
NVIDIA's Nemotron 3 Nano Omni: What It Changes for Multimodal Automation
NVIDIA just launched a model that sees, hears and understands text — all at once, 9x more efficiently. For automation, this is a turning point. Here's what it concretely opens up.

Updated

NVIDIA's Nemotron 3 Nano Omni: What It Changes for Multimodal Automation
For several years, AI automation relied on a fragmented architecture: one model to process text, another to analyze images, a third to transcribe audio. Each brick communicated with the others via APIs, delays and stacked costs. Multimodal AI agents remained a promise on paper — expensive to build and difficult to maintain at scale.
NVIDIA just broke this model with the launch of Nemotron 3 Nano Omni: a unified multimodal model that processes vision, audio and language simultaneously, with announced efficiency 9 times superior to current separate architectures. For businesses looking to automate complex processes involving multiple types of data, this is a significant breakthrough. This article explains why, how to integrate it into your existing workflows, and what it concretely changes for your operations.
What Nemotron 3 Nano Omni Is
Nemotron 3 Nano Omni isn't simply "a model that does everything." Its technical particularity is a shared attention space between the three modalities. Where GPT-4o processes image and text sequentially with partial context, Nemotron 3 Nano Omni processes all three streams in the same representation space.
In practice: if you send a photo of a damaged product with an audio message from the customer describing the problem, the model understands the relationship between the two without you having to explicitly connect them. Visual information directly influences textual reasoning and vice versa. This is a fundamental architectural difference, not an incremental improvement.
Announced specifications according to the official NVIDIA documentation:
- Multimodal latency: 0.8 to 2 seconds (vs 3-8 seconds with separate pipelines)
- Relative cost: ~30% of the cost of an equivalent GPT-4o Vision + Whisper pipeline
- Self-hosting possible via NVIDIA NIM (A100/H100/L40S GPU)
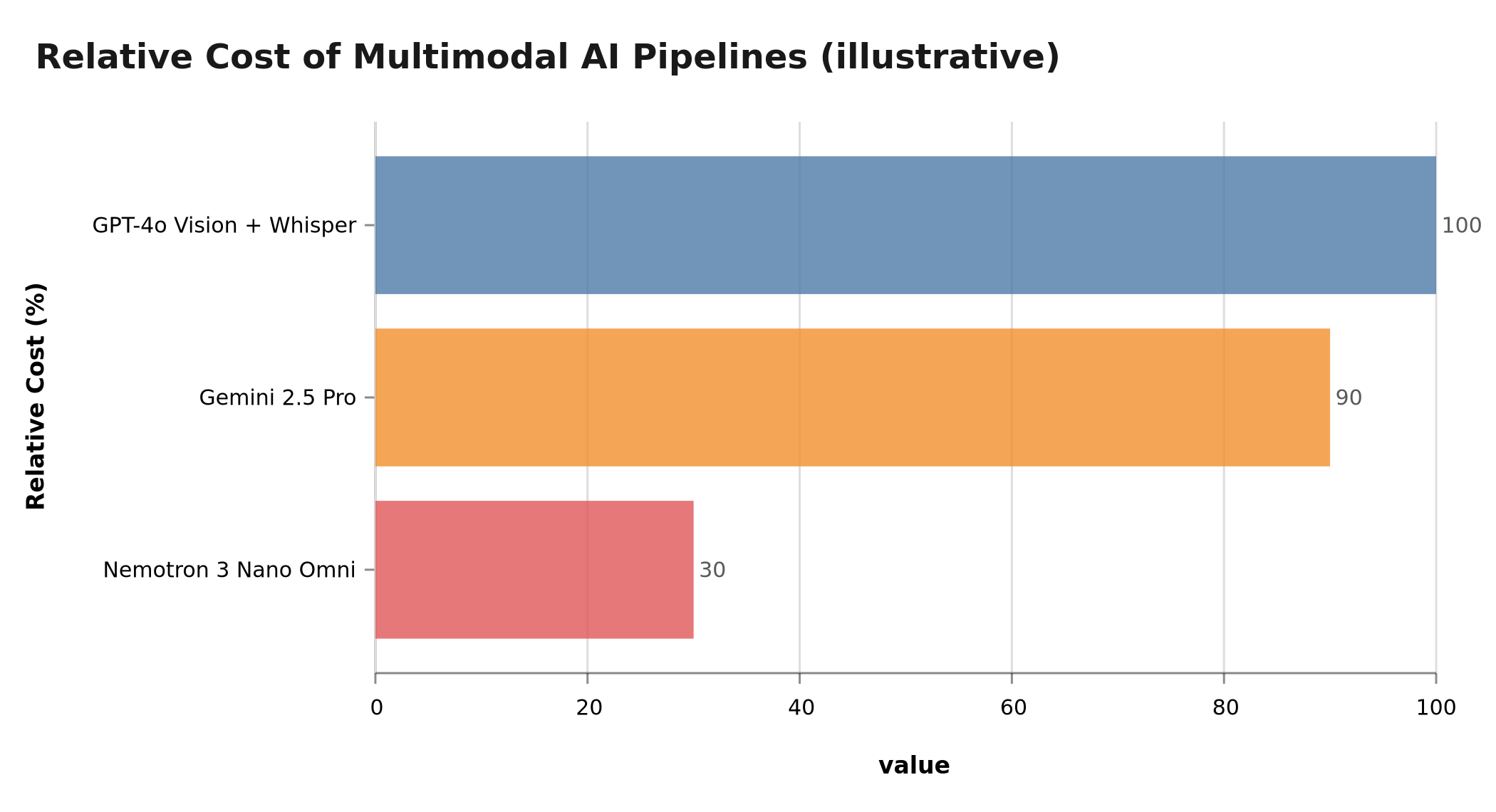 Nemotron 3 Nano Omni at ~30% of the cost of an equivalent GPT-4o pipeline — illustrative data
Nemotron 3 Nano Omni at ~30% of the cost of an equivalent GPT-4o pipeline — illustrative data
Architecture and Technical Functioning
The Nemotron family from NVIDIA is built on the Megatron architecture, a distributed training framework developed internally and documented in NVIDIA research publications. The "Nano" variant refers to optimized models designed for efficient deployment, with a calculated trade-off between capability and resource consumption. The "Omni" designation refers to the omnimodal architecture: the ability to process multiple types of data without context switching or pipeline changes.
According to the official NVIDIA documentation, the model relies on a unified visual encoder capable of processing static images, video streams and audio streams, whose representations are projected into the same token space as language. This unification is what enables Nemotron 3 Nano Omni to be jointly trained on multimodal pairs — rather than on unimodal data to which adapters were subsequently added.
On the licensing side, NVIDIA offers Nemotron 3 Nano Omni under the NVIDIA Open Model License, which allows commercial use with certain restrictions on redistribution and fine-tuning. This license is more permissive than the proprietary licenses of OpenAI or Anthropic models, while maintaining safeguards against malicious use. For companies looking to customize the model on their business data, NVIDIA offers fine-tuning tools via the NVIDIA AI Foundry platform.
Deployment is primarily done via NVIDIA NIM (Neural Inference Microservice), a standardized service layer that exposes the model as an OpenAI-compatible REST API. Concretely, this means that an n8n or Make pipeline already connected to GPT-4o can switch to Nemotron 3 Nano Omni by only changing the URL and API key — without modifying the payload structure.
Why "Nano" Models Represent a Strategic Shift
The AI market is no longer played out only on large models. Since 2024, a clear underlying trend has emerged: "small" or "Nano" models are gaining relevance in production architectures. This trend is not a compromise due to lack of resources — it's a deliberate strategy.
Three reasons explain why Nano models are becoming strategic for businesses in 2026.
Latency changes everything for user experience. A model that responds in 1 second vs 5 seconds isn't just "faster" — it's the difference between a usable product and a laboratory prototype. For customer support applications, real-time analysis or embedded assistants, latency is a functional constraint, not an aesthetic preference.
Cost at scale is exponential. At €0.08 per interaction, a multimodal pipeline seems manageable for 100 requests. At 100,000 requests per month, that's €8,000 monthly. With a Nano model at €0.025 per interaction, the same volume costs €2,500 — a saving that itself funds several hires. Nano models transform use cases that are "theoretically possible" into use cases that are "economically viable."
Edge computing changes deployment constraints. Not all use cases can send data to the cloud. Medical data, confidential documents, security video streams — all contexts where data must remain on-site. Nano models are designed to run on lighter infrastructures: a single NVIDIA A100 GPU card is sufficient to serve several hundred requests per minute with Nemotron 3 Nano Omni via NIM.
If you're already exploring local models for automation, the approach is similar to what we documented in our guide Gemma 4 Tutorial with Ollama and n8n — free private local AI agent. The difference with Nemotron 3 Nano Omni: native multimodal capabilities that open up use cases impossible with a text-only model.
Multimodal AI Agents: What It Concretely Changes
A multimodal AI agent is not simply a model that "sees" and "speaks." It's a system that can make decisions based on heterogeneous signals — an image, text, audio — treating them as a coherent whole, not as separate data.
The distinction is important. In a classic pipeline, the agent first receives the transcription of an audio, then the analysis of an image, then combines the two texts to reason. Each step introduces latency and information loss: the transcription doesn't capture tone, the image analysis doesn't capture contextual nuance. In a native multimodal pipeline, the agent processes everything simultaneously — vocal tone, image expression and textual context are all present in the same representation space at the moment of reasoning.
What this changes in practice:
- A customer support agent can see the photo of the problem AND hear frustration in the customer's voice in the same call, adjusting its response accordingly.
- A quality control agent can analyze a production video and correlate it with operator audio comments, without intermediate ETL.
- An HR agent can evaluate a video presentation (content + tone + body language) and produce structured feedback in a single call.
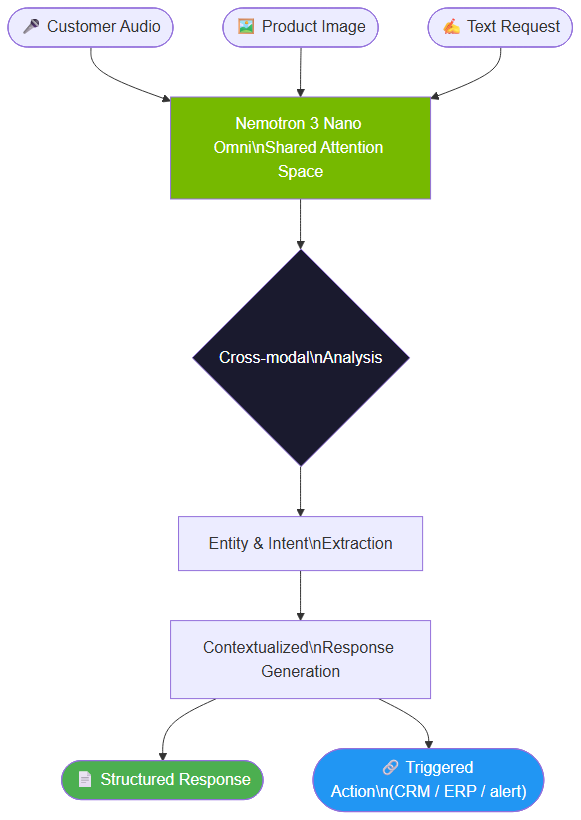 Multimodal agent architecture: three input streams enter the shared attention space and produce a contextualized action or response
Multimodal agent architecture: three input streams enter the shared attention space and produce a contextualized action or response
The comparison with competing architectures is revealing. OpenAI's GPT-4o offers a multimodal approach, but real-time audio handling remains distinct from the vision-text pipeline. Anthropic's Claude 3.5 Sonnet excels on text and static images, but does not natively integrate audio. These are not criticisms — these are different architectural choices. Nemotron 3 Nano Omni bets on native unification rather than flexible modularity.
To understand how the overall model landscape is evolving, our analysis of the open vs closed AI war in 2026 provides the strategic context for these decisions.
Nemotron Nano vs Gemini Nano vs Apple Intelligence
The race for edge models is accelerating. In 2026, NVIDIA is not alone in wanting to bring powerful AI to limited infrastructures. Here's how the three main players position themselves according to their public documentation.
NVIDIA Nemotron 3 Nano Omni targets edge server environments: private datacenter, NVIDIA Jetson for robotics and industry, on-premise corporate servers. Its value proposition is native multimodal with integrated audio, via a standard API deployable in NIM. The open commercial license is a real competitive advantage for companies that want to move away from proprietary APIs.
Google Gemini Nano is designed to run directly on smartphones (Android, Pixel, Galaxy) and targets on-device use cases: summaries, reply suggestions, writing assistance. Its multimodal capabilities are real but text and image-oriented — native audio is not at the same level of integration as Nemotron. Gemini Nano's strength is its Android ecosystem and direct integration into Google applications.
Apple Intelligence follows a different philosophy: ultra-optimized on-device models for Apple Silicon chips (A17 Pro, M4), with a focus on absolute privacy and consumer use cases (writing, summaries, Photos, Siri). Apple Intelligence does not expose a public API — this is an advantage for end users, but an impossibility for developers who want to integrate it into business workflows.
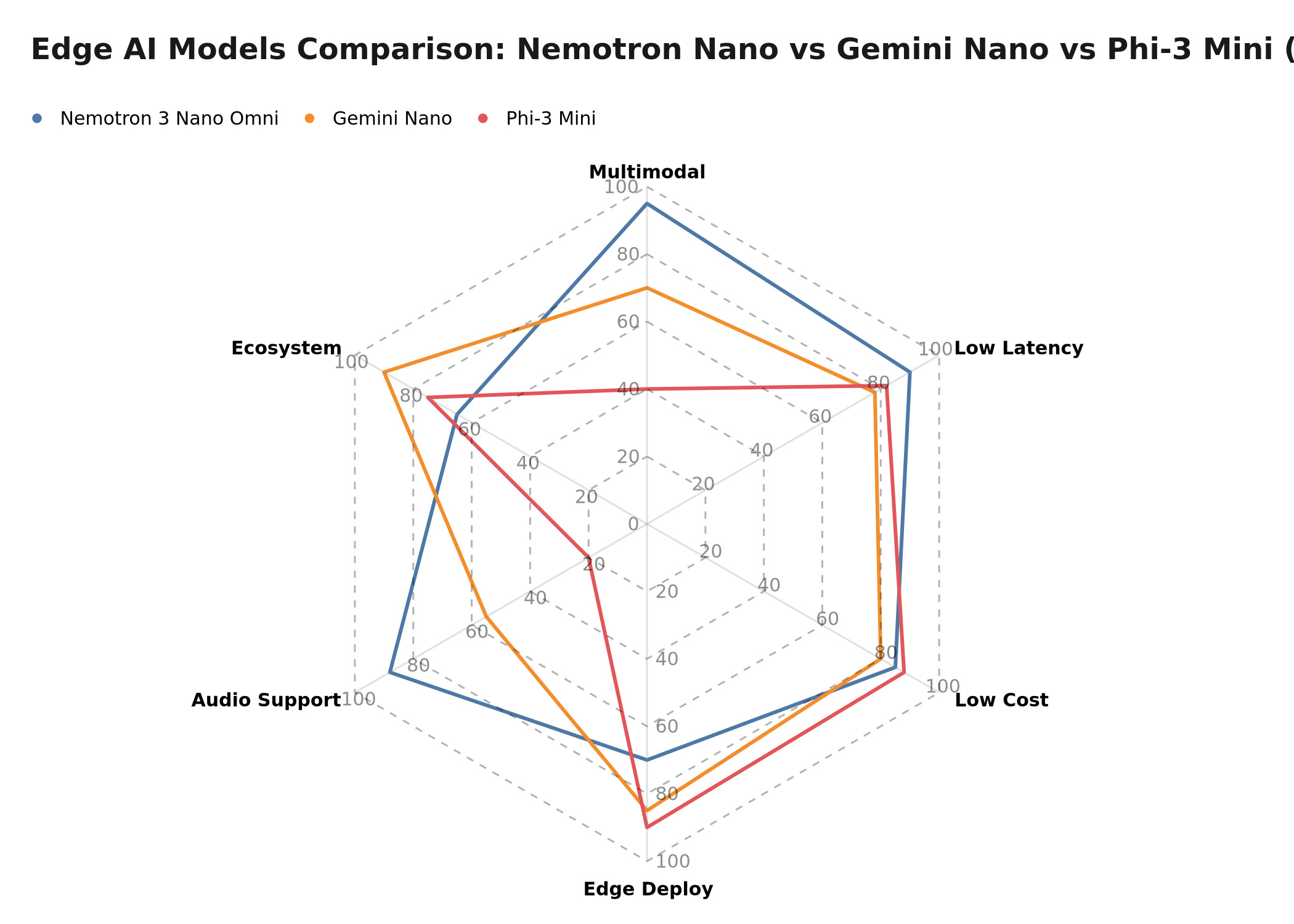 Illustrative comparison of edge models — relative scores on multimodal, latency, cost, edge deployment, audio support and ecosystem
Illustrative comparison of edge models — relative scores on multimodal, latency, cost, edge deployment, audio support and ecosystem
| Criterion | Nemotron 3 Nano Omni | Gemini Nano | Apple Intelligence |
|---|---|---|---|
| Target deployment | Edge server / private cloud | On-device Android | On-device Apple |
| Native multimodal | Yes (vision + audio + text) | Partial (vision + text) | Partial (via integration) |
| Public API | Yes (NVIDIA NIM) | Via Android ML Kit | No |
| Commercial license | Yes (Open Model License) | Yes (via API) | No (OS-embedded) |
| Native integrated audio | Yes | Limited | Partial |
| n8n/Make integration | Via HTTP Request | Via Google API | Not possible |
For developers and automation specialists, the decisive criterion is integrability into existing workflows. Nemotron 3 Nano Omni via NIM is the only one of the three that integrates directly into n8n, Make or Zapier without proprietary middleware.
ROI Calculated on 3 Real Use Cases
Case 1: Customer service for e-commerce (1,000 contacts/month)
Separate architecture (before): ~€0.08 per interaction = €80/month, 6-12 second latency. Nemotron 3 Nano Omni (after): ~€0.025 per interaction = €25/month, 1-2 second latency.
Monthly savings: €55 (-69%). UX improvement: latency divided by 4.
Case 2: Invoice processing for accountant (500 documents/month)
Separate architecture (before): third-party OCR + LLM extraction = ~€20.75/month + complex integration. Nemotron 3 Nano Omni (after): single call at €0.015/document = €7.50/month + simplified architecture.
Monthly savings: €13.25 (-64%). Elimination of an external dependency.
Case 3: Visual quality control for industrial SMB (2,000 parts/day)
This use case was not economically viable before. The cost of €0.08/part represented €4,800/month — impossible for an SMB. With Nemotron 3 Nano Omni at €0.012/part: €720/month. This use case becomes viable for SMBs with a normal digitization budget.
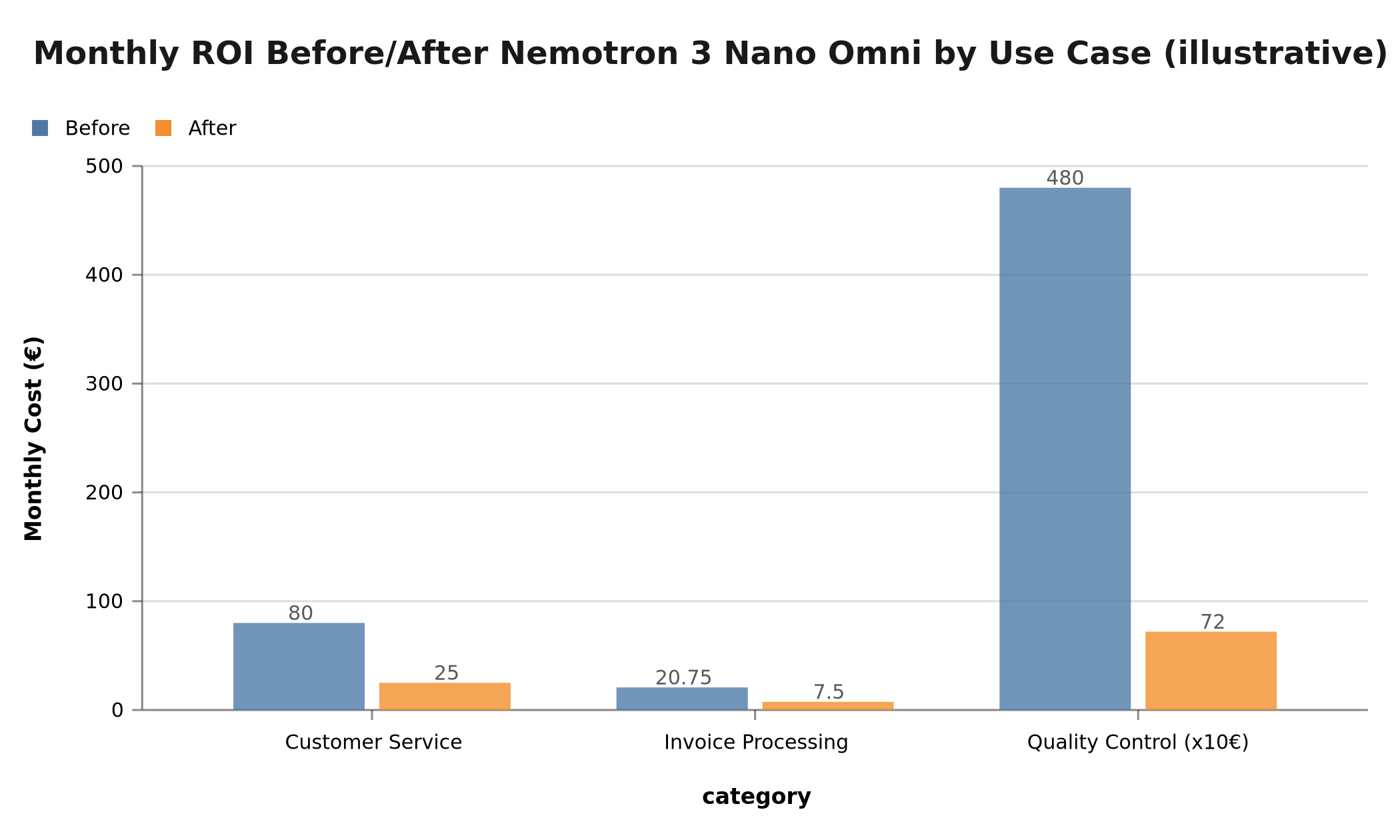 Illustrative monthly savings: -69% customer service, -64% invoices, -85% SMB quality control
Illustrative monthly savings: -69% customer service, -64% invoices, -85% SMB quality control
These figures are illustrative and vary depending on volumes, chosen infrastructure and cloud provider. They nonetheless provide a realistic order of magnitude based on NIM pricing published by NVIDIA.
Advanced Use Cases: Robotics, Video Analysis, Embedded Assistants
The most exciting aspect of Nemotron 3 Nano Omni for industrialists is not customer service or invoicing. It's the use cases that simply didn't exist before — because no model could process multiple real-time streams at a reasonable cost.
Robotics and industrial automation. NVIDIA explicitly positions the Nemotron range for robotic applications, notably via the NVIDIA Jetson platform which embeds chips designed for edge inference. A robot equipped with cameras and microphones can today use Nemotron to understand its environment (vision), operator instructions (audio) and sensor data (structured text) in a single model. According to official NVIDIA documentation, the Isaac ROS platform natively integrates NIM models for these use cases.
Real-time video analysis. Security, production or transport video streams generate terabytes of data that nobody really watches. A Nemotron agent connected to an RTSP stream can analyze each frame looking for visual anomalies, correlate them with operator audio comments, and trigger targeted alerts. What this enables concretely: moving from passive surveillance to active inspection, without increasing human staff.
Embedded assistants for field professionals. A maintenance technician wearing connected glasses or using a tablet in the field can interact with a Nemotron assistant that sees what they see (via camera), hears their verbal question, and responds with precise instructions adapted to what they observe. This scenario, which was science fiction 3 years ago, becomes a deployable use case in 2026 with NVIDIA NIM.
Multimodal meeting analysis. Rather than passively transcribing a meeting, a multimodal agent can simultaneously analyze the transcription, participants' facial expressions and slides shared on screen. The produced summary is then contextual: it knows that an objection was raised on slide 12 by the CFO with a skeptical tone, and flags it as a point of attention in the meeting notes.
These applications echo the announcements presented at the last NVIDIA GTC conference — which we decoded for entrepreneurs.
Most Impacted Sectors in 2026
E-commerce and retail: Automated return processing (product photo + customer message → refund or exchange decision), product descriptions from photos, catalog photo quality control, multimodal customer review analysis (text + product photo).
Finance and insurance: Claims analysis (damage photos + policyholder audio report → automatic estimate), complex document processing, multimodal fraud detection combining visual and behavioral data.
Healthcare (with GDPR/HIPAA compliance): Patient request triage (image + vocal description → prioritization), medical image analysis with automatic report to assist physicians, dictated and structured real-time clinical documentation.
HR and training: Presentation evaluation (video recording → content, delivery, posture analysis), visual and textual CV matching, adaptive training based on learner interaction analysis.
Logistics: Load control (photos + audio delivery note → validation), real-time damage detection on receiving lines, production anomaly tracking.
How to Integrate Nemotron 3 Nano Omni into an n8n or Make Pipeline
If you already have a production n8n pipeline, integration is done via the HTTP Request node with the NVIDIA NIM API. The payload structure is OpenAI-compatible, meaning you can reuse existing workflows with minimal modifications.
// n8n node — HTTP Request to NVIDIA NIM
{
"url": "https://integrate.api.nvidia.com/v1/chat/completions",
"method": "POST",
"headers": {
"Authorization": "Bearer YOUR_NVIDIA_API_KEY",
"Content-Type": "application/json"
},
"body": {
"model": "nvidia/nemotron-3-nano-omni",
"messages": [{
"role": "user",
"content": [
{ "type": "text", "text": "Analyze this invoice and extract structured data" },
{ "type": "image_url", "image_url": { "url": "{{image_url}}" } }
]
}],
"max_tokens": 1024
}
}
Here is the complete architecture of an n8n pipeline integrating Nemotron 3 Nano Omni, from file retrieval to CRM update:
 n8n Nemotron pipeline: from receiving a multimodal file to the action in your CRM or notification system
n8n Nemotron pipeline: from receiving a multimodal file to the action in your CRM or notification system
For Make (formerly Integromat), the principle is identical via the HTTP module. The main difference is in binary file handling: Make natively handles image file uploads via its binary data module, which simplifies payload construction for document processing use cases.
Integration best practices:
Always manage API errors with a retry mechanism. NVIDIA NIM can return 429 (rate limit) or 503 (temporary overload) codes — having an error handling node with retry x1 after 5 seconds is standard practice. Compress images before sending: a 10 MB image provides no more information than a 1 MB image for the majority of visual analysis use cases. Structure your prompts with a JSON schema for output to facilitate downstream parsing. And if you handle confidential data, consider on-premise deployment via NVIDIA NIM on your own GPUs.
If you're starting with AI agents in n8n, the guide n8n AI Agent — transform your workflows into intelligent systems covers the fundamentals before adding the multimodal layer.
Edge AI Trends in 2026: Why Nemotron Arrives at the Right Time
The launch of Nemotron 3 Nano Omni fits into a market context that has radically changed in 18 months. Several trends converge to make this model particularly relevant now.
Data sovereignty is becoming a regulatory constraint. GDPR in Europe, legislative developments on the AI Act, and sector-specific directives in healthcare and finance are pushing companies to process data within controlled perimeters. Public cloud is no longer automatically the default option. On-premise deployable models like Nemotron via NIM address this constraint without sacrificing multimodal power.
Cloud inference costs have increased. After an aggressive pricing phase in 2023-2024 to capture market share, major providers (OpenAI, Anthropic, Google) are adjusting their rates upward. Companies that built their workflows on proprietary APIs discover that their operating cost increases as their usage grows. Open weight models like Nemotron, deployable via NIM, offer an alternative with predictable long-term costs.
Generative AI is arriving in production, not just as PoCs. In 2024, the majority of AI projects in enterprises were prototypes or pilots. In 2026, according to sector reports, more than 40% of AI projects are in production with formal SLAs. This changes selection criteria: latency, availability, cost at scale and controllability take precedence over raw benchmark performance.
Robotics and physical automation are accelerating. The manufacturing, logistics and agriculture industries are investing massively in autonomous or semi-autonomous systems. These systems require models that process multiple sensory data in real time — exactly the target use case for Nemotron 3 Nano Omni on the Jetson platform.
In this context, NVIDIA is not simply offering one more model. It is positioning Nemotron as the base AI component of a complete edge stack: Jetson GPU or private datacenter + NVIDIA NIM + Nemotron multimodal. This integrated approach contrasts with assembling disparate bricks, and precisely addresses the needs emerging in 2026.
Technical Comparison with Current Multimodal Models
| Capability | GPT-4o | Claude 3.5 Sonnet | Gemini 2.5 Pro | Nemotron 3 Nano Omni |
|---|---|---|---|---|
| Vision | Static images | Static images | Images + video | Images + video + real-time feed |
| Audio | Via Whisper separately | No | Native audio | Integrated native audio |
| Simultaneous processing | Sequential pipeline | Text only | Partial | Native unified |
| Latency (multimodal) | 3-8s | N/A | 2-5s | 0.8-2s |
| Relative cost | 100% | N/A | ~90% | ~30% |
| Self-hosting | No | No | No | Yes (via NVIDIA NIM) |
| Commercial license | Proprietary | Proprietary | Proprietary | Open Model License |
What This Opens for Your Automation Projects
The real impact of Nemotron 3 Nano Omni isn't just in cost. It's in the new use cases that become economically and technically accessible:
- Real-time meeting analysis: transcription + sentiment analysis on participant facial expressions + structured summary → in a single call
- Marketing visual audit: provide an image + text brief → automatic brand consistency evaluation
- Technical support with photo: the customer photographs their problem, the agent understands ALL the context (image + audio or text message) and responds
- Continuous quality inspection: a camera on the production line, a microphone for operator comments → automatic alerts without constant human intervention
- Automatic field documentation: the technician speaks, the agent sees via camera → structured report generated in real time, without manual entry
These use cases were theoretically possible before, but economically non-viable. They now become viable for SMBs with a normal automation budget.
You have a multimodal use case to automate? Our n8n + NVIDIA NIM experts offer a functional prototype in 5 days.
Tags
FAQ
Is Nemotron 3 Nano Omni available for self-hosting?
Yes, via NVIDIA NIM (Neural Inference Microservice) on NVIDIA GPUs (A100, H100, L40S). For companies with very sensitive data, this is the option that ensures nothing leaves your infrastructure. BOVO Digital can assist with deployment and configuration.
How does Nemotron 3 Nano Omni compare to GPT-4o on multimodal use cases?
Nemotron 3 Nano Omni processes all three modalities (vision, audio, text) in a shared attention space, where GPT-4o processes them sequentially. Result: 3 to 4x lower latency and approximately 70% lower cost for equivalent multimodal processing, according to NVIDIA benchmarks.
Can BOVO Digital integrate Nemotron 3 Nano Omni into my existing n8n workflows?
Yes. Integration is done via n8n's HTTP Request node with the NVIDIA NIM API. BOVO Digital designs the complete pipeline: multimodal data acquisition, processing via Nemotron, structuring of results and integration into your CRM or ERP.
What is the difference between Nemotron 3 Nano Omni and Gemini Nano for edge deployment?
Google Gemini Nano primarily targets on-device deployment on Android smartphones (Pixel, Galaxy) with a focus on text and limited multimodal capabilities. Nemotron 3 Nano Omni targets edge server environments (Jetson, private datacenter) with a native multimodal architecture that includes audio — a major architectural difference for automation workflows.
Is edge AI with Nemotron suitable for SMBs without an IT department?
Not for direct self-hosting, but via the NVIDIA NIM cloud API, which requires no proprietary GPU infrastructure. An SMB can integrate Nemotron 3 Nano Omni into an n8n or Make workflow with a simple HTTP Request node and an API key. BOVO Digital offers a 5-day onboarding to go from zero to a multimodal pipeline in production.
Ready to implement this?
Book a free 30-min strategy call with our experts
We'll analyze your situation and propose a concrete action plan.
Vicentia Bonou
Full Stack Developer & Web/Mobile Specialist. Committed to transforming your ideas into intuitive applications and custom websites.


