
Preventing AI Hallucinations: The Complete Guide for Businesses (2026)
ChatGPT invented a law for you. Claude cited a source that doesn't exist. How do you stop your AI from lying to you? This guide explains proven techniques to eliminate hallucinations in your business workflows.

Updated

Preventing AI Hallucinations: The Complete Guide for Businesses (2026)
An AI that is confidently wrong is more dangerous than an AI that says "I don't know".
Your AI just handed you a report citing three studies... that don't exist. Your customer chatbot just promised a feature your product doesn't have. Your AI agent created an invoice with incorrect data. Preventing AI hallucinations is therefore not a nice-to-have for engineers: it is a precondition for deploying artificial intelligence in production without exposing your business to costly errors.
Welcome to the world of AI hallucinations.
This isn't a bug. It's a fundamental characteristic of language models — and understanding it is the first step to controlling it. In this guide, you'll learn exactly what a hallucination is, why it happens, and above all the concrete techniques to reduce it to a manageable level: RAG, constrained prompts, cross-validation, human oversight, an anti-hallucination pipeline, risk classification and governance. The goal isn't to promise zero defects — that's impossible — but to turn an unpredictable black box into a reliable, auditable system.
What is an AI Hallucination?
An AI hallucination is when a language model generates convincing but factually incorrect information. The model doesn't "know" it's lying — it generates the statistically most likely continuation of a word sequence, whether true or not. That's exactly where the trap lies: the text is grammatically perfect, the tone is confident, the structure is credible. Nothing in the form signals the error. A human who makes things up usually stumbles; an LLM does it with the same poise as a correct answer.
It helps to distinguish two families. Intrinsic hallucinations directly contradict information provided in the prompt (the model distorts a document it was actually given). Extrinsic hallucinations add facts that can't be verified anywhere in the provided context. The former are caught by comparing the output to the source; the latter require external verification.
Most common hallucination types:
- Factual hallucinations: Inventing data, dates, figures, statistics.
- Source hallucinations: Citing non-existent articles, books, case law, or studies — sometimes with a fake DOI or a fabricated case reference.
- Code hallucinations: Generating functions, parameters or libraries that don't exist (a phenomenon so common it spawned an attack called "slopsquatting", where malicious packages are named after hallucinated dependencies).
- Contextual hallucinations: Misinterpreting an instruction and inventing context or assumptions that were never stated.
Why is this particularly dangerous in business? Because a model's output is often consumed without review, then injected into another system: a CRM, a customer email, a quote, a database. An isolated hallucination then becomes wrong data that propagates. That's the difference between an assistant that errs verbally — quickly forgotten — and an autonomous agent that writes false information into your systems of record. We detail this mechanism in our article on how an AI invents a non-existent law, a textbook case in the legal sector.
Why Do LLMs Hallucinate?
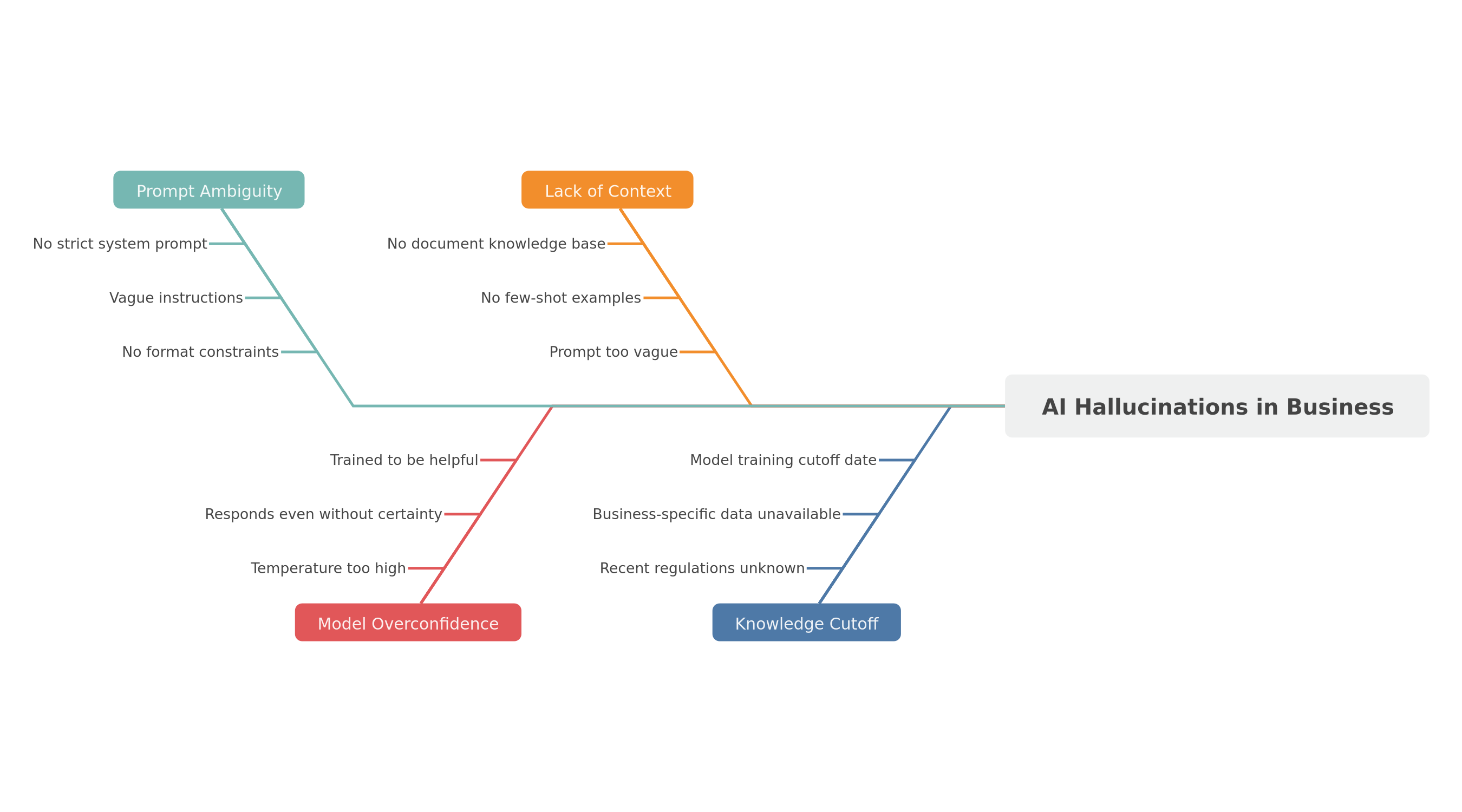 Fishbone diagram: knowledge cutoff, lack of context, model overconfidence and prompt ambiguity
Fishbone diagram: knowledge cutoff, lack of context, model overconfidence and prompt ambiguity
Language models (GPT, Claude, Gemini, Mistral) are trained to predict the most likely next token. They have no access to an external "truth" — they rely on the statistical regularities of their training corpus. Understanding this mechanism avoids two symmetrical mistakes: believing the model "lies on purpose", or conversely believing it actually "knows" the facts. Neither is true: it completes a probability.
The 4 main causes:
1. Knowledge cutoff
Every model has a training cutoff date. Beyond it, it hasn't seen recent events, prices, product versions or regulations. Faced with a question past that frontier, it has no way to "know that it doesn't know": it extrapolates from old patterns and produces a plausible but potentially outdated answer. That's why a model can confidently describe a software feature that has changed since its cutoff.
Solution: RAG (Retrieval-Augmented Generation). Connect your LLM to an up-to-date knowledge base. The AI searches your source of truth first, then answers based on retrieved context instead of its parametric memory.
2. Lack of specific context
When the model doesn't have the exact information about your company — your prices, procedures, product references — it "fills the gaps" with whatever looks most like a plausible answer. The void is never left empty: it gets filled with the statistical average of the corpus. And the average of the Internet is not the truth of your organization.
Solution: few-shot prompting + abstention instructions. Provide concrete examples in your prompt and explicitly allow abstention: "If the information is not in the provided context, answer: I don't have this information." This permission to say "I don't know" is one of the most underrated guardrails.
3. Model overconfidence
LLMs are optimized to be helpful and fluent. Reinforcement-based alignment pushes them to always provide a satisfying answer rather than express doubt. As a result, a model will often prefer a wrong but confident answer over an "I'm not sure". This overconfidence is a side effect of training, not an intention.
Solution: Chain-of-Thought + explicit calibration. Force step-by-step reasoning and ask for a self-reported confidence level. A model prompted to make its uncertainty explicit is easier to filter downstream.
4. Prompt ambiguity
A vague prompt produces an invented answer: faced with multiple possible interpretations, the model picks one and treats it as a given. An implicit question, an undefined acronym, a contradictory instruction — all open doors to improvisation.
Solution: structured prompts with constraints. Use explicit formats (JSON, checklists, templates), define terms, and specify what the model should do when in doubt. The more rigid the structure, the less the model improvises. This principle echoes the idea developed in your AI is "dumb" and that's normal: a model only performs well if it is properly fed with context.
How to Prevent AI Hallucinations: The 7 Proven Techniques
No technique is sufficient on its own. Reliability comes from layering guardrails: each layer catches what the previous one let through. The chart below illustrates this cumulative logic — the values are indicative, meant to show the trend, not as a universal benchmark: the real gain depends on your use case and the quality of your data.
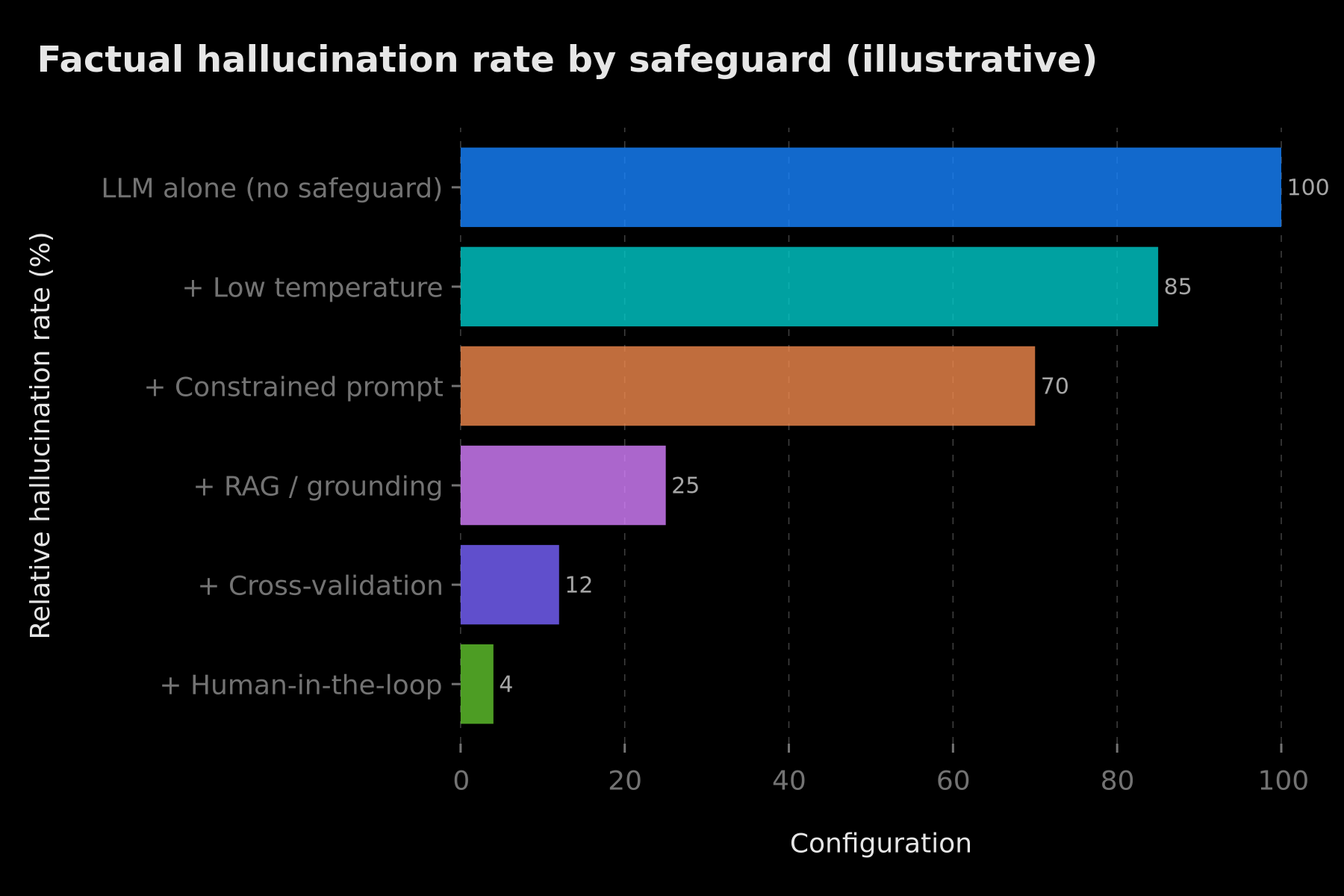 The more guardrails you stack (low temperature, constrained prompt, RAG, cross-validation, human-in-the-loop), the lower the relative hallucination rate — illustrative order of magnitude
The more guardrails you stack (low temperature, constrained prompt, RAG, cross-validation, human-in-the-loop), the lower the relative hallucination rate — illustrative order of magnitude
Technique 1: RAG (Retrieval-Augmented Generation)
This is the most effective technique against factual hallucinations. The principle: before answering, the AI consults your knowledge base and grounds its answer in the retrieved excerpts.
Implementation with n8n:
- Store your documents in a vector database (Supabase, Pinecone, Qdrant).
- For each question, vectorize the query.
- Retrieve the 3 to 5 most relevant chunks.
- Inject these chunks into the LLM context, with the instruction to answer only from them.
Result: a significant reduction in factual hallucinations, often in the range of 70 to 90% depending on the case, provided the base is clean, up to date and well chunked. Caution: RAG doesn't remove the risk, it shifts it. If your base contains contradictory or outdated information, the AI will faithfully cite... a bad source. The quality of RAG is, first and foremost, the quality of the indexed data.
Technique 2: Grounding with cited sources
Explicitly ask the LLM to cite its sources and distinguish what it knows with certainty from what it estimates. Forcing a citation makes the model "anchor" each statement to a real excerpt, and makes verification trivial for a human or a downstream system.
Prompt template:
Answer the following question using ONLY the provided context.
For each factual statement:
- Cite the exact excerpt that supports it.
- If no excerpt supports it, assert nothing and flag it.
- Distinguish [CERTAIN] (supported by context) from [TO VERIFY].
Technique 3: Automatic cross-validation
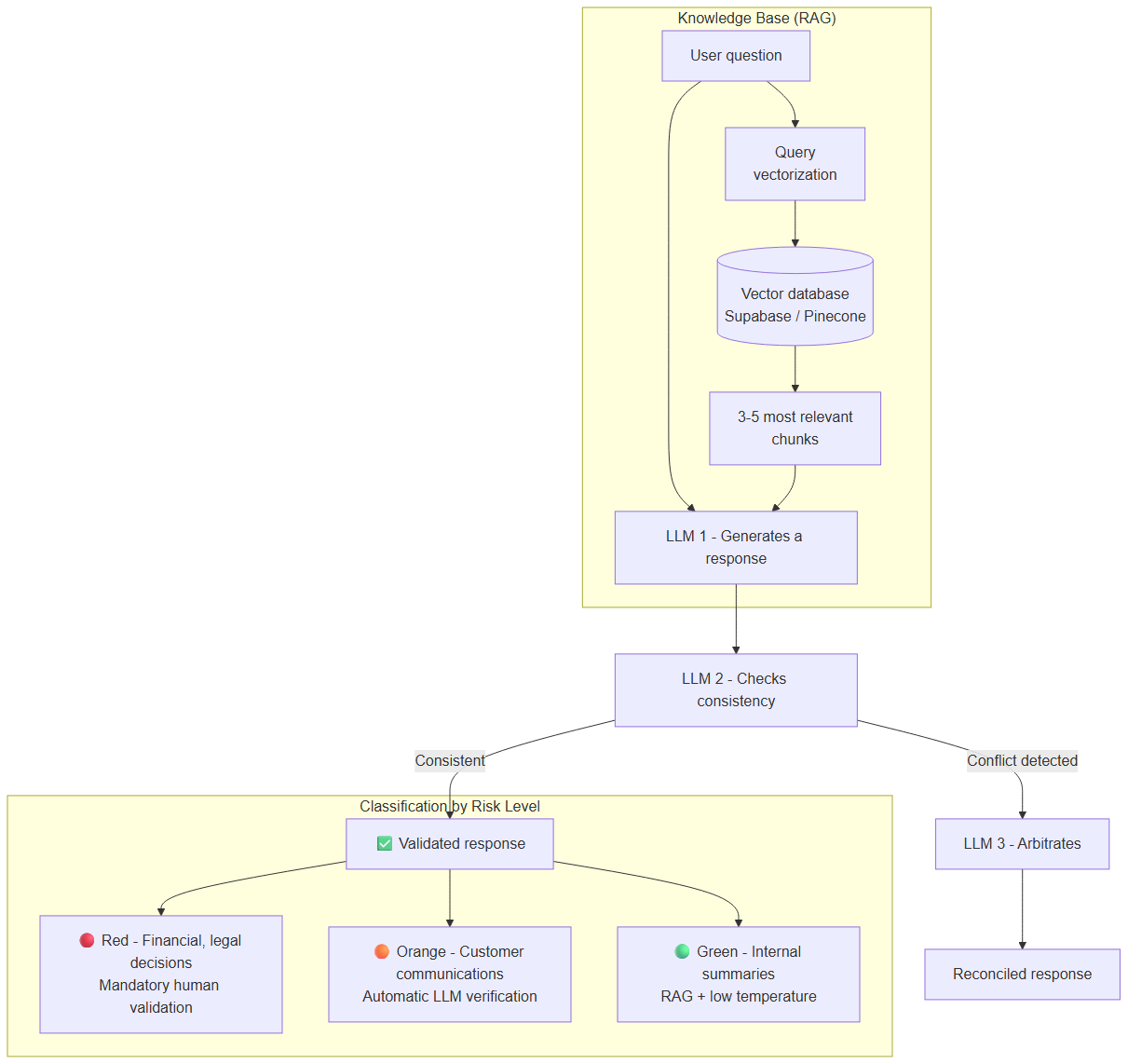 Complete anti-hallucination pipeline: RAG injects context, LLM 2 checks consistency, LLM 3 arbitrates conflicts, then Red/Orange/Green risk classification
Complete anti-hallucination pipeline: RAG injects context, LLM 2 checks consistency, LLM 3 arbitrates conflicts, then Red/Orange/Green risk classification
In an n8n or Make workflow, after each AI response, add a second LLM call whose sole role is to check the consistency of the first response against the context. This technique — close to the "LLM-as-a-judge" principle — catches a good share of internal contradictions without human intervention.
Architecture:
Question → LLM 1 (generates) → LLM 2 (checks) → If conflict → LLM 3 (arbitrates)
The extra cost in latency and tokens is real; you therefore reserve it for outputs that justify it. That's where risk classification, detailed below, comes in.
Technique 4: Temperature and sampling parameters
Temperature controls the model's randomness. For factual tasks, reduce it radically:
- Temperature 0.0: deterministic, ideal for data extraction and classification.
- Temperature 0.3: low variability, good for factual summaries.
- Temperature 0.7+: creative, for content generation where diversity is desired.
Important: lowering the temperature reduces variability, not the risk of being wrong. A model at temperature 0 will repeat the same hallucination perfectly stably if the information is missing. Temperature is a supporting setting, never a protection on its own.
Technique 5: Structured format constraints
Force JSON outputs with schema validation. A model constrained to produce a precise format improvises less, and any non-conforming output is automatically rejected before reaching your systems.
{
"answer": "string",
"confidence_level": "high|medium|low",
"sources_used": ["string"],
"points_to_verify": ["string"]
}
The sources_used field is valuable: if it's empty while the question was factual, that's an actionable alert signal for your workflow.
Technique 6: Strict system context
The system prompt sets the rules of the game. Explicitly instruct the model to refuse to invent:
You are a factual assistant. Absolute rules:
- Never invent data, statistics, or citations.
- If the information is not in the context, say "I don't have this information".
- Always flag when a topic exceeds your knowledge cutoff.
- Prefer "I'm not sure" over an invented answer.
Technique 7: Human-in-the-loop for critical decisions
For high-stakes outputs (contracts, quotes, medical, legal, financial data), always integrate human validation in the workflow. In n8n, a "Wait" node or an email/Slack approval lets you suspend the agent until validation. This technique deserves its own section: it's the subject of the next part.
Supervising AI: Human-in-the-Loop
Automating does not mean delegating blindly. Human oversight — human-in-the-loop — means placing a person at the right point in the chain, where the cost of an error exceeds the cost of a review. The point is not to review everything (which would cancel the automation benefit), but to review what matters.
Three supervision models coexist. Human-in-the-loop inserts a blocking validation before the action: nothing goes out without human approval. Human-on-the-loop lets the AI act but under surveillance, with the ability to interrupt and correct afterward. Human-out-of-the-loop is full autonomy, reserved for very low-stakes, reversible tasks. The choice depends on the stakes and the reversibility of the action.
The most common mistake isn't the total absence of oversight, but theatrical oversight: a human mechanically validating dozens of outputs without really reading them, out of excessive trust in the machine. That's "automation bias". The countermeasure: only require human validation on genuinely risky cases (classified red), present the human with the doubt elements surfaced by automatic validation, and trace every decision. We covered the scale of this risk in the article 99% of businesses make this AI oversight mistake.
Concretely, good oversight rests on three ingredients: a checkpoint placed before any irreversible action, a decision context provided to the human (the AI's answer, its sources, its confidence level, detected conflicts), and a feedback loop where human corrections enrich the knowledge base to reduce future errors.
Building an End-to-End Anti-Hallucination Pipeline
The seven techniques reach their full value when assembled into a chain. A robust anti-hallucination pipeline typically chains six stages:
- Request reception and clarification — detect ambiguities, ask for clarification if needed rather than guessing.
- Retrieval (RAG) — query the vector database and inject the relevant excerpts into the context.
- Constrained generation — produce an answer in a structured format, with citations and a confidence level, at an appropriate temperature.
- Automatic validation — a second model checks consistency with the context; a schema validates the format.
- Risk classification — route the output to red / orange / green based on stakes and confidence level.
- Action or escalation — automatic execution for green, targeted verification for orange, blocking human validation for red; and systematic logging.
This kind of orchestration is exactly what platforms like n8n enable, where each stage becomes an explicit, auditable node. If you're new to this, our guide to turning your workflows into intelligent systems with n8n shows how to concretely wire an AI agent with a vector base and guardrails. The advantage of an explicit pipeline is twofold: it makes behavior reproducible, and it turns every incident into a localizable improvement point.
A subtle but decisive design choice is where to put the friction. Adding validation everywhere kills throughput; adding it nowhere kills trust. The pipeline lets you tune that trade-off stage by stage: the clarification step removes ambiguity at the cheapest point (before any compute is spent), retrieval and constrained generation handle the bulk of correctness automatically, and human escalation is triggered only when both the stakes and the uncertainty are high. In practice, most outputs flow straight through; only a thin slice ever reaches a human. That asymmetry is what makes automation economically viable: you pay the cost of careful review only on the fraction of cases where it actually changes the outcome, while the rest benefit from the same guardrails at near-zero marginal cost.
It's also worth designing the pipeline to fail safe. When a stage is uncertain — retrieval returns nothing relevant, the validator flags a conflict, the schema doesn't parse — the default should be to escalate or abstain, not to ship. A system that errs toward "I don't know" is far cheaper to operate than one that errs toward confident output, because every confident error has to be discovered, traced and corrected after the damage is done.
Measuring Risk: Red / Orange / Green Classification
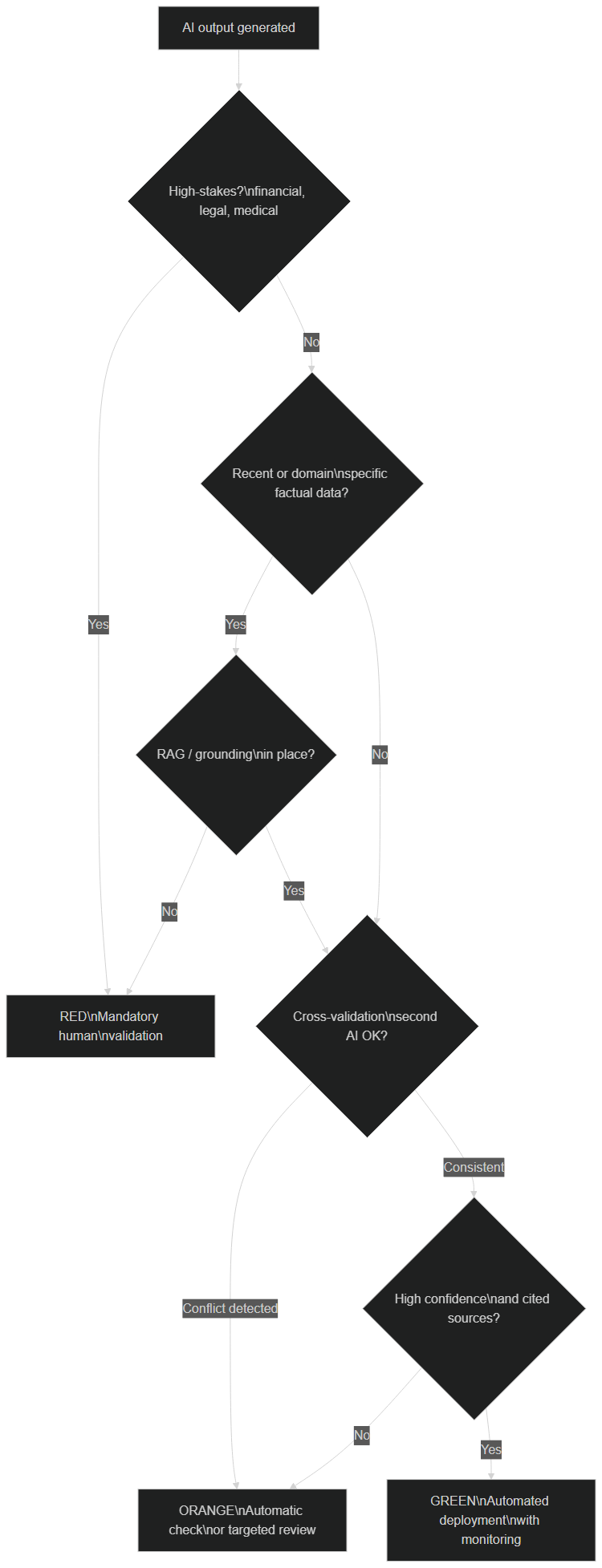 Decision tree: depending on the stakes, the presence of RAG, cross-validation and confidence, the output is classified Red (human validation), Orange (verification) or Green (automated deployment with monitoring)
Decision tree: depending on the stakes, the presence of RAG, cross-validation and confidence, the output is classified Red (human validation), Orange (verification) or Green (automated deployment with monitoring)
You don't treat an internal meeting note like a customer quote. The key to a reliable AI in production is to graduate guardrails according to the stakes. The three-level classification provides a simple, actionable grid:
- Red — financial, legal, medical decisions, or any irreversible action. Mandatory human validation before execution. The cost of an error far exceeds the cost of a review.
- Orange — customer communications, reports, externally distributed content. Automatic verification (cross-validation by a second LLM) and sampled human review. The error is annoying but recoverable.
- Green — internal summaries, drafts, suggestions, low-stakes classifications. RAG + low temperature + monitoring are enough. Full automation is acceptable.
The decision tree above formalizes this routing: it combines the stakes, the presence of RAG, the cross-validation result and the confidence level to decide whether an output can be deployed automatically or must escalate to a human. This logic avoids two symmetrical pitfalls: validating everything by hand (automation becomes pointless) or letting everything through (risk becomes uncontrolled).
For this classification to stay more than theoretical, you need to measure it. Build a test set representative of your real cases, with reference answers. Run your assistant on it at regular intervals, compare its outputs to the expected facts, and track a factual error rate over time. Define a target threshold per category (for example stricter on red) and trigger an alert as soon as it's exceeded. Public approaches such as truthfulness evaluation sets (e.g. TruthfulQA) or context-faithfulness leaderboards (like Vectara's HHEM) give a methodological reference point, but your most useful metric remains the one computed on your data.
Governance and Compliance
Beyond the technique, preventing AI hallucinations has become a governance topic. The European AI Act, which entered into force in 2024 with a phased application through 2026-2027, imposes growing obligations on high-risk systems: risk management, data quality, traceability, transparency and human oversight. An AI that produces opaque, unverifiable decisions is no longer just an operational risk — it's a compliance risk.
A few concrete governance principles, without drifting into legalese:
- Traceability — log inputs, outputs, sources used and human decisions, so you can reconstruct why an answer was produced.
- Transparency — inform the end user they're interacting with an AI, and flag unverified answers.
- Accountability — clearly designate who is responsible for each AI system's outputs; the AI assists, it doesn't bear responsibility.
- Data protection — control what is sent to the models (personal data, secrets), especially with third-party APIs.
This dimension isn't a brake: a governed AI is an AI you can invest in sustainably, because it's defensible before a client, an auditor or a regulator.
Business Cases: Three Typical Situations
Customer support. A chatbot plugged into product documentation via RAG answers common questions. As long as it cites the doc section it used and stays in green, it runs autonomously. As soon as a question touches a contractual commitment (refund, SLA), it's classified red and escalated to a human agent. The AI absorbs the volume, the human keeps control of the commitment.
Document processing. An agent extracts information from invoices or contracts to inject it into an ERP. Here, structured output (schema-validated JSON) and cross-validation are essential, because the data goes straight into a system of record. Amounts above a threshold go to human validation.
Internal monitoring and synthesis. An assistant summarizes reports for teams. Low stakes, reversible content: RAG + low temperature + monitoring are enough. This is typically green, where full automation delivers a net gain without exposing the business.
The common thread across these three cases: it's not the model that makes reliability, it's the architecture around it. The same LLM can be dangerous in the first case and perfectly safe in the third, depending on the guardrails surrounding it.
Limits: What No Technique Solves
Let's be honest about the boundaries. No method guarantees zero hallucinations. LLMs remain probabilistic; you reduce the risk, you don't eliminate it. Three limits are worth keeping in mind.
First, RAG is only as good as its base: false, outdated or contradictory data will produce a wrong but well-sourced answer — a false sense of security. Second, cross-validation by a second LLM shares biases with the first: two models can hallucinate in unison on a poorly covered topic. Finally, human oversight is fallible: fatigue, automation bias, overload. Stacking guardrails reduces the probability of error, but none is perfect.
The right posture is therefore not the search for an absolute guarantee, but the management of residual risk: measure it, keep it under an acceptable threshold for each use, and monitor it over time. That's exactly the difference between an impressive demo gadget and a production system a business can rely on.
Conclusion: Reliable AI is an Architecture, Not a Parameter
Preventing AI hallucinations is not about choosing the "right" model or lowering temperature to zero. It's about system architecture, where each layer plays its role:
- RAG to anchor answers in real, up-to-date data.
- Structured prompts and citations to constrain outputs and make verification easy.
- Cross-validation to catch inconsistencies without human intervention.
- Human oversight targeted at critical decisions, never theatrical.
- Risk classification to graduate the control effort.
- Governance and measurement to make the whole thing auditable and durable.
At BOVO Digital, every AI workflow we build integrates these safeguards from day one — not as an afterthought. That's what separates an impressive AI from a reliable one.
Tags
FAQ
What is an AI hallucination and why is it dangerous for businesses?
An AI hallucination is when a model generates convincing but false information (invented data, non-existent sources, fictional statistics). For businesses, this can cause decisions based on wrong data, incorrect customer communications, or legal issues.
What is the most effective technique to prevent AI hallucinations?
RAG (Retrieval-Augmented Generation) is the most effective technique. It connects your LLM to a real-time updated database. The AI first consults your source of truth before answering, strongly reducing factual hallucinations (often in the range of 70 to 90% depending on the case and the quality of the knowledge base).
How do I configure n8n to minimize AI hallucinations in my workflows?
Use the combination RAG + low temperature (0.1-0.3) + structured JSON outputs + cross-validation by a second LLM. In n8n, connect a vector database node (Supabase/Pinecone) before your AI agent, and add a validation node for critical decisions.
Does reducing temperature to 0 completely eliminate hallucinations?
No. Temperature 0 makes the model deterministic but doesn't prevent hallucinations if the information isn't in its training corpus. RAG is necessary for recent or domain-specific factual data.
Can you guarantee zero hallucinations with an AI?
No, no technique guarantees 100% zero hallucinations. LLMs remain probabilistic by nature. The realistic goal is to reduce the error rate to an acceptable level for each use case, then keep it under control with automatic validation, human oversight on critical decisions and continuous monitoring.
How do you measure an AI assistant's hallucination rate?
Build a representative test set with reference answers, run your assistant on it, then compare its responses to the expected facts (manually or via an evaluator LLM). Track a factual error rate over time and trigger an alert as soon as it exceeds your target threshold.
Ready to implement this?
Book a free 30-min strategy call with our experts
We'll analyze your situation and propose a concrete action plan.
William Aklamavo
Web development and automation expert, passionate about technological innovation and digital entrepreneurship.


