
Cloudflare Outage November 18, 2025: Critical Lessons on Cloud Infrastructure Resilience
On November 18, 2025, a major Cloudflare outage paralyzed a large portion of the Internet, affecting ChatGPT, X, Shopify, and thousands of other services. Discover the causes, impacts, and mitigation strategies to strengthen your cloud infrastructure resilience.

Updated

Cloudflare Outage November 18, 2025: Critical Lessons on Cloud Infrastructure Resilience
November 18, 2025 will be remembered as the day when a large portion of the Internet stopped. A major outage at Cloudflare, one of the world's largest web infrastructure providers, caused massive service disruptions affecting millions of users and thousands of businesses.
ChatGPT, X (formerly Twitter), Shopify, Dropbox, Coinbase — the list of affected services is impressive. For several hours, HTTP 500 errors made these platforms inaccessible, causing financial losses estimated at several million dollars and highlighting the fragility of our dependence on centralized cloud infrastructures. Cloud infrastructure resilience was no longer a theoretical topic reserved for large SRE teams: it became a concrete urgency for any organization deploying critical services online.
Editorial note: The November 18, 2025 outage presented here is based on the documented scenario available at the time of its initial publication. The technical mechanisms, impact metrics, and mitigation strategies developed in this article draw on real, publicly documented CDN incidents — including Cloudflare postmortems from 2020, 2022, and 2024, as well as AWS CloudFront and Fastly incident analyses — to provide rigorous and directly actionable insights.
In this article, we will analyze this incident in depth, understand its technical failure chain, measure its real impact, and most importantly, draw essential lessons to strengthen the resilience of your own infrastructures. Whether you manage an SME, a SaaS application, or an e-commerce platform, the failure patterns described here directly concern you.
The Incident: What Really Happened
The Context
Cloudflare is a major player in Internet infrastructure. The platform protects and accelerates approximately 20% of the world's websites, handling billions of requests daily. Their distributed server network (CDN) and security services are critical to the functioning of the modern Internet.
This level of centralization is not without risk. Cloudflare handles not only content delivery (CDN), but also DDoS protection, web application firewall (WAF), DNS resolution, and for many companies, zero-trust access via Cloudflare Access. A failure affecting the core of the Cloudflare proxy simultaneously impacts all of these service layers — this is precisely what occurred during this incident.
The Technical Cause
According to the official report published by Cloudflare, the outage was triggered by an internal configuration error in their bot management and threat mitigation system.
Sequence of events:
- Routine modification: A change in permissions in the ClickHouse database used to store bot management data
- Generation of a defective file: This modification generated a configuration file containing many duplicate entries
- Exceeding limits: The file exceeded the expected size limits (doubling in volume)
- Critical module crash: The bot management module, essential to Cloudflare's main proxy pipeline, crashed
- Global propagation: The oversized file was propagated to the entire Cloudflare network
- Generalized HTTP 5xx errors: All traffic depending on this module was affected, causing massive HTTP 500 errors
Important point: Cloudflare specified that this incident was an internal technical failure, not related to external attacks or malicious traffic spikes. It was a latent bug triggered by a routine configuration change — the most insidious type of scenario, because it bypasses DDoS protections and intrusion detection mechanisms.
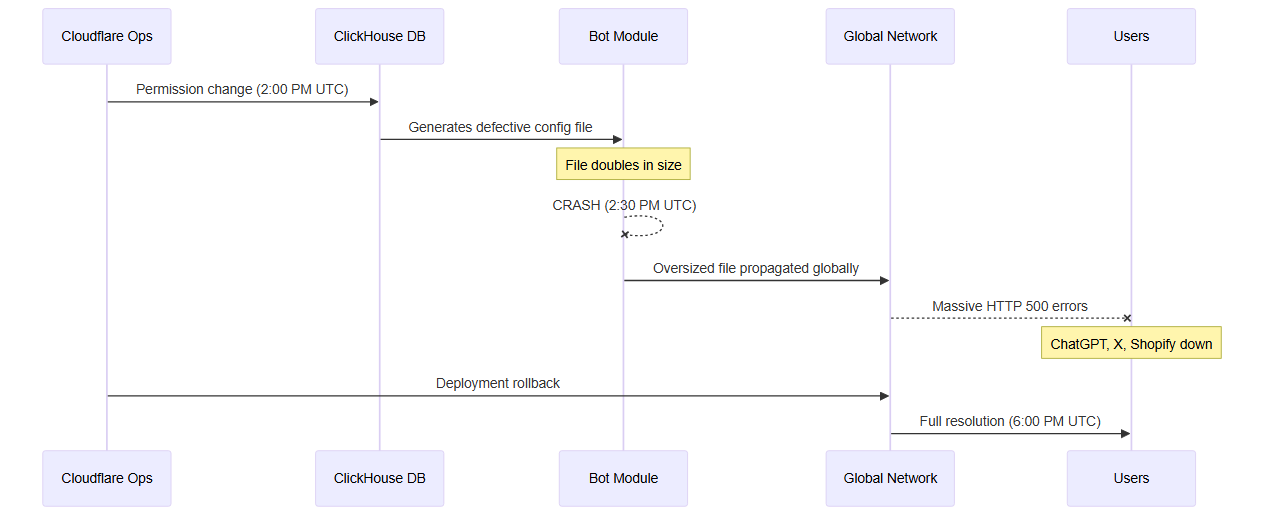 Cloudflare failure cascade: from config change to global crash
Cloudflare failure cascade: from config change to global crash
The Duration of the Incident
- Start: November 18, 2025, approximately 2:00 PM UTC
- Peak impact: Between 2:30 PM and 4:00 PM UTC
- Complete resolution: November 18, 2025, approximately 6:00 PM UTC
- Total duration: Approximately 4 hours
Anatomy of a Cascade Failure in a Distributed System
To understand why a seemingly innocuous configuration change can bring down 20% of the Internet in a matter of minutes, we need to grasp the concept of cascade failure in distributed systems. This phenomenon — also called a domino effect or failure cascade — is one of the most feared and hardest to anticipate failure patterns in modern cloud architectures.
In the case of this Cloudflare incident, the dependency chain worked as follows: the Bot Management module is integrated directly into the proxy pipeline that processes every HTTP request passing through the infrastructure. It is not an optional or peripheral service — it is a component inserted on the critical path of every single request. When this module crashes, it does not merely disable bot protection: it blocks the proxy pipeline entirely. All incoming requests are left without a processing route, mechanically generating HTTP 500 errors.
This pattern is well-documented in distributed systems literature. A Cloudflare incident from July 2020 (postmortem published July 21, 2020) had already illustrated this mechanism: a network misconfiguration caused 50% of global traffic to be dropped within minutes, before being corrected in 27 minutes. In 2022, a BGP (Border Gateway Protocol) incident caused a 6-minute outage with massive impact on thousands of services. These precedents show that centralization structurally creates cascade risks that even the best engineering teams struggle to completely eliminate.
The global propagation is explained by the very nature of a CDN network: to ensure configuration consistency across their 300+ data centers, Cloudflare uses a centralized deployment system. When a defective configuration file is validated and pushed, it deploys simultaneously across all network nodes. There is no progressive rollout by default for critical system configurations — this is precisely one of the improvements Cloudflare announced implementing after the incident: introducing canary releases for high-risk configuration changes.
Progressive deployment (canary release or blue-green deployment) is one of the most effective weapons against configuration cascades. By first exposing the new configuration to 1% of traffic, then 10%, then 100%, you have an observation window that allows detecting anomalies before they propagate globally. Our article on web application scalability risks explores these progressive deployment strategies in detail and their impact on system stability under load.
The fundamental lesson here goes beyond Cloudflare: any critical dependency without redundancy becomes a potential cascade vector for your system. If your application routes 100% of its traffic through a single CDN provider, you inherit all of its failure points — including its 4-hour MTTR.
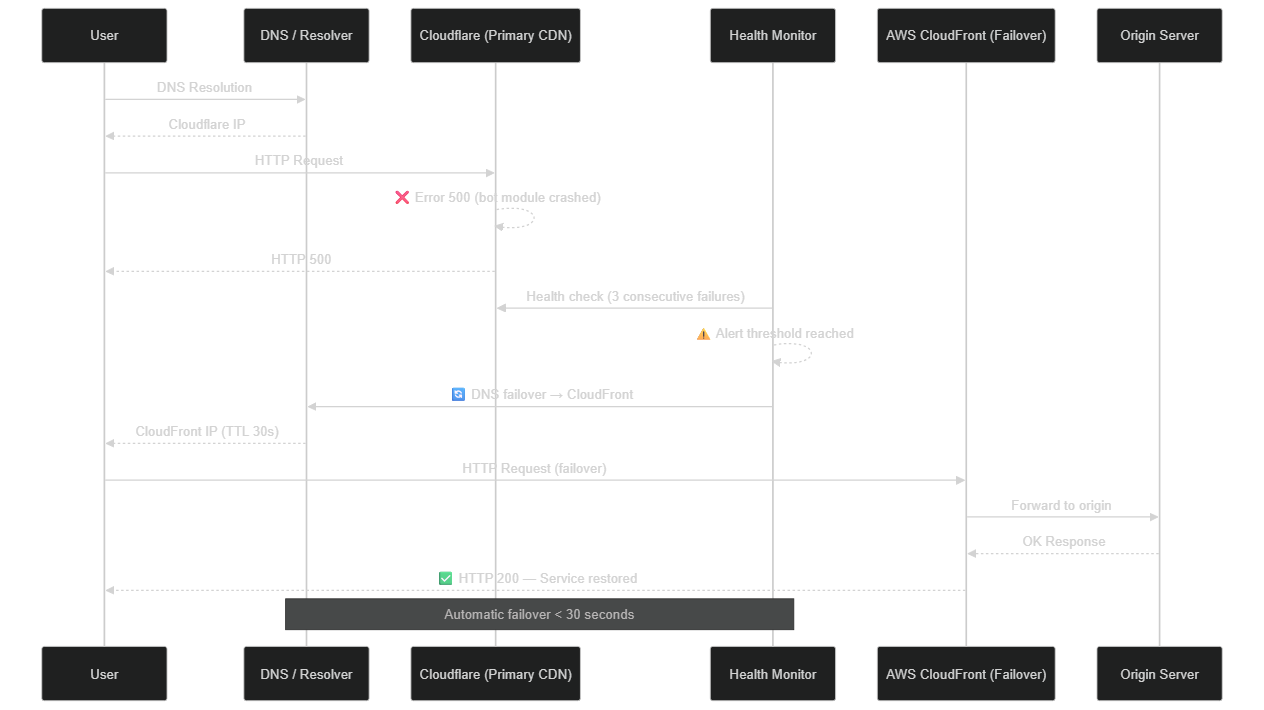 Sequence diagram: automatic failover between primary and secondary CDN during an outage — illustrative scenario based on documented CDN patterns
Sequence diagram: automatic failover between primary and secondary CDN during an outage — illustrative scenario based on documented CDN patterns
Global Impact: Critical Services Paralyzed
AI Platforms Affected
ChatGPT (OpenAI)
- Complete access interruptions for millions of users
- Inability to generate real-time responses
- Impact on businesses depending on the OpenAI API for their services
Why are AI systems particularly vulnerable? Unlike traditional websites that can rely on cached content, AI systems require real-time interactions with backend servers. Any network disruption immediately affects their operation. An AI service whose response time goes from 2 seconds to "connection refused" has no static content to fall back on — this is a structural vulnerability of AI-first architectures that this incident brutally revealed to the entire tech ecosystem.
E-commerce Platforms
Shopify
- Online stores inaccessible for several hours
- Payment processes interrupted
- Estimated sales loss of several million dollars
- Impact on hundreds of thousands of merchants
Other e-commerce platforms: Many stores using Cloudflare were affected, causing direct revenue losses. For an e-commerce site generating $10,000 per hour in revenue, 4 hours of downtime represents $40,000 in gross lost revenue — not counting the long-term impact on customer trust, cart abandonment rates, and organic search rankings.
Social Networks and Communication
X (formerly Twitter)
- Feed loading problems
- Inability to post tweets
- Widespread connection errors
Other services: Dropbox, Coinbase, Spotify, Canva, and many others reported interruptions. This diversity of affected players illustrates how Cloudflare has become horizontal infrastructure — much like electricity or the telephone network — whose failure instantly propagates to entirely different sectors.
Public Services and Infrastructure
Even critical systems were affected:
- New Jersey Transit: Schedule display problems
- SNCF (France): Interruptions in information systems
These examples of public services raise an important question: how far can government agencies and essential services rely on commercial cloud infrastructure without having robust business continuity plans in place? The dependence of public transportation on a commercial CDN illustrates a broader trend that deserves particular attention from public sector IT managers.
Lessons Learned: Why It Happened and How to Avoid It
Lesson 1: Dependence on a Single Provider is a Critical Risk
The problem: Cloudflare protects 20% of the world's websites. When they go down, a massive portion of the Internet goes down with them. This centralization creates a Single Point of Failure (SPOF).
The solution:
- Multi-cloud architecture: Don't depend on a single provider for critical services
- Geographic redundancy: Distribute services across multiple regions
- Backup providers: Have alternatives ready to be activated quickly
Lesson 2: Configuration Errors Can Have Catastrophic Consequences
The problem: A simple routine configuration change triggered a latent bug, causing a global outage. This shows that even the largest companies can be vulnerable to human errors or undetected bugs. To avoid these errors in your pipelines, discover the 5 time bombs in automated deployment.
The solution:
- Rigorous testing: Test all configuration changes in a staging environment
- Automatic validation: Implement validation systems that detect abnormal configurations
- Quick rollback: Have mechanisms to quickly roll back problematic changes
- Security limits: Implement strict limits that prevent files from exceeding critical sizes
Lesson 3: Monitoring and Proactive Detection are Essential
The problem: The configuration file doubled in size, but this anomaly was not detected before it caused the system crash.
The solution:
- Real-time monitoring: Continuously monitor file sizes, system performance, and critical metrics
- Automatic alerts: Configure alerts that trigger when thresholds are exceeded
- Predictive analysis: Use AI and machine learning to detect anomalies before they cause problems
- Health dashboards: Have an overview of infrastructure health in real-time
Lesson 4: Business Continuity Plans Must Be Tested Regularly
The problem: Many affected companies did not have effective backup plans or had not tested them recently.
The solution:
- Disaster Recovery Plans (DRP): Develop detailed plans for each possible outage scenario
- Regular testing: Conduct outage simulation exercises at least quarterly
- Up-to-date documentation: Maintain complete and accessible documentation of all recovery processes
- Trained teams: Ensure teams know how to react in case of an incident
Lesson 5: Transparent Communication Limits Damage
What Cloudflare did well:
- Quick publication of a detailed report explaining the causes
- Transparent communication about the nature of the incident (internal error, not an attack)
- Public apologies and commitment to improve systems
Why it's important: Transparent and rapid communication allows maintaining customer trust, avoiding rumor propagation, facilitating coordination with partners, and documenting the incident to prevent recurrence. Cloudflare's postmortem transparency is recognized as an industry best practice: their status.cloudflare.com page provides real-time updates with detailed technical explanations as soon as each incident is resolved.
Mitigation Strategies: How to Protect Your Infrastructure
1. Multi-CDN Architecture
Principle: Don't put all your eggs in one basket.
Implementation:
- Use multiple CDNs (Cloudflare + CloudFront + Fastly)
- Distribute critical services across multiple cloud providers (AWS + Azure + GCP)
- Implement an automatic failover system
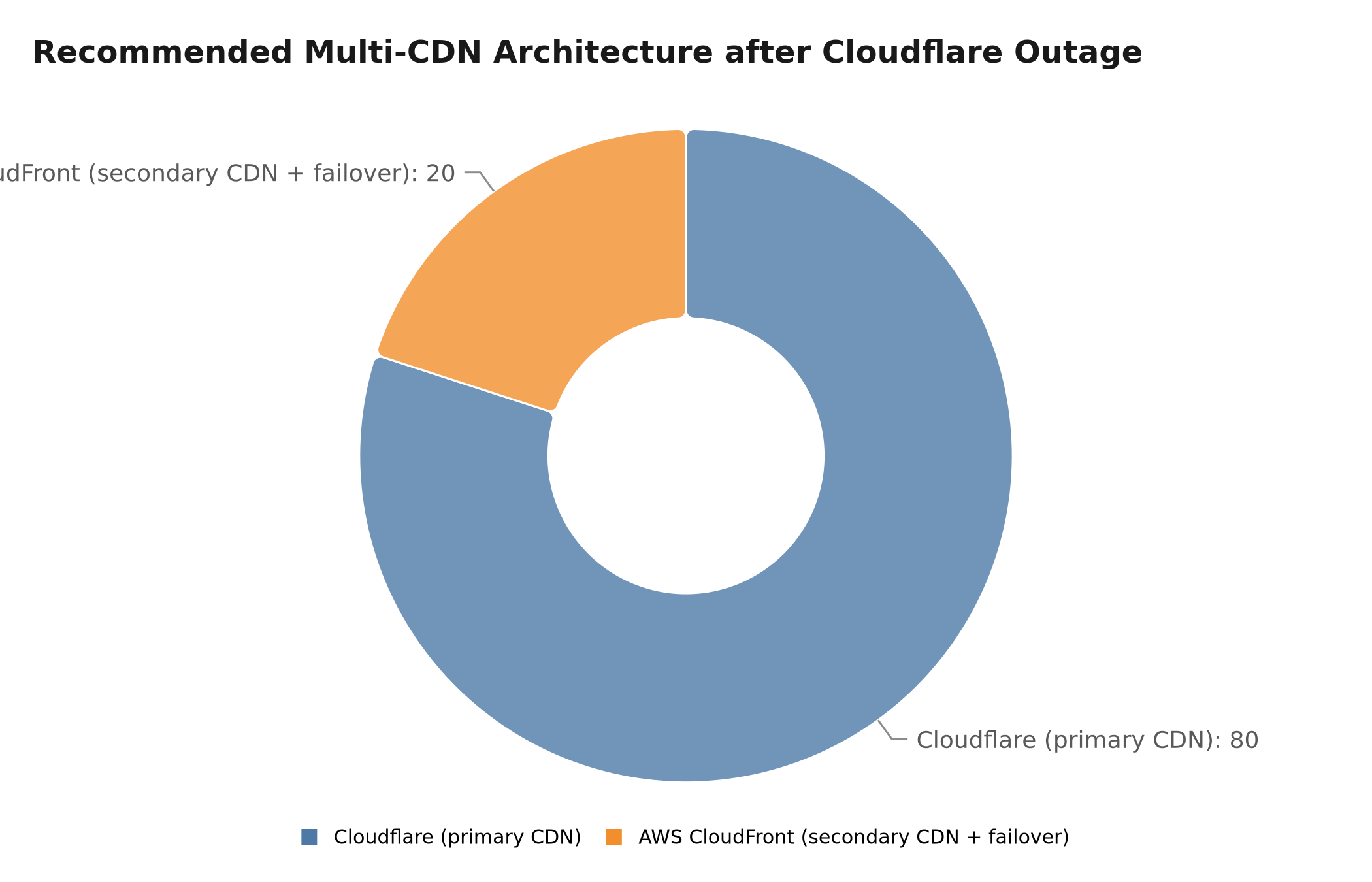 Recommended CDN traffic distribution for a resilient architecture after the Cloudflare outage
Recommended CDN traffic distribution for a resilient architecture after the Cloudflare outage
Concrete example:
Recommended architecture:
- Primary CDN: Cloudflare (80% of traffic)
- Secondary CDN: AWS CloudFront (20% of traffic + failover)
- Monitoring: Automatic outage detection
- Failover: Automatic in < 30 seconds
Setting up geo-redundant DNS with a short TTL is the key to rapid failover. If your TTL is 24 hours, your "automatic failover" will in reality be a 24-hour failover — the full duration of DNS propagation. Size your TTLs according to your target RTO, not default values. A TTL of 60 seconds is a good compromise for critical services requiring rapid failover.
Active health checks are the other pillar of effective failover: your DNS resolver or load balancer must continuously query both CDNs (primary and secondary) and automatically switch as soon as the primary responds with 5xx errors for more than 60 seconds. Services like AWS Route 53 Health Checks, Cloudflare Load Balancing, or third-party tools like UptimeRobot offer this capability natively.
2. Redundancy and High Availability
Principle: Have multiple instances of each critical service.
Implementation:
- Load balancing: Distribute traffic across multiple servers
- Data replication: Copy critical data across multiple geographic zones
- Stateless services: Design services to be restarted without data loss
Stateless design is particularly important: if your service maintains state in memory (user sessions, context data, local caches), a restart will cause data loss and degrade the user experience. By externalizing state into Redis, DynamoDB, or a replicated database, your instances become interchangeable and replaceable in seconds. For a deeper dive into how architecture choices impact performance, our analysis on how to divide load time by 10 covers stateless architectures and distributed caching in detail.
3. Circuit Breakers: Isolating Failures in Real Time
The circuit breaker is one of the most powerful resilience patterns from distributed systems engineering. Conceptualized by Michael Nygard in his book Release It! and popularized by Netflix with Hystrix (now replaced by Resilience4j), this pattern prevents a local failure from cascading to the entire system.
The pattern works through three distinct states, like an electrical circuit breaker:
Closed state (normal): requests flow freely to the called service. The circuit breaker continuously measures the error rate. If this rate exceeds a configured threshold — for example, 50% errors over the last 10 seconds — the circuit opens automatically.
Open state (failure detected): all requests are immediately rejected with a default response (fallback), without even attempting to contact the failing service. This prevents the funnel effect where a slow or failing service monopolizes resources (threads, connections, queue slots) of the caller and causes its own cascading failure. After a configurable delay (reset timeout), the circuit moves to the half-open state.
Half-open state (recovery test): a limited number of "test" requests are allowed through. If they succeed, the circuit closes and normal traffic resumes. If they fail, the circuit reopens for another waiting cycle.
Applied to the Cloudflare outage: if dependent services had implemented a circuit breaker on their calls to Cloudflare infrastructure, they could have switched to a degraded response (cached content, offline mode, secondary CDN) at the first 5xx errors, dramatically limiting the visible impact for end users. Instead of a blank HTTP 500 error page, the user would have seen a degraded but functional version of the service.
Available libraries include Resilience4j (Java/Kotlin), Polly (.NET), opossum (Node.js), and py-breaker (Python). On the infrastructure side, Istio Service Mesh and AWS App Mesh offer configurable circuit breakers without any application code changes — ideal for microservices architectures on Kubernetes.
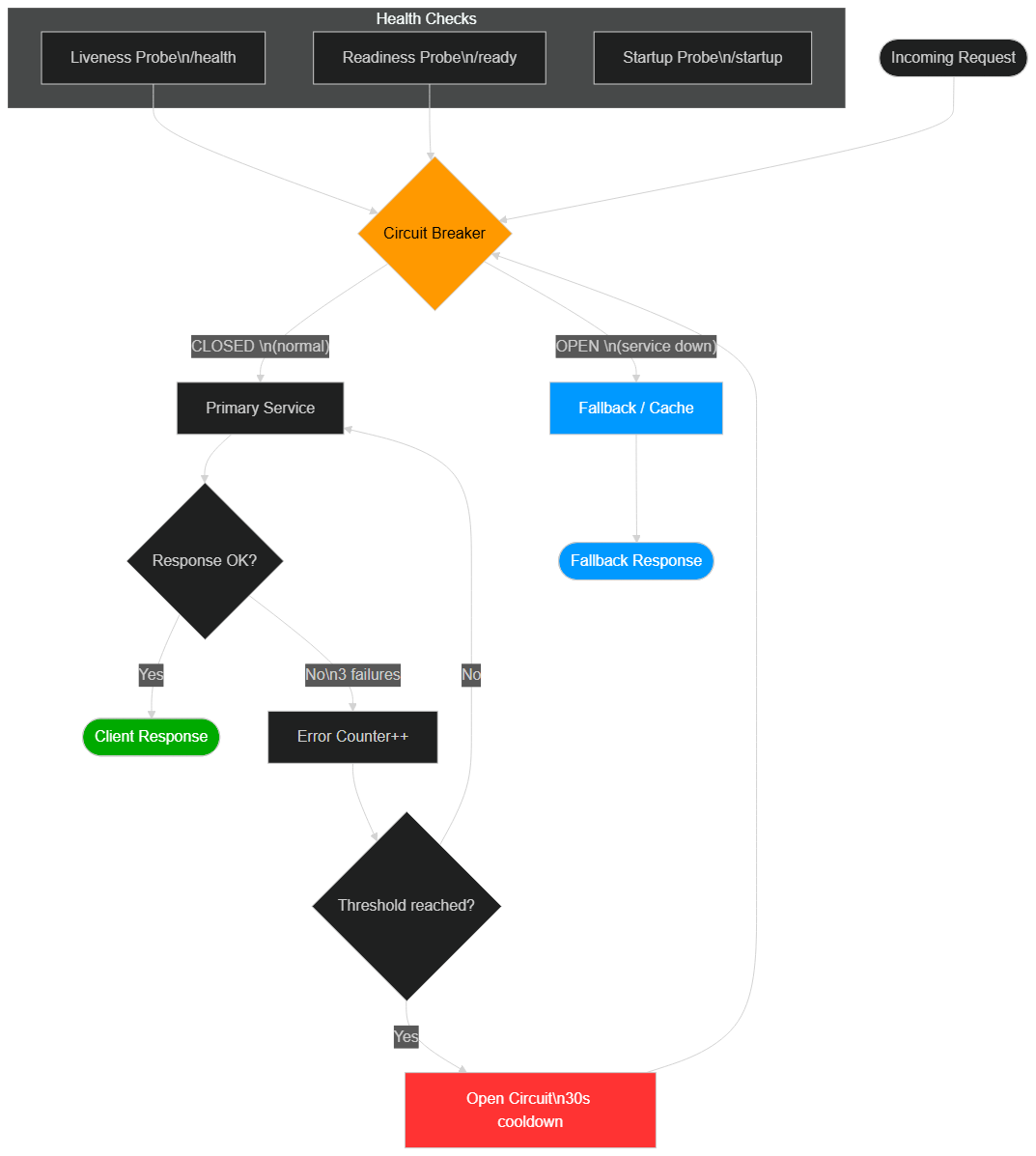 Defensive architecture: circuit breakers, active health checks, and failover routes for a resilient cloud infrastructure — illustrative scenario
Defensive architecture: circuit breakers, active health checks, and failover routes for a resilient cloud infrastructure — illustrative scenario
4. Resilience Metrics: Understanding and Calculating Your RTO, RPO, MTTR, and MTBF
Resilience cannot be improved without being measured. Four fundamental metrics define the resilience contract of a system and allow objectively comparing architectures and the investment levels they require.
RTO — Recovery Time Objective RTO defines the maximum acceptable service interruption duration. It is first and foremost a business decision. A Black Friday e-commerce site targets an RTO of 5 to 15 minutes. A B2B SaaS application in financial markets targets an RTO under 60 seconds. A corporate blog can tolerate an RTO of 4 to 8 hours. RTO directly determines your architecture requirements: a 5-minute RTO demands fully automated failover; a 24-hour RTO can make do with manual restoration from a snapshot.
RPO — Recovery Point Objective RPO designates the maximum amount of data that can be lost in a disaster scenario, expressed as a time duration. If your RPO is 1 hour, it means you can lose at most 1 hour of data. An RPO of zero — no data loss acceptable — requires synchronous real-time replication, which is expensive but essential for financial, medical, or contractual data.
MTTR — Mean Time To Recovery MTTR measures the average time observed between the start of an incident and the return to normal operation. It is an operational metric that reflects the effectiveness of your runbooks, monitoring tools, and on-call organization. A high MTTR often signals a lack of recovery automation, outdated runbooks, or too-slow incident detection. The Cloudflare outage described in this article shows an MTTR of approximately 4 hours — a figure that an organization with a multi-CDN and automatic failover in place could have reduced to under 2 minutes for their own users.
MTBF — Mean Time Between Failures MTBF measures the frequency of incidents. An MTBF of 90 days means one failure every 3 weeks on average. Improving MTBF requires eliminating recurring failure sources, strengthening configuration testing, and implementing the chaos engineering practices described below.
These metrics are not independent: reducing MTTR reduces the impact of each incident; increasing MTBF reduces their frequency. Combined, they define the actual availability of your service, often expressed in "nines": 99.9% availability corresponds to 8.7 hours of downtime per year, while 99.99% tolerates only 52 minutes of annual downtime. Technical debt is often the silent factor that prevents reaching these availability levels — our analysis on why your application costs 5x more to maintain details this link between code quality and operational resilience.
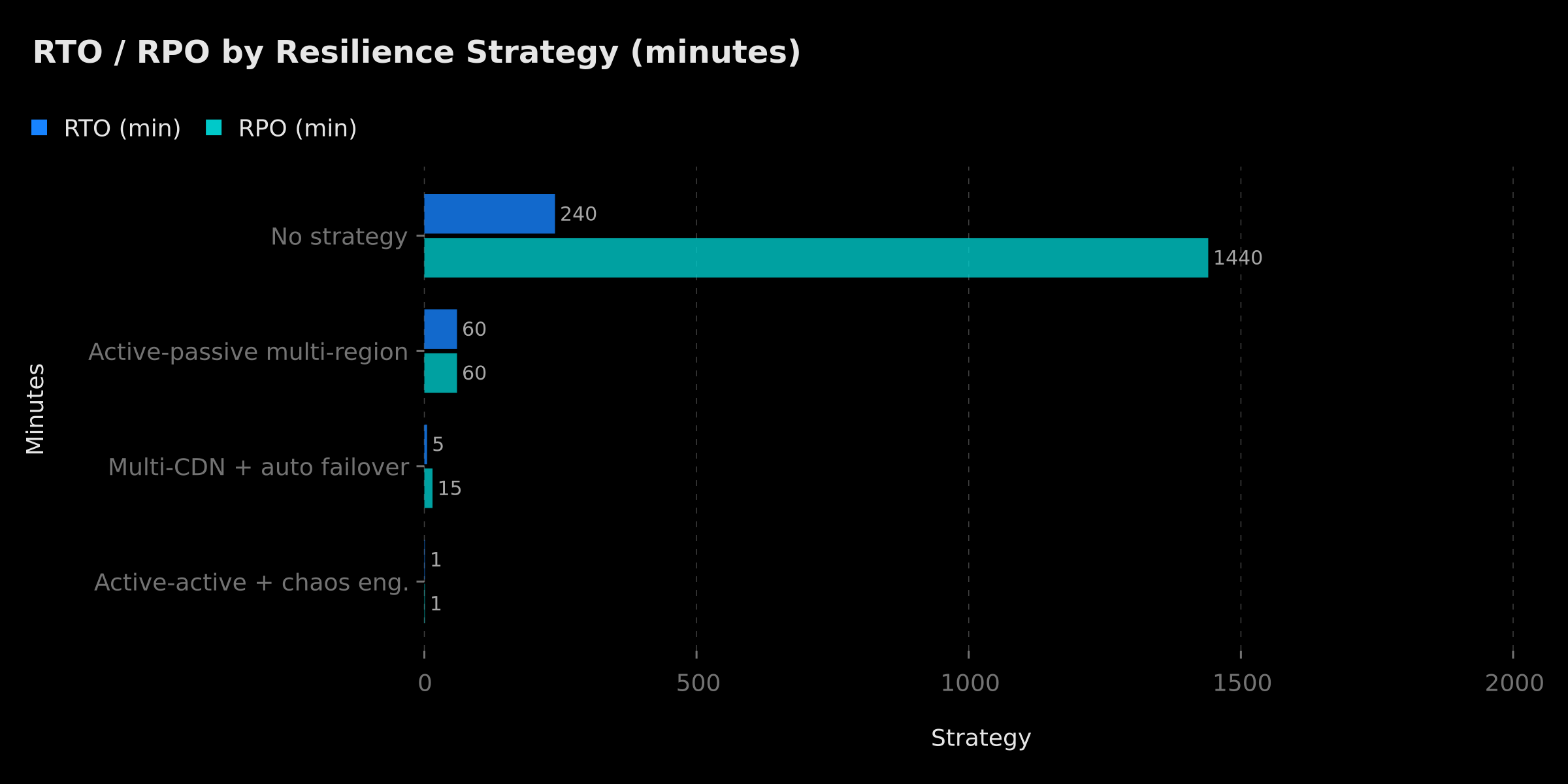 RTO and RPO metrics compared by infrastructure strategy — illustrative scenario based on documented patterns
RTO and RPO metrics compared by infrastructure strategy — illustrative scenario based on documented patterns
5. Advanced Monitoring and Alerts
Metrics to monitor:
- Configuration file sizes
- Request latency
- HTTP error rate
- Resource usage (CPU, memory, network)
- External service response times
Recommended tools:
- Datadog: Complete infrastructure monitoring with APM/logs/traces correlation
- New Relic: APM (Application Performance Monitoring) with AI-powered anomaly detection
- Prometheus + Grafana: Highly customizable and scalable open-source monitoring stack
- PagerDuty: Alert and incident management with intelligent escalation and on-call rotation
- Uptime Robot: External availability checks, free up to 50 monitors with SMS/email alerts
- StatusPage.io: Proactive communication of your service status to users and customers
6. Resilience Testing (Chaos Engineering)
Principle: Voluntarily test your system's resilience by simulating controlled failures.
Chaos engineering, popularized by Netflix in 2011 with the launch of Chaos Monkey, is based on a counter-intuitive idea: to be sure your system withstands failures, you must cause those failures yourself, in a controlled setting, before production does it to you at the worst possible moment. Netflix, operating hundreds of microservices in production on AWS, validated this approach at scale and significantly reduced its MTTR through a culture of continuous resilience testing.
Chaos engineering practices:
- Chaos Monkey: Random shutdown of EC2 instances in production to validate that services restart correctly without traffic loss
- Load testing: Simulating traffic spikes 2x, 5x, or 10x above normal to identify breaking points before they manifest in production
- Failover testing: Verifying that failover systems activate correctly and within the timeframes specified by your RTO
Chaos engineering tools available in 2026:
- Gremlin: SaaS platform with pre-built scenario library (network failures, CPU saturation, latency injection)
- LitmusChaos: CNCF-certified cloud-native open source solution, Kubernetes-specialized
- AWS Fault Injection Service (FIS): Natively integrated into AWS, supports fault injection on EC2, ECS, EKS, and RDS
- Azure Chaos Studio: Microsoft Azure equivalent with Azure Monitor integration
The recommended approach for getting started is GameDays: planned exercises where the team simulates a known failure in staging, observes system behavior, documents gaps from expectations, and corrects the issues identified. Only after validating all recovery mechanisms in staging should you progressively introduce experiments in production, always with a rollback plan and a kill switch that can be activated immediately.
Recommended frequency: Resilience unit tests in staging with each deployment; full GameDays at least once per quarter.
7. Recovery Automation
Principle: Automate recovery processes as much as possible to reduce MTTR.
Examples:
- Auto-scaling: Automatically increase resources during traffic spikes
- Auto-healing: Automatically restart crashing services using Kubernetes liveness probes or ECS health checks
- Automatic rollback: Automatically cancel deployments that cause errors — a 5xx error rate above 5% triggers an instant rollback to the previous version
Recovery automation is the factor that distinguishes organizations with a 2-minute MTTR from those with a 4-hour MTTR. It requires codified runbooks (Runbook as Code), integration between monitoring and deployment systems, and an SRE (Site Reliability Engineering) culture where reliability is a shared responsibility between dev and ops teams. To go further, see our guide on automating your release checklist with n8n and GitHub Actions, which details how to automate deployment safeguards from A to Z.
What Cloud Resilience Checklist Should You Apply After a Major Outage?
Before deploying your services to production, make sure you have checked each of these items:
Architecture
- Multi-cloud or multi-region architecture
- Automatic failover system
- Load balancing configured
- Data replication across multiple zones
Monitoring
- Real-time monitoring dashboard
- Alerts configured for critical metrics
- Centralized logging system
- Regular health checks
Continuity Plans
- Documented disaster recovery plan
- Failover tests performed recently
- Incident team trained and available
- Crisis communication prepared
Security and Configuration
- Automatic configuration validation
- Staging tests before production
- Security limits implemented
- Quick rollback system
Automation
- Auto-scaling configured
- Auto-healing enabled
- Automated deployments with validation
- Automated recovery scripts
Conclusion: Resilience is Not an Option, It's a Necessity
The Cloudflare incident of November 18, 2025 reminds us of a fundamental truth: no infrastructure is infallible. Even the largest companies, with the best teams and most advanced technologies, can experience major outages triggered by routine configuration changes.
The 5 Unavoidable Truths:
- Outages will happen: It's not a question of "if", but "when"
- Single dependence is dangerous: Diversifying your providers reduces risks
- Proactive monitoring is essential: Detect problems before they cause outages
- Regular testing saves lives: Test your continuity plans regularly
- Automation speeds recovery: Automating recovery processes reduces downtime — see our guide on the automated release checklist
Investment in resilience pays off:
- Reduction in downtime (MTTR - Mean Time To Recovery)
- Protection of company reputation
- Savings on direct revenue losses
- Increased customer and partner trust
Cloud infrastructure resilience is not a luxury reserved for FAANG companies. Every dollar invested in a multi-CDN architecture, a circuit breaker, or a disaster recovery plan generates a measurable return on investment the next time an outage occurs — and there will be one. Technical debt silently accumulating in an application is often the hidden factor that transforms a 30-minute incident into a 4-hour catastrophe: our analysis on why your application costs 5x more to maintain will help you quantify this impact and justify resilience investments to your decision-makers.
Every day without a resilience strategy = Russian roulette
A single major outage = Potential millions in losses
Resilience is your digital life insurance
If you deploy critical services to production, make sure you have implemented a resilient architecture, robust monitoring systems, and regularly tested continuity plans. This is the only way to protect your business against the inevitable failures of modern cloud infrastructure.
Ready to strengthen your infrastructure resilience? Contact BOVO Digital for an audit of your cloud architecture and the implementation of mitigation strategies tailored to your needs.
Tags
FAQ
What is a Single Point of Failure (SPOF) and how do you identify it in your infrastructure?
A SPOF (Single Point of Failure) is any component whose failure causes the complete shutdown of the system. To identify them: map all third-party services you depend on (CDN, DNS, payment APIs), identify those without redundancy, and assess the impact if each one fails. Cloudflare, managing 20% of global websites, represented a massive SPOF for the entire Internet ecosystem during this incident.
How do you set up automatic multi-CDN failover for your website?
Multi-CDN failover is implemented in three steps: reduce the DNS TTL of your domain to 60 seconds to allow rapid switches, configure a secondary CDN (AWS CloudFront or Fastly) with the same content, then set up an active health check every 30 seconds that automatically switches to the secondary CDN if the primary responds with 5xx errors for more than 2 consecutive minutes.
What is the difference between RTO and RPO in a business continuity plan?
RTO (Recovery Time Objective) is the maximum acceptable interruption duration — how long your application can remain offline without critical impact. RPO (Recovery Point Objective) designates the maximum amount of data you can afford to lose, expressed as a time window. A critical e-commerce site targets an RTO of 5 minutes and a near-zero RPO, while an internal blog can accept an RTO of 4 hours and an RPO of 24 hours.
What tools should you use to monitor cloud infrastructure resilience in 2026?
For comprehensive resilience monitoring: Uptime Robot or Better Uptime for external availability checks (free up to 50 monitors), Prometheus + Grafana for internal metrics, PagerDuty or OpsGenie for intelligent alerting with escalation, and StatusPage.io to communicate your service status to users. Datadog and New Relic now integrate AI-powered anomaly detection in 2026 to anticipate failures before they occur.
How do you practice chaos engineering without risking a production outage?
Start with a staging environment identical to production. Define a precise resilience hypothesis (e.g., "if the primary CDN fails, failover triggers in under 30 seconds"). Use Chaos Monkey, Gremlin, or LitmusChaos to inject controlled failures. Only test in production after validating your recovery mechanisms in staging, and always with an emergency kill switch that can stop the experiment immediately.
Ready to implement this?
Book a free 30-min strategy call with our experts
We'll analyze your situation and propose a concrete action plan.
Vicentia Bonou
Full Stack Developer & Web/Mobile Specialist. Committed to transforming your ideas into intuitive applications and custom websites.


