
DeepSeek V4 vs GPT-5.5: What the Open vs Closed AI War Actually Changes for Enterprises in 2026
In 48 hours, OpenAI ships GPT-5.5 and DeepSeek drops V4 — an open-source MIT multimodal model with 1M-token context running on Huawei chips. Complete analysis of what this changes for your AI automations, stack, and cloud bills in 2026.

Updated

DeepSeek V4 vs GPT-5.5: what the open vs closed AI war actually changes for enterprises in 2026
In 48 hours, the AI market has tilted. On April 23, 2026, OpenAI announced GPT-5.5, presented as "our smartest model yet," shipped across ChatGPT, Codex, and the API. On April 24, 2026, DeepSeek replied with V4 — an open-source model under MIT license, natively multimodal (text, image, video), with a 1 million token context window, running entirely on Huawei Ascend 950PR chips rather than Nvidia. Both models live the same weekend. Two opposite philosophies. A commercial and geopolitical war stepping out of research labs and into your enterprise workflows.
For the first time since GPT-4 launched in 2023, an open-source model is seriously competing with the top of the proprietary market — on public benchmarks, at fractional pricing, with no dependency on US hardware. This article breaks down what actually changes for executives, developers, and automation leads, and gives a clear decision grid for the only question that matters: which one to put in production for which use case?
1. What GPT-5.5 actually delivers
GPT-5.5 is not a generational leap, it is a major agentic consolidation. OpenAI no longer sells an assistant that answers questions; OpenAI sells an agent that executes complex multi-step tasks end to end — web research, data analysis, code generation, debugging, software operation, document and spreadsheet writing.
Measured performance
- 82.7% on Terminal-Bench 2.0: autonomous execution of CLI tasks.
- 78.7% on OSWorld-Verified: operating a real OS via GUI actions.
- 84.4% on BrowseComp: deep web browsing and multi-source research.
- Per-token latency on par with GPT-5.4: smarter without slowing down.
These scores, according to the official benchmarks published by OpenAI at launch time, position GPT-5.5 as the undisputed leader for agentic tasks in real-world environments. It's worth noting that inference benchmarks evolve rapidly — the figures cited here reflect the data available at the time this article was published.
What changes for workflows
The leap isn't really about answer quality — already excellent in GPT-5.4 — it's about agentic reliability. GPT-5.5 uses fewer tokens to finish the same task, self-corrects more, and chains multi-step plans without losing the thread after 30 minutes of execution. For a team automating support, sales, or content production, that means: less human supervision, fewer error loops, more delegable tasks without watching. If you already use n8n to orchestrate AI agents, this reliability improvement directly changes how many control nodes you need in your workflows — see our article on AI agents with n8n for architectural patterns.
The business model stays closed
All this lives in a 100% locked ecosystem: ChatGPT (Plus, Pro, Business, Enterprise), Codex, and the OpenAI API. No downloadable weights. No control over inference. No data sovereignty guarantee beyond contractual promises. And full dependency on a single vendor — exposed to pricing changes, moderation policy shifts, and availability incidents.
2. What DeepSeek V4 truly changes
V4 is a technical and political rupture. Not because it beats GPT-5.5 on every benchmark — it doesn't — but because it redefines the quality / price / sovereignty ratio that every enterprise had built its AI strategy on for the past 18 months.
Architecture and capabilities
DeepSeek V4 ships in two variants:
- V4-Pro: 1.6 trillion total parameters, 49 billion activated per token (MoE — Mixture of Experts).
- V4-Flash: 284 billion parameters, 13 billion activated per token — for high-volume use cases.
Both support a 1 million token context window with 384,000-token max output. That means you can feed an entire documentation base, a full codebase, or several hours of audio transcripts into a single request — no chunking, no fragile RAG.
Multimodality is native: text, images, and video are processed in a single latent space using Engram Memory technology, which solves the "lost in the middle" problem on very long contexts. On MMLU-Pro, V4 reaches 86.2 to 87.5% according to official public benchmarks available at time of publication — elite tier, only a few points behind the top proprietary models.
Pricing that breaks the market
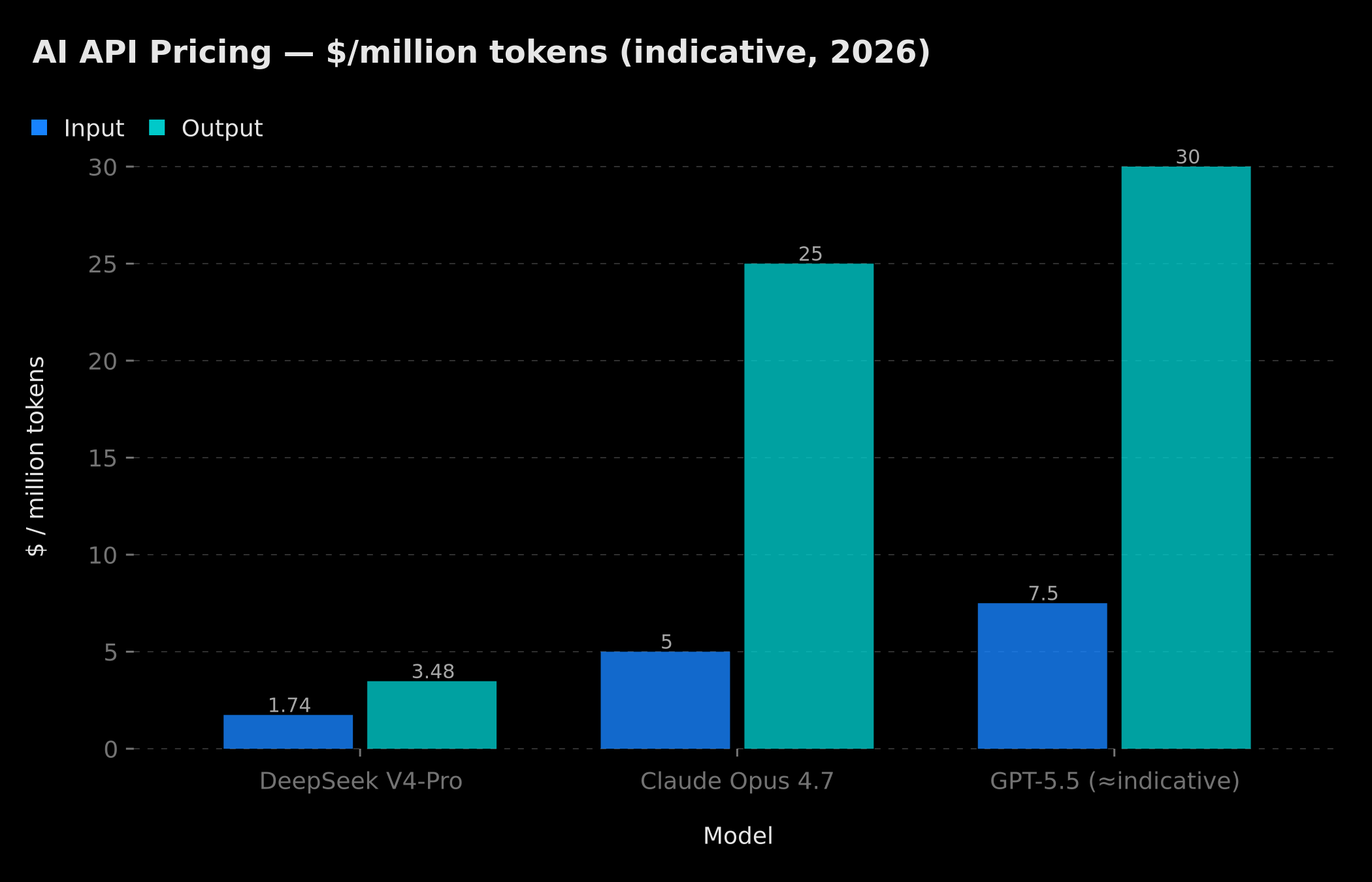 Input and output price comparison per million tokens: DeepSeek V4-Pro at $1.74/$3.48 vs Claude Opus 4.7 at $5/$25 and GPT-5.5 at indicative higher range
Input and output price comparison per million tokens: DeepSeek V4-Pro at $1.74/$3.48 vs Claude Opus 4.7 at $5/$25 and GPT-5.5 at indicative higher range
V4-Pro API is priced at $1.74 input / $3.48 output per million tokens. By comparison, GPT-5.5 stays on grids several times higher, and Claude Opus 4.7 charges $5 / $25 per million tokens. For an SMB consuming a billion tokens a month on its AI automations, this turns a 5-figure monthly bill into one 3 to 7 times smaller. The chart above is indicative: GPT-5.5 pricing was not officially published in a standardized format at time of writing, and the figure used reflects a consistent order-of-magnitude estimate based on publicly available information.
V4-Flash goes even lower, targeting very high-throughput deployments where reasoning depth can be traded for volume speed: ideal for classification, short summarization, or metadata generation at scale.
Real open source under MIT license
V4 is published under MIT license with full weights on Hugging Face. The model supports OpenAI ChatCompletions and Anthropic API protocols — meaning you can swap GPT or Claude in any existing stack with two config lines. That is a massive industrial argument: a company can download the weights, host on its own cluster, and stop sending data to OpenAI or Anthropic without rewriting any code.
The geopolitical layer: Huawei over Nvidia
The most strategic V4 element isn't in the model, it's in the target hardware. DeepSeek spent months rewriting parts of the code so V4 runs on Huawei Ascend 950PR chips, and granted early exclusive access to Huawei — a privilege denied to Nvidia and AMD. These chips deliver 2.8 times the performance of an Nvidia H20 (the most powerful chip currently cleared for export to China), at roughly $6,900 per unit — substantially cheaper than an H100.
Ahead of the launch, Alibaba, ByteDance and Tencent placed orders for hundreds of thousands of units of Huawei silicon. ByteDance alone plans $5.6 billion in 2026 spend. Ascend prices rose 20% on demand. A complete Chinese hardware + software ecosystem has formed in parallel to the US one — without depending on it.
For a European, African, or Middle-Eastern enterprise, this concretely opens a second AI sourcing option, independent from US export rules, sanctions, and political volatility between Washington and Silicon Valley.
3. How to choose between GPT-5.5, DeepSeek V4, and the alternatives
The right answer is almost never "one model for everything." A serious enterprise AI stack in 2026 uses 2 to 4 models in parallel, picked for their respective strengths. The decision tree below formalizes this reasoning.
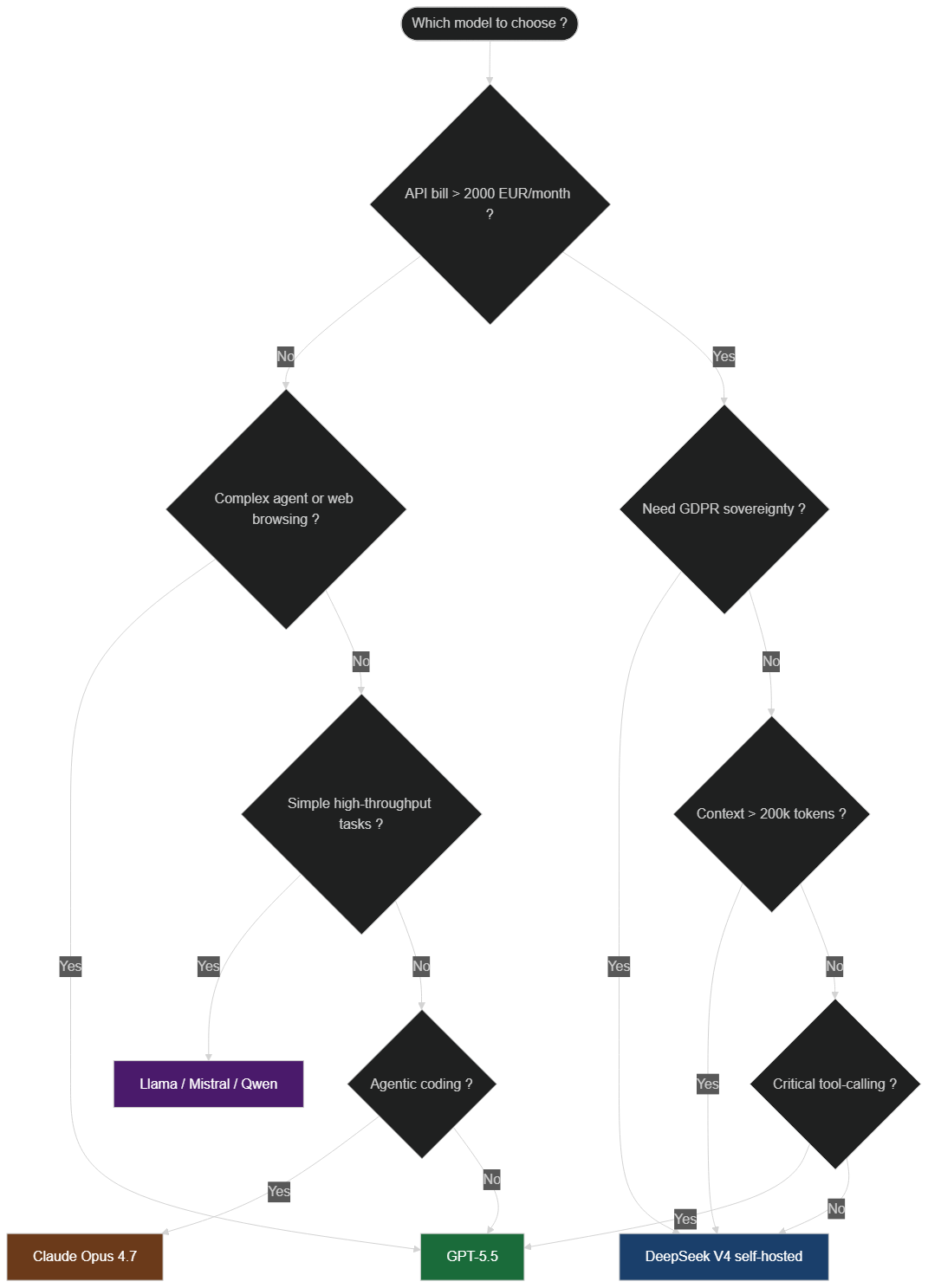 Model selection flowchart: GPT-5.5, DeepSeek V4, Claude Opus 4.7, or open-source models depending on budget, sovereignty needs, and task type
Model selection flowchart: GPT-5.5, DeepSeek V4, Claude Opus 4.7, or open-source models depending on budget, sovereignty needs, and task type
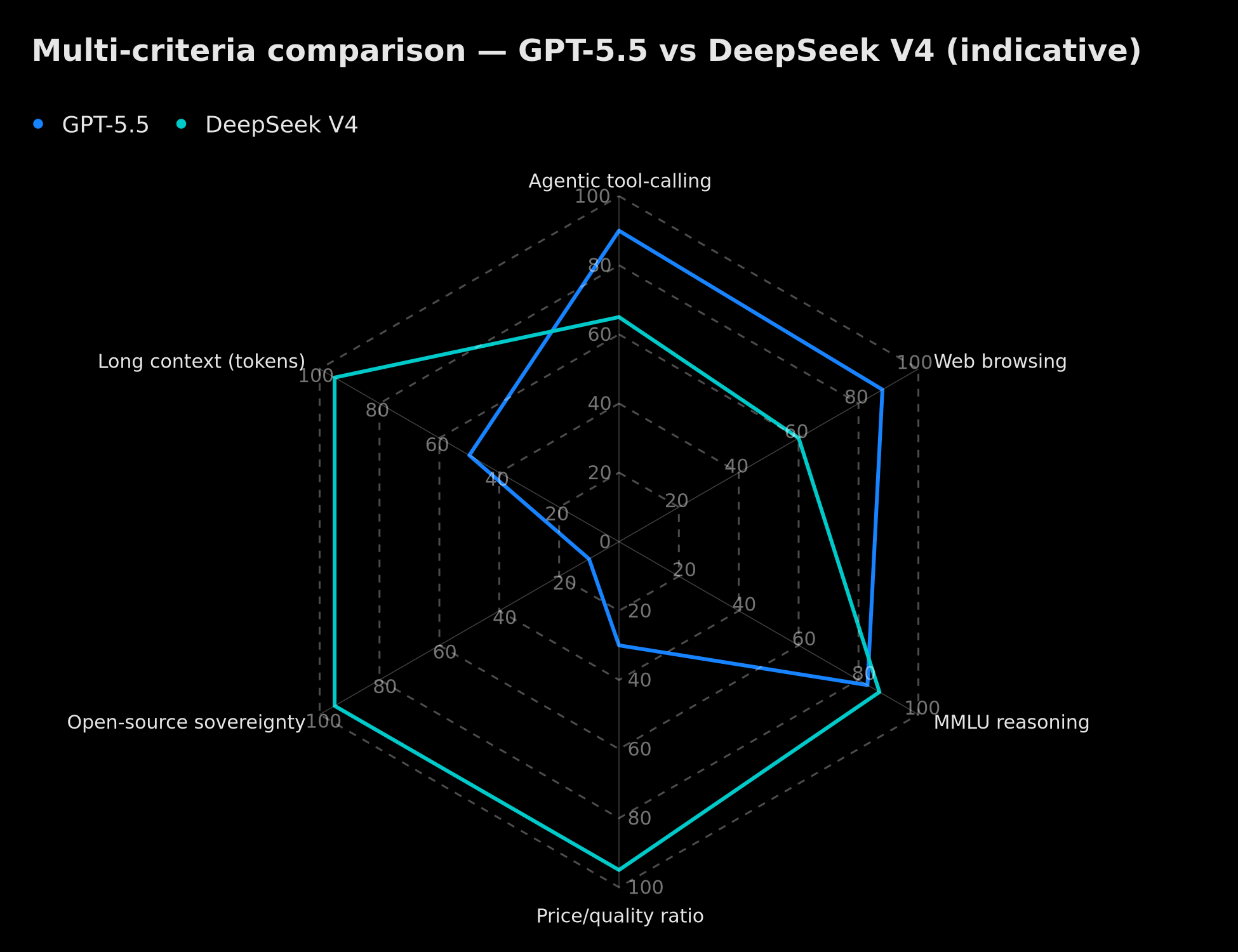 Radar comparison GPT-5.5 vs DeepSeek V4: agentic tool-calling, web browsing, MMLU reasoning, price/quality ratio, open-source sovereignty, long context (indicative)
Radar comparison GPT-5.5 vs DeepSeek V4: agentic tool-calling, web browsing, MMLU reasoning, price/quality ratio, open-source sovereignty, long context (indicative)
Pick GPT-5.5 if...
- You already have automations on the OpenAI API and a budget that supports the pricing.
- Your use cases need reliable agentic tool-calling, deep web browsing, or software operation (where GPT-5.5 clearly leads).
- You work with US clients who require providers in the OpenAI ecosystem.
- Time to production matters more than recurring cost — no GPU cluster to manage, all managed.
Pick DeepSeek V4 if...
- Your current API bill exceeds €2,000/month and the cost cut would matter strategically.
- You want to self-host the model (sovereignty, strict GDPR, professional secrecy, medical or banking data).
- You have very long context use cases: full codebase analysis, mass document processing, long transcript audits.
- You want to test technological dependency on the US ecosystem — option B in case of regulatory disruption.
Pick Claude Opus 4.7 if...
- You do serious agentic software development. On CursorBench, Opus 4.7 hits 70% versus 58% for Opus 4.6, and remains one of the most rigorous models for not hallucinating on long technical tasks.
- You need high-resolution vision: images up to 2,576 px, enabling reading dense UI screenshots or complex diagrams.
Recommended 2026 architecture
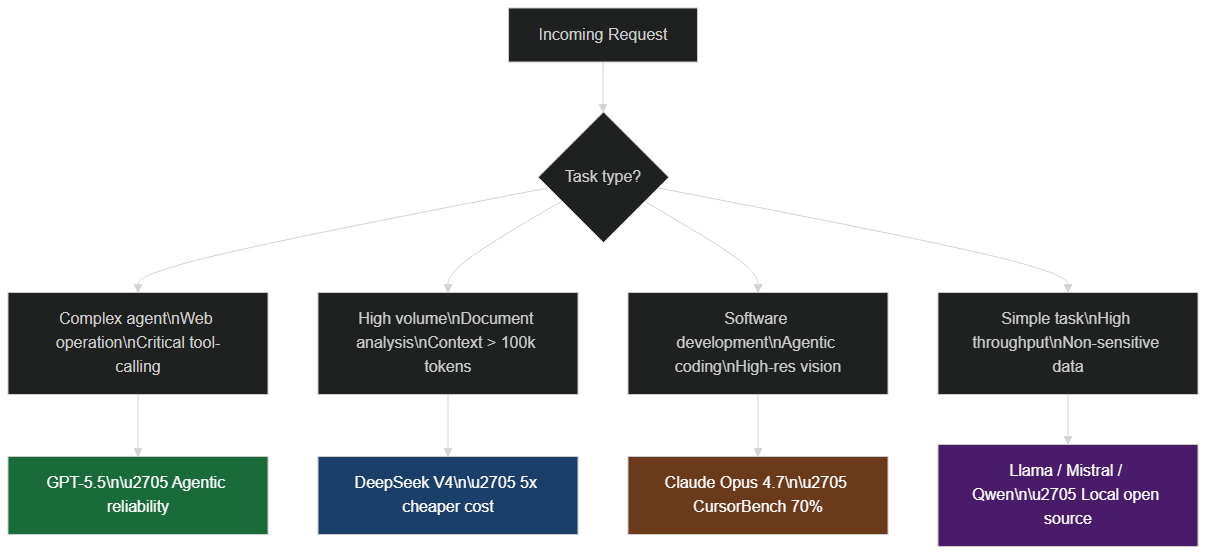 Multi-model routing logic: GPT-5.5 for complex agents, DeepSeek V4 for high volume, Claude Opus 4.7 for code, and open-source models for high throughput
Multi-model routing logic: GPT-5.5 for complex agents, DeepSeek V4 for high volume, Claude Opus 4.7 for code, and open-source models for high throughput
At BOVO Digital, we now design client workflows with a multi-model routing logic:
- GPT-5.5 for general agentic tasks and web operation.
- DeepSeek V4 for high-volume generation, mass document analysis, and internal processing where sovereignty matters.
- Claude Opus 4.7 for application code and sensitive technical agents.
- Smaller open-source models (Llama, Mistral, Qwen) for simple, very high-throughput tasks.
This multi-model architecture is exactly what we deploy in our AI automation solutions, our chatbots and conversational agents, and the AI-native SaaS we ship for clients.
4. Practical consequences for your business
For executives: revisit vendor contracts
If you signed an exclusive 2024 or 2025 contract with a single AI vendor, it's probably renegotiable now. The balance has shifted. Proprietary vendors now accept portability clauses, stronger SLAs, and price reductions you couldn't get six months ago. Beyond renegotiation, the strategic imperative is to move from single-vendor thinking to a portfolio approach: each model is a capability with its own cost curve, and treating them as interchangeable commodities is what allows you to remain agile as the market continues its quarterly reshuffles. Companies that locked in multi-year exclusives with a single provider in 2024 are now paying the premium not just in cash but in missed optimization opportunities.
For tech leads: pluralistic architecture
A vendor-abstracted stack — talking to an orchestrator (LangChain, LlamaIndex, or a custom layer) instead of a specific provider — has become a strategic requirement, not a nice-to-have. The technical debt of a monolithic OpenAI-coupled system is now quantifiable: it's the gap between your current bill and what you'd pay on DeepSeek for the same tasks.
For sales and marketing teams: re-pricing opportunity
AI automations sold to clients in 2025 (mass copywriting, lead qualification, conversational agents) saw their marginal cost drop 5-10x in months. Either you cut prices and grab market share, or you keep prices and grow margin. But not deciding means letting a competitor decide for you.
For freelancers: position on orchestration
The rare 2026 skill is no longer prompting. It's routing models intelligently across cost / quality / data sensitivity. Freelancers fluent in n8n, Make.com, LangGraph, and multi-model architectures ride a wave most of the market hasn't grasped yet.
5. Blind spots no one mentions
Huawei dependency risk
Choosing DeepSeek V4 hosted on Huawei chips means swapping a US dependency for a Chinese one. For critical use cases, both dependencies are risks — not solutions. A serious 2026 strategy includes at least one model running on European hardware (e.g., Llama or Mistral on OVHcloud, Scaleway, or Anthropic via European Vertex AI).
Hidden self-hosting costs
Downloading V4 weights under MIT isn't enough. Running a 1.6T MoE in production needs multiple high-end GPU servers, an MLOps team that handles sharding, quantization, optimized serving. For most SMBs, paying the DeepSeek API stays cheaper than self-hosting — and that's a decision to be made on numbers, not ideology.
Tool-calling quality lock-in
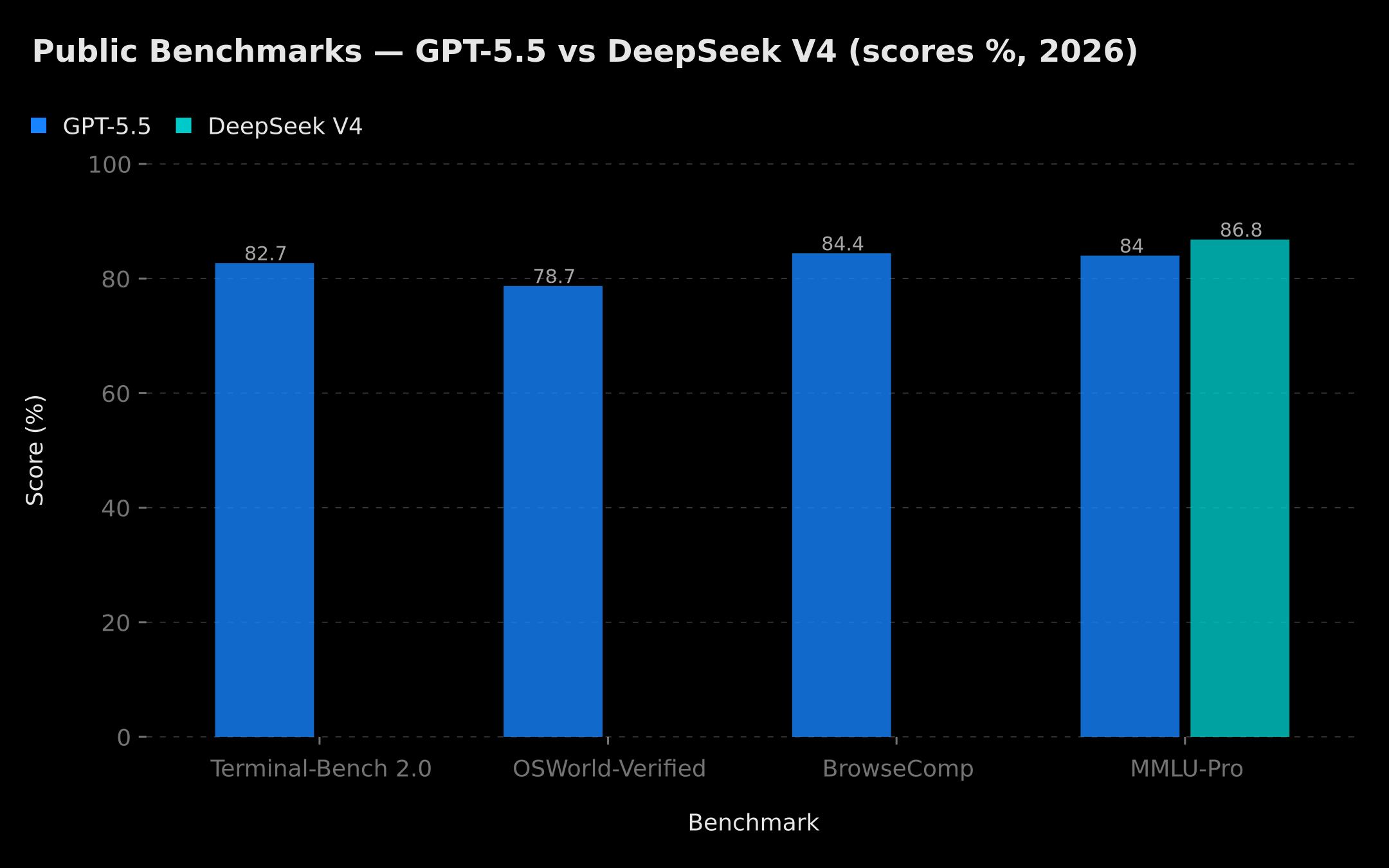 Public benchmark score comparison: Terminal-Bench 2.0, OSWorld-Verified, BrowseComp (GPT-5.5) and MMLU-Pro (GPT-5.5 vs DeepSeek V4) — data at time of publication
Public benchmark score comparison: Terminal-Bench 2.0, OSWorld-Verified, BrowseComp (GPT-5.5) and MMLU-Pro (GPT-5.5 vs DeepSeek V4) — data at time of publication
On complex agents, GPT-5.5 stays ahead simply because OpenAI invested 18 months hardening structured tool-calling, error handling, and multi-step plans. DeepSeek V4 supports the protocol, but field reports still show 10–20% robustness gaps on production agents. If your business relies on agents executing critical actions (payments, booking, CRM ops), start with GPT-5.5 or Claude, measure, then optimize. To mitigate hallucinations in agentic workflows regardless of your model choice, see our comprehensive guide on avoiding AI hallucinations in enterprise settings.
6. Inference speed, context windows, and real-world use cases
Beyond academic benchmarks, two practical dimensions structure production choices: inference speed and real-world long-context management.
Inference speed: V4-Flash vs V4-Pro vs GPT-5.5
DeepSeek V4-Flash is built for low-latency at scale. Thanks to its lightweight MoE architecture (13 billion activated parameters per token), it achieves generation speeds comparable to much smaller open-source models while maintaining substantially higher reasoning quality. It's the reference choice for real-time applications: high-traffic chatbots, voice assistants, high-cadence document classification pipelines.
V4-Pro trades speed for depth: with 49 billion activated parameters per token, it dominates on long analysis tasks, multi-step reasoning, and synthesis over massive contexts. GPT-5.5 sits in a hybrid position: its per-token latency is reportedly comparable to GPT-5.4 according to OpenAI, but its closed architecture prevents independent published measurements as of this writing.
1 million tokens: what does it change in practice?
DeepSeek V4's 1 million token context window is not a marketing figure. In practice, it redefines the usefulness of RAG. A standard RAG pipeline splits documents into chunks, indexes them in a vector store, and retrieves a fraction before each query — a process that introduces approximations and information loss between passages. With 1 million tokens, it becomes possible to directly inject a 400-page annual report, a 150,000-line codebase, or six months of support tickets into a single request — no chunking, no coherence loss.
This opens three use cases that were inaccessible 12 months ago: full codebase audit in a single pass, synthesis of massive legal or regulatory documentation without pre-filtering, and persona modeling from very long conversation histories. To understand the architectural trade-offs between RAG and direct context injection, see our article Why Your AI Is Dumb and That's Normal — RAG.
HumanEval, MATH, and GSM8K: what coding and reasoning benchmarks reveal
Several standardized benchmarks assess models on specific dimensions beyond MMLU-Pro. On HumanEval (Python code problem solving), both DeepSeek V4 and GPT-5.5 generation models sit in the high range based on public data available at time of publication — with GPT-5.5 maintaining an edge on tasks requiring multi-step execution and debugging, and DeepSeek V4 proving competitive on pure code completion.
On MATH (advanced mathematical reasoning) and GSM8K (elementary math word problems), the DeepSeek generation has historically demonstrated strong performance consistent with its MMLU-Pro scores. However, precise V4-specific figures for these benchmarks were not all available in official documentation at the time of writing — we recommend checking the official benchmarks published by DeepSeek and OpenAI directly for up-to-date comparisons.
7. Open vs closed AI: what licenses actually mean
The distinction between open and closed AI goes far beyond the right to download weights. It touches directly on governance, security, customization, and regulatory control.
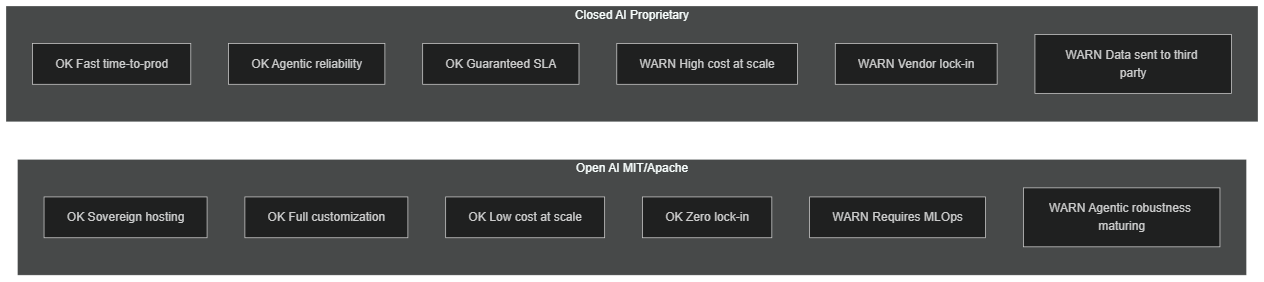 Structured comparison of open vs closed AI: sovereign hosting, customization, cost at volume, lock-in, MLOps requirements, agentic reliability
Structured comparison of open vs closed AI: sovereign hosting, customization, cost at volume, lock-in, MLOps requirements, agentic reliability
What the MIT license actually changes
Under MIT license, DeepSeek V4 can be commercialized, modified, embedded in SaaS products, and redistributed without restriction and without royalties. This means a company can fine-tune the model on its own proprietary data, embed it into a product it sells, and retain full intellectual property over any adaptations — something no proprietary license allows.
From a GDPR standpoint, on-premise hosting of MIT model weights provides legal certainty that API-based models cannot guarantee: your users' data never leaves your infrastructure, no third-party vendor can access it, and you maintain full control over access logs. For sectors like healthcare, banking, law, or defense, this is a non-negotiable prerequisite.
Security auditing and trust
A frequently underestimated advantage of open source is auditability. With an MIT model, your security team can inspect weights, analyze behaviors, and instrument inference at every layer. With a proprietary model, you trust the vendor's SOC 2 certifications and privacy policies — with no possibility of independent verification. For critical applications (contract analysis, fraud detection, sensitive content moderation), this transparency gap is a strong argument for open source.
Fine-tuning as a competitive advantage
The MIT license also allows domain specialization through supervised fine-tuning. A law firm can train V4 on thousands of sector-specific contracts. An e-commerce player can adapt it to its product catalog and return policies. A healthcare operator can create a version compliant with local medical nomenclatures. This level of customization is impossible with proprietary models, where fine-tuning — when offered at all — remains partial, expensive, and non-auditable.
To see how open-source models like Gemma can be self-hosted with Ollama and integrated with n8n for private, cost-free AI agents, read our practical tutorial Gemma 4 + Ollama + n8n: Free Private Local AI Agent.
8. The open AI ecosystem accelerates in 2026
DeepSeek V4's release is not an isolated event. It is part of a structural trend accelerating over the past 24 months: the open-source AI ecosystem is catching up with proprietary at a speed most analysts did not anticipate.
The Hugging Face effect and the normalization of weights
Hugging Face surpasses 800,000 publicly published models in 2026. The infrastructure for hosting, versioning, and deploying models has industrialized: Hugging Face Inference Endpoints, vLLM, TGI (Text Generation Inference), and Ollama now allow a modestly-sized engineering team to deploy a model with tens of billions of parameters in a matter of hours — without research-level MLOps expertise.
Ollama in particular has democratized local execution of large models on consumer hardware — M3 MacBook Pro, gaming PCs, entry-level servers — making local AI accessible to freelancers and SMBs who had zero AI cloud budget 18 months ago.
Enterprise adoption accelerates
Major European enterprises — banks, insurers, industrials — are embedding open-source AI into their 2026 roadmaps with a sovereignty logic that was not as explicit in 2024. The question is no longer "is open source ready?" but "which part of my stack must stay proprietary?" Answers converge on a hybrid model: proprietary for critical client-facing agents, self-hosted open source for sensitive data processing and high-volume workloads.
The next frontier: specialized reasoning models
Beyond generalist models like V4 and GPT-5.5, 2026 sees the emergence of open-source specialized models — computational chemistry, genomics, legal, quantitative finance — that outperform generalists in their domains while being substantially cheaper to run. This trend toward vertical specialization will redefine engineering team selection criteria over the next 12 months. For teams building AI agent workflows, this plurality of specialized models demands intelligent orchestration capability — exactly what tools like n8n are built for.
The practical implication is this: the competitive advantage in enterprise AI is no longer about access to the best single model. It's about the ability to compose, route, and continuously optimize across a dynamic portfolio of models as their capabilities and prices evolve. Organizations that build that orchestration muscle now — in tooling, in team skills, and in architecture — will be structurally faster to adapt when the next wave of model releases arrives in Q3 and Q4 2026.
How BOVO Digital can help
At BOVO Digital, we've spent 4+ years helping companies on three axes that this model war just upended:
- Multi-model AI architecture: stacks where DeepSeek V4, GPT-5.5, Claude, and open-source models are routed per use case. Learn more.
- Conversational agents and chatbots custom-built (WhatsApp, web, voice) with optimal model selection per conversation. See our offer.
- AI-native SaaS and apps: Next.js + Flutter development with deep model integration, deployed on flagship projects like MaxSEO AI and Illico Voice AI.
We publish a detailed quote within 24 hours after a free 30-minute scoping call.
Conclusion
The simultaneous launch of GPT-5.5 and DeepSeek V4 doesn't change AI — it changes your bargaining power with AI vendors. For the first time, an open-source model genuinely competes at the top, at fractional pricing, on non-US hardware. The right reflex in 2026 isn't picking a side. It's building a pluralistic stack, measuring real per-use-case costs, and keeping the freedom to switch when the market moves again.
Licenses, benchmarks, and hardware architectures are not technical details reserved for AI teams — they define your strategic autonomy for the next three years. A single-vendor dependency is a quantifiable, avoidable business risk that the events of 2026 have made impossible to ignore.
And it will move. The next shift comes in 3 to 6 months — not 18. The teams that will capture the most value from that next shift are those who started building model-agnostic infrastructure today, not those who waited for the market to stabilize — because in AI, it never does.
Let's talk about your 2026 AI strategy or check our delivered AI projects.
Tags
FAQ
Is DeepSeek V4 actually better than GPT-5.5?
Not overall. GPT-5.5 still leads on agentic tool-calling, software operation (78.7% on OSWorld-Verified), and web browsing. DeepSeek V4 catches up on reasoning benchmarks (86-87% MMLU-Pro), dominates on price/quality ratio ($1.74/M tokens vs several times more for GPT-5.5), and on native multimodality with 1M-token context. The right play is to use them together by use case.
Can I really self-host DeepSeek V4?
Yes — weights are MIT-licensed on Hugging Face. But it's a 1.6T MoE: budget multiple high-end GPU servers and an MLOps team. For most SMBs, the official DeepSeek API stays more cost-effective. Self-hosting only makes sense under hard sovereignty constraints (GDPR, medical, banking secrecy) or very high volumes.
Why does DeepSeek run on Huawei chips instead of Nvidia?
Two reasons: bypass US export restrictions on top-tier chips into China, and build an autonomous hardware + software stack. Huawei Ascend 950PR delivers 2.8x the performance of an Nvidia H20, at around $6,900 per unit. Alibaba, ByteDance, and Tencent placed massive orders ahead of launch.
Should I drop OpenAI and GPT-5.5 for DeepSeek?
No. The right play is a multi-model architecture: GPT-5.5 for critical agents and browsing, DeepSeek V4 for high volume and document analysis, Claude Opus 4.7 for code, and smaller open-source models for simple high-throughput tasks. This plurality reduces single-vendor lock-in and optimizes cost per use case.
How much can I save switching to DeepSeek V4?
Depending on your usage profile, between 60% and 85% of your current API bill. Order of magnitude: V4-Pro at $1.74/$3.48 per million tokens vs Claude Opus 4.7 at $5/$25 and GPT-5.5 in the same upper range. For 1B tokens/month, the saving can reach $18,000–30,000 annually.
How does BOVO Digital help select and integrate these models?
We design multi-model architectures with intelligent routing (n8n, LangGraph, custom orchestrators) that send each request to the best-fit model on cost / quality / sensitivity. We integrate models into Next.js SaaS, Flutter apps, WhatsApp chatbots, and Make/n8n automations. Start with a free scoping call via /en/agence-automatisation-n8n.
What is the difference between DeepSeek V4-Pro and V4-Flash?
V4-Pro (1.6T total parameters, 49B activated) is built for complex tasks requiring deep reasoning and long context. V4-Flash (284B parameters, 13B activated) targets high-volume, low-latency workloads — ideal for chatbots, classification, or simple summarization at scale. On public benchmarks, V4-Pro performs noticeably better on reasoning tasks.
Is open-source AI as secure as proprietary models?
It depends on how you define secure. Open-source models allow full audits of code and weights — something proprietary models do not offer. But they require you to secure the hosting infrastructure yourself. A proprietary model delegates that responsibility to the vendor. For highly sensitive data, self-hosted open-source on controlled infrastructure is often the most secure option.
Ready to implement this?
Book a free 30-min strategy call with our experts
We'll analyze your situation and propose a concrete action plan.
William Aklamavo
Web development and automation expert, passionate about technological innovation and digital entrepreneurship.


