnalités cachées d'Anthropic révélées par le leak pour le contexte complet.
Décrypter l'économie de l'inférence en 2026
Pour bien comprendre pourquoi la décision Anthropic sur OpenClaw était inévitable, il faut regarder les chiffres de l'inférence LLM avec honnêteté.
Un token coûte entre 0,1 et 15 microdollars selon le modèle et le provider, en 2026. Claude Opus 4.6 est positionné dans la tranche haute. Une session OpenClaw agressive — avec 200 appels LLM par session, contexts longs, et exécution de code — peut facilement consommer l'équivalent de $5 à $20 de puissance de calcul. Multiplié par 100 utilisateurs actifs avec des pipelines automatisés, c'est $500 à $2000 par jour en coûts d'inférence bruts — non couverts par un abonnement à $20/mois.
Pourquoi les providers ont subventionné jusqu'ici
Les levées de fonds massives d'OpenAI ($40 milliards en 2025-2026), d'Anthropic (plusieurs milliards en séries successives), et les investissements de Google dans Gemini ont permis une chose : subsidier le coût réel de l'inférence pour acquérir des utilisateurs. C'est la même logique qu'Uber offrant des courses à perte pour dominer le marché du taxi.
Cette phase touche à sa fin. Non pas parce que les providers sont à court d'argent, mais parce que les entreprises clientes — pas les particuliers — représentent désormais l'essentiel du chiffre d'affaires. Et les entreprises ont des pipelines qui tournent 24h/24. La subvention devient structurellement impossible à maintenir.
Ce que vous devez anticiper
D'après notre lecture du marché, trois évolutions sont probables dans les 12 prochains mois : premièrement, d'autres providers vont suivre Anthropic et créer des "tiers agents" distincts des forfaits classiques ; deuxièmement, les prix à l'usage (tokens input/output) vont se stabiliser voire baisser grâce aux gains d'efficacité matérielle, mais les fonctionnalités d'agents (tool use, computer use, long context) resteront premium ; troisièmement, le self-hosting avec des modèles open-source comme Gemma 4 va devenir le choix par défaut des équipes soucieuses de leurs marges.
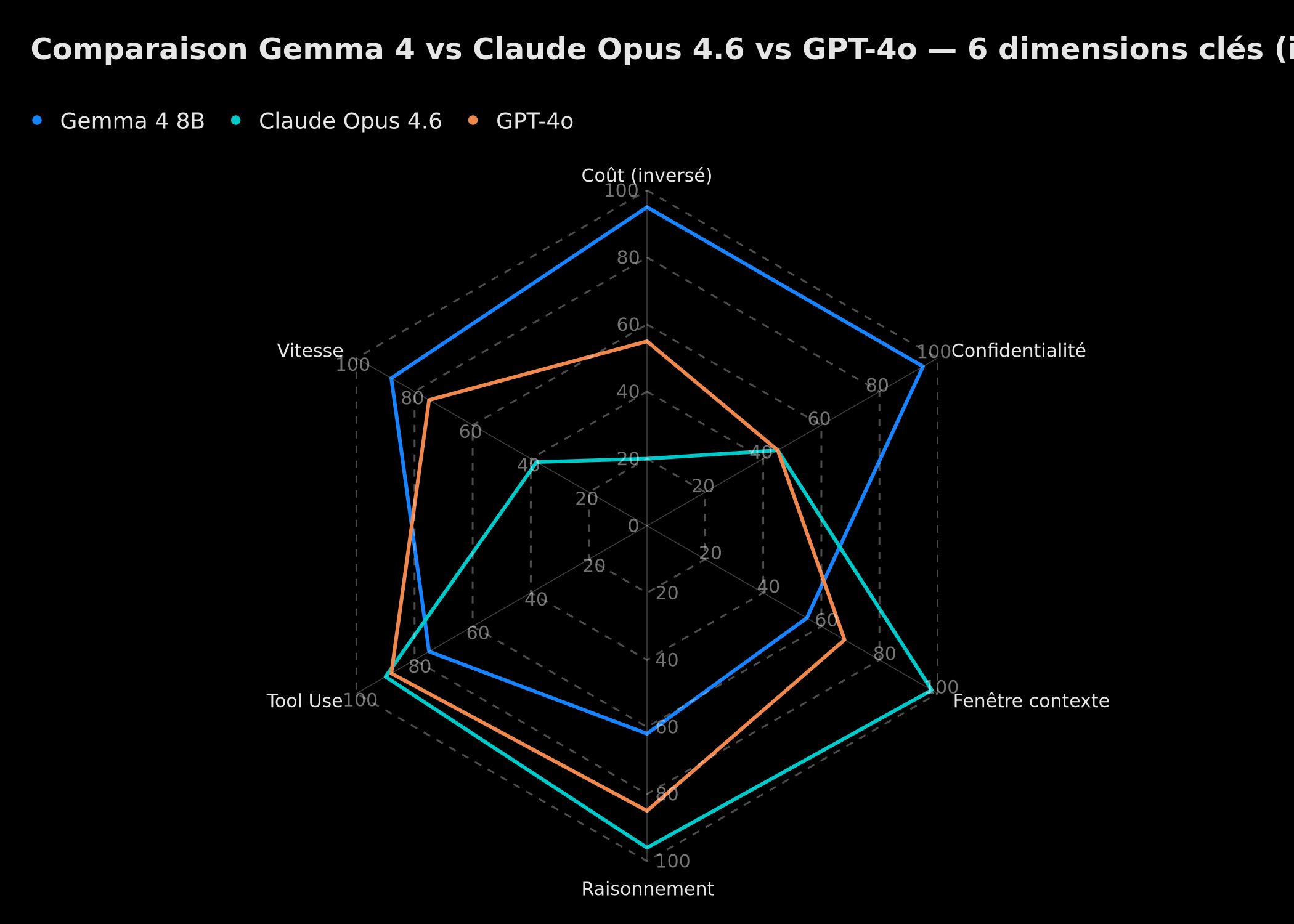 Radar comparatif illustratif : coût inversé, confidentialité, fenêtre contexte, raisonnement, tool use, vitesse — Gemma 4 8B vs Claude Opus 4.6 vs GPT-4o
Radar comparatif illustratif : coût inversé, confidentialité, fenêtre contexte, raisonnement, tool use, vitesse — Gemma 4 8B vs Claude Opus 4.6 vs GPT-4o
Ce radar illustre le positionnement de chaque modèle selon six axes. Aucun modèle ne domine sur tous les fronts : Gemma 4 excelle sur le coût et la confidentialité, Claude Opus 4.6 sur le contexte et le raisonnement, GPT-4o offre l'équilibre le plus homogène. C'est cette réalité qui rend une architecture multi-modèles non seulement souhaitable, mais nécessaire.
Acte 3 : Claude Opus 4.6 et l'ère du contexte long
Dans ce brouhaha, une information est passée presque inaperçue : Claude Opus 4.6 est disponible sur Google Vertex AI avec 1 million de tokens de contexte.
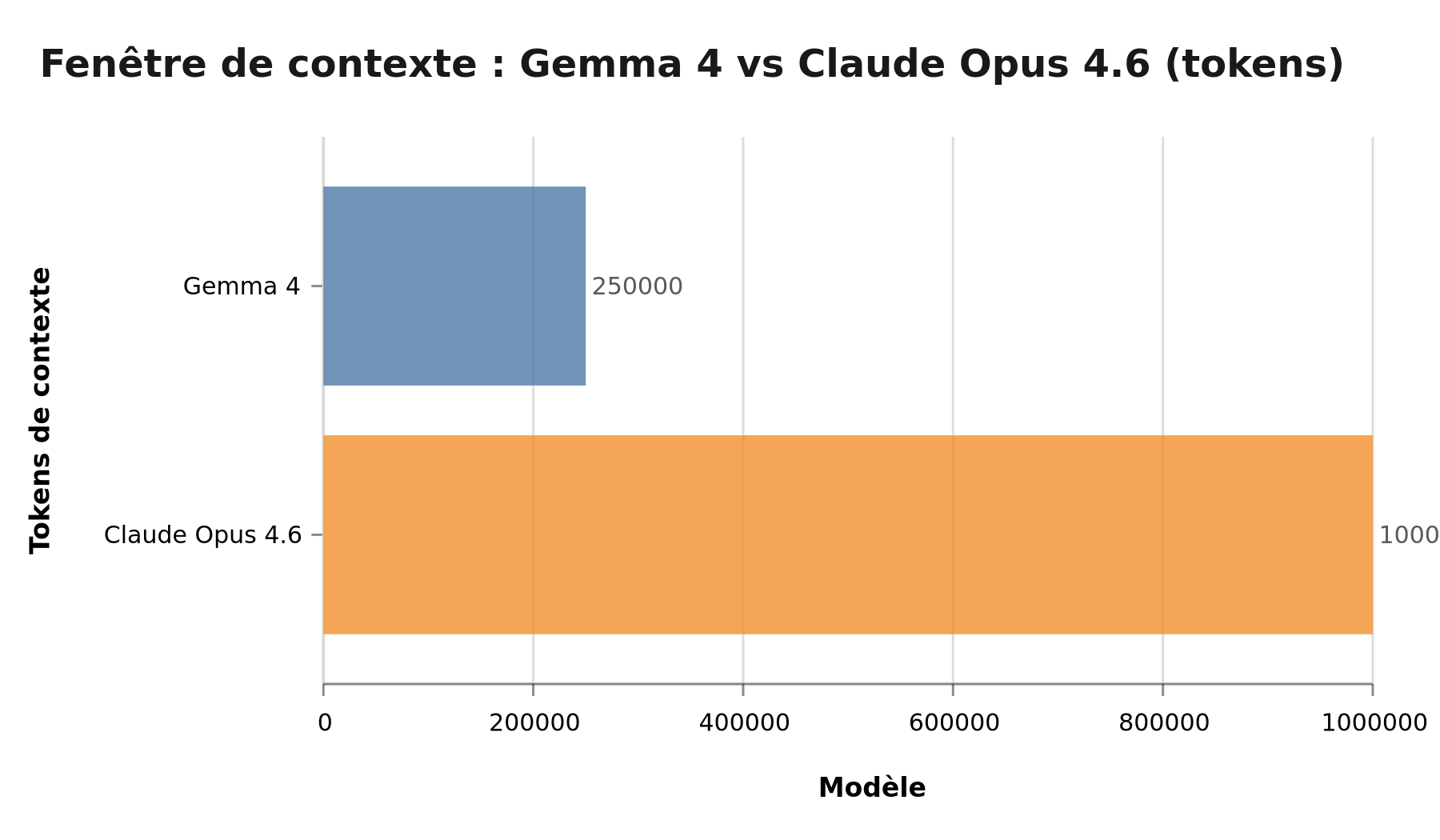 Fenêtre de contexte disponible : Gemma 4 = 250 000 tokens, Claude Opus 4.6 = 1 000 000 tokens (4× plus)
Fenêtre de contexte disponible : Gemma 4 = 250 000 tokens, Claude Opus 4.6 = 1 000 000 tokens (4× plus)
Pour donner une référence : 1 million de tokens, c'est environ 750 000 mots. C'est la totalité d'un codebase moyen. C'est 500 pages de documentation produit. C'est 3 ans d'emails d'un commercial.
Ce que ça rend possible :
- Audit de codebase complet en une requête : Envoyer l'intégralité d'un projet et demander "où sont les failles de sécurité ?" sans RAG, sans découpage
- Analyse de données contractuelles : Ingérer des centaines de contrats et extraire des patterns en une seule passe
- Mémoire conversationnelle longue durée : Conserver le contexte de mois d'interactions sans architecture de mémoire externe
Notre récapitulatif tech de février 2026 avait déjà couvert l'annonce initiale — Opus 4.6 disponible sur Vertex AI marque le passage en disponibilité générale enterprise.
Contexte long : révolution pour qui ?
Avant d'intégrer Claude Opus 4.6 dans tous vos pipelines, il faut avoir une vision honnête de ce que le contexte long résout — et de ce qu'il ne résout pas.
Quand 1M tokens change réellement la donne
Le contexte long excelle dans les scénarios où la cohérence globale sur l'ensemble du corpus est critique. Un audit de sécurité complet d'un codebase de 100 000 lignes, par exemple : une architecture RAG découpera le code en chunks et manquera les vulnérabilités qui s'étendent sur plusieurs fichiers distants. Claude Opus 4.6 avec 1M tokens voit tout simultanément et peut raisonner sur les interactions entre composants distants.
De même, pour la diligence contractuelle dans un contexte M&A ou juridique — analyser des centaines de contrats pour identifier des clauses contradictoires ou des risques cachés — le contexte long permet une analyse comparative en une seule inférence, là où RAG nécessite plusieurs passes avec risque de perdre des connexions sémantiques subtiles.
Quand RAG reste supérieur
Le contexte long n'est pas la solution universelle que certains enthousiasmes présentent. Pour les bases de connaissances évolutives (documentation produit mise à jour en continu), RAG reste structurellement supérieur : vous pouvez mettre à jour un vecteur isolé sans re-injecter l'intégralité du corpus. Pour les volumes dépassant 1M tokens — un datacenter de support client avec 5 ans de tickets, par exemple — RAG est incontournable.
Il y a aussi la question du coût. Une inférence à 1M tokens input chez Claude Opus 4.6 coûte significativement plus qu'une inférence RAG classique de quelques milliers de tokens. Pour des requêtes fréquentes sur un corpus stable, RAG garde une avance économique considérable.
La disponibilité via Vertex AI : ce que ça implique
Le fait que Claude Opus 4.6 soit disponible via Google Vertex AI — et non uniquement via l'API Anthropic directe — n'est pas anodin. Vertex AI intègre les contrôles de gouvernance, les SLA enterprise, et les outils d'observabilité que les grandes organisations exigent. C'est un signal fort d'Anthropic : Claude Opus n'est plus positionné comme un outil pour developers, mais comme une infrastructure enterprise. Le pricing suit logiquement.
Qui gagne et qui perd dans ce rebalancement ?
D'après notre lecture du marché, le rebalancement d'avril 2026 crée des gagnants et des perdants clairement identifiables. Comprendre dans quelle catégorie vous tombez est la première étape pour ajuster votre stratégie.
Les grands gagnants
Les freelances et indie hackers sortent grands gagnants de cette semaine. Gemma 4 Apache 2.0 leur donne accès à un modèle commercial-grade sans aucun coût récurrent. Un freelance qui automatise des tâches de classification ou de résumé pour ses clients peut désormais offrir des solutions locales, confidentielles, et sans frais d'API — une proposition de valeur inédite jusqu'ici.
Les développeurs open-source et les équipes académiques bénéficient d'une licence Apache 2.0 sans ambiguïté. Contrairement aux licences "community" de Meta (Llama) ou aux licences personnalisées de Mistral AI, Apache 2.0 est universellement reconnue, permet la redistribution commerciale, et ne contient pas de clauses de révocation unilatérale.
Les entreprises avec des obligations de confidentialité fortes — santé, finance, secteur public — voient dans Gemma 4 une opportunité de déploiement on-premise qu'aucune API cloud ne peut offrir. Données qui ne quittent jamais l'infrastructure interne, coût prévisible, pas de dépendance à un provider externe.
Les moins bien lotis
Les builders qui ont construit des pipelines automatisés sur Claude Code avec un usage intensif d'OpenClaw vont ressentir un choc tarifaire. Ce n'est pas une punition d'Anthropic — c'est simplement la fin d'une subvention. Ceux qui ont des pipelines qui génèrent de la valeur réelle s'adapteront ; ceux dont les workflows n'étaient pas économiquement viables au prix réel de l'inférence vont devoir revoir leur architecture.
Les utilisateurs de LLM comme commodité — ceux qui pensaient que les prix actuels des API allaient rester stables indéfiniment — vont devoir intégrer que l'économie de l'IA en 2026 ressemble de plus en plus à l'économie cloud en 2012 : spécialisation des tiers, prix différenciés par usage, et avantage aux équipes qui ont une stratégie de costs optimisation.
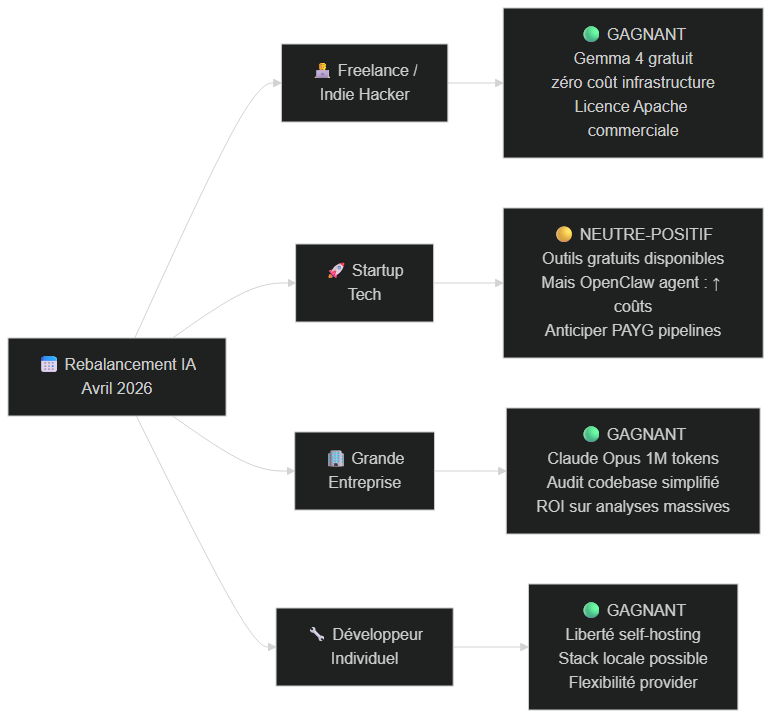 Qui gagne, qui perd dans le rebalancement IA d'avril 2026 : freelances et devs individuels gagnants avec Gemma 4, enterprise avec Claude Opus 1M tokens, startups en position neutre-positive
Qui gagne, qui perd dans le rebalancement IA d'avril 2026 : freelances et devs individuels gagnants avec Gemma 4, enterprise avec Claude Opus 1M tokens, startups en position neutre-positive
Que signifie le rééquilibrage IA d'avril 2026 pour les builders ?
Ces trois événements dessinent la carte du territoire pour les prochains 18 mois :
1. Les LLM locaux vont cannibaliser les API pour les cas d'usage standard. Gemma 4 Apache 2.0 qui tourne sur laptop est suffisant pour 80% des automatisations courantes. Les providers cloud vont devoir se différencier sur les 20% restants. Si vous vous intéressez à la tension plus large entre modèles ouverts et fermés, notre analyse de la guerre IA ouverte vs fermée avec DeepSeek V4 et GPT-5.5 donne un éclairage complémentaire indispensable.
2. La facturation à l'usage va remplacer les forfaits pour les usages agents. Ce qui s'est passé avec OpenClaw va se reproduire. Si vous construisez des pipelines qui tournent 24h/24, anticipez que les "prix abonnement" que vous payez aujourd'hui vont évoluer.
3. Le contexte long change l'architecture des pipelines IA. Avec 1M tokens, certaines architectures RAG complexes deviennent superflues. Mais les coûts d'inférence sur ces volumes restent élevés — il faut arbitrer. Pour comprendre les protocoles qui standardisent la communication agent-outil, lisez notre article sur MCP et Agent2Agent.
La stratégie en 5 étapes pour traverser le rebalancement
Face à ces changements, une réaction émotionnelle — "abandonnons tout et passons à Gemma 4" ou "restons sur Claude Opus, peu importe le prix" — est le pire chemin. La réponse rationnelle est une architecture réfléchie. Voici les cinq étapes que nous recommandons à partir de notre expérience opérationnelle.
Étape 1 : Auditer votre dépendance provider actuelle
La première question à poser est simple : si votre provider LLM principal augmente ses prix de 50% demain, combien de temps faut-il pour migrer ? Si la réponse dépasse deux semaines, votre architecture est trop couplée. Listez tous les endroits dans votre code où un nom de modèle ou une URL d'API est hardcodé. C'est votre surface de risque.
Étape 2 : Implémenter une couche d'abstraction LLM
LiteLLM est aujourd'hui la solution la plus mature pour l'abstraction provider. Elle expose une interface compatible OpenAI pour plus de 100 providers — Anthropic, Google, Mistral, Ollama — ce qui signifie que votre code n'a qu'une seule interface à connaître. Un changement de provider devient une modification d'une variable d'environnement plutôt qu'un refactor complet.
Étape 3 : Développer une stratégie locale avec Gemma 4
Pour chaque use case de votre stack, posez la question : est-ce que ce flux doit absolument passer par un provider cloud ? La classification de documents entrants, la génération de résumés internes, l'extraction d'entités sur des données RH — tout cela peut tourner en local avec Gemma 4 9B. Réservez les API cloud pour les tâches qui nécessitent vraiment le niveau de raisonnement supérieur de Claude Opus ou GPT-4o. Notre article sur le coût réel d'un chatbot IA en 2026 quantifie précisément ces économies.
Étape 4 : Mettre en place des tests de régression sur vos prompts
Un des risques sous-estimés d'une migration de modèle est la régression silencieuse : le comportement change subtilement, les résultats se dégradent légèrement, mais personne ne s'en aperçoit immédiatement. Un suite de tests automatiques sur vos prompts critiques — comparant les outputs attendus aux outputs réels — est non négociable pour une architecture robuste.
Étape 5 : Monitorer les coûts d'inférence par use case
Sans métriques granulaires, vous naviguez à vue. Chaque appel LLM dans votre stack doit être instrumenté avec le provider, le modèle, les tokens consommés, et le coût associé. Cela vous permet d'identifier les use cases qui consomment disproportionnément et de prendre des décisions basées sur des données plutôt que des intuitions.
Pour les équipes qui cherchent à éviter les erreurs d'IA en production — pas seulement les coûts, mais aussi la fiabilité des réponses — notre guide sur l'évitement des hallucinations IA en entreprise complète cette stratégie stack.
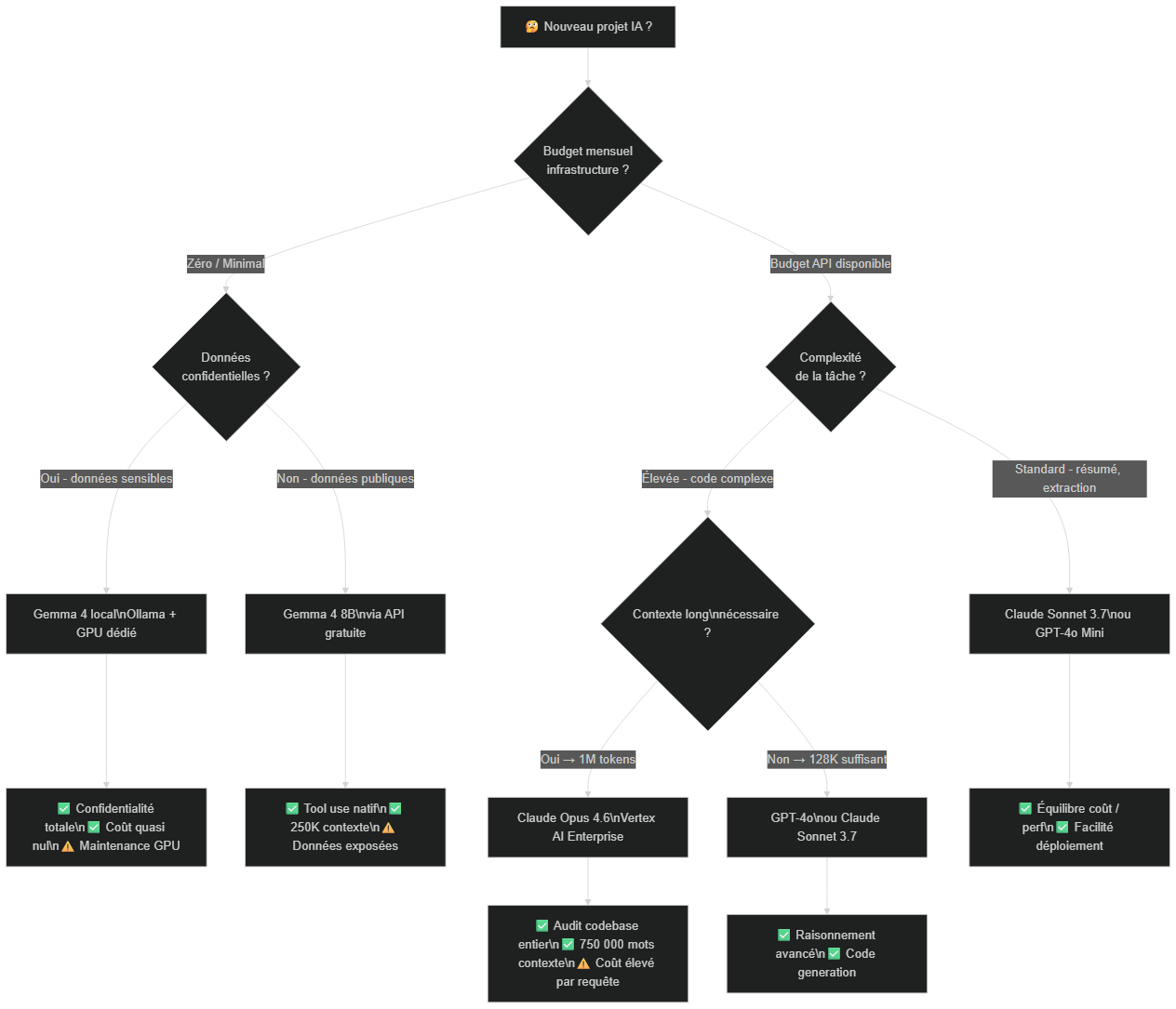 Flowchart de décision : Gemma 4 local (données sensibles, budget zéro), Claude Opus 4.6 (contexte long enterprise), Claude Sonnet / GPT-4o (usage standard), GPT-4o / Sonnet (raisonnement sans contexte long)
Flowchart de décision : Gemma 4 local (données sensibles, budget zéro), Claude Opus 4.6 (contexte long enterprise), Claude Sonnet / GPT-4o (usage standard), GPT-4o / Sonnet (raisonnement sans contexte long)
La leçon pour votre stack IA :
Les builders qui résistent aux changements tarifaires sont ceux qui ont une architecture flexible — capable de switcher de modèle (OpenAI → Anthropic → Gemma local) sans tout reconstruire. Une abstraction de provider, des prompts paramétrables, des tests de régression automatiques.
C'est exactement ce qu'on conçoit chez BOVO Digital quand nous livrons des agents en production : une architecture qui ne dépend pas d'un seul provider, et qui peut arbitrer dynamiquement entre local et cloud selon la nature de chaque requête.
Votre stack IA actuelle est-elle résistante aux changements de tarifs et de providers ?
Découvrez nos services d'automatisation et d'intégration d'agents IA — ou explorez le profil de William Aklamavo pour comprendre les architectures que nous livrons.
Étiquettes
FAQ
Pourquoi Google lance-t-il Gemma 4 gratuitement en Apache 2.0 ?
C'est une stratégie similaire à Android : donner le modèle gratuitement pour pousser les développeurs à adopter l'écosystème Google, notamment Google Cloud pour l'inférence à grande échelle. Chaque builder qui fait tourner Gemma 4 en production a besoin d'infrastructure — Google Cloud est la cible naturelle.
Qu'est-ce qu'OpenClaw et pourquoi Anthropic l'a-t-il retiré des plans standard ?
OpenClaw est un outil d'exécution de code agressif dans Claude Code, permettant des boucles d'agents complexes avec des centaines d'appels LLM par session. Anthropic l'a retiré des abonnements standard car l'usage automatisé intensif n'est pas rentable à $20/mois. Il passe en facturation à l'usage.
Qu'est-ce que le contexte de 1 million de tokens de Claude Opus 4.6 change concrètement ?
Il permet d'ingérer l'intégralité d'un codebase, 500 pages de documentation, ou 3 ans d'emails dans une seule requête. Pour certains cas d'usage d'audit ou d'analyse, cela remplace des architectures RAG complexes. Le coût d'inférence reste élevé sur ces volumes — il faut arbitrer selon l'usage.
Comment construire une stack IA résistante aux changements de pricing des providers ?
En abstrayant le provider LLM de votre logique applicative. Concrètement : utiliser une couche d'abstraction (LiteLLM, LangChain), ne pas hardcoder les noms de modèles, maintenir des tests de régression sur vos prompts clés, et avoir une stratégie locale (Ollama) pour les cas d'usage qui peuvent tourner en local.
Gemma 4 va-t-il remplacer OpenAI pour les automatisations n8n ?
Pour 80% des cas d'usage courants (classification, résumé, extraction d'informations, tool use simple), Gemma 4 8B est une alternative viable et gratuite. Pour les tâches de raisonnement complexe, de génération de code avancé, ou de cohérence sur de très longs contextes, GPT-4o et Claude Sonnet restent supérieurs.
Peut-on héberger Gemma 4 27B sans GPU dédié en production ?
Techniquement possible via quantification 4-bit sur CPU, mais les performances sont limitées (latence élevée, débit faible). Pour une production viable, il faut au minimum une carte GPU avec 16 Go de VRAM (RTX 3090, RTX 4080) ou une instance cloud GPU (A10G, L4). La version 9B reste le meilleur équilibre pour un auto-hébergement sans GPU haut de gamme.
Quels outils permettent de basculer facilement entre providers LLM sans tout reconstruire ?
LiteLLM est la solution la plus mature : elle propose une interface unifiée compatible OpenAI pour plus de 100 providers. LangChain et LlamaIndex offrent des abstractions plus haut niveau. Pour les workflows n8n, le nœud "AI Model" générique permet de changer de provider sans modifier la logique du workflow. L'essentiel est de ne jamais hardcoder un nom de modèle dans votre code applicatif.
Quand est-il préférable d'utiliser le contexte long de Claude Opus 4.6 plutôt qu'une architecture RAG ?
Le contexte long est préférable quand la cohérence globale sur l'ensemble du corpus compte (audit complet, analyse comparative multi-documents, synthèse contractuelle). RAG reste supérieur pour les bases de connaissances évolutives, les volumes dépassant 1M tokens, et les cas où le coût d'inférence est un facteur critique. En pratique, les deux approches sont complémentaires plutôt que concurrentes.
Prêt à l'implémenter ?
Réservez un appel stratégique gratuit de 30 min avec nos experts
Nous analyserons votre situation et proposerons un plan d'action concret.
William Aklamavo
Expert en développement web et automatisation, passionné par l'innovation technologique et l'entrepreneuriat digital.


