
Gemma 4 + n8n Advanced Use Cases: 5 Local AI Agent Workflows (2026)
You've set up Gemma 4 locally with Ollama. Now what? This guide covers 5 production-ready n8n agent workflows using Gemma 4 — lead qualifier, document analyzer, support bot, data extractor, and content writer — all running 100% locally.

Beyond the Basic Setup: What Gemma 4 + n8n Can Actually Do
Our Gemma 4 + Ollama + n8n tutorial showed you how to connect the pieces. But the real question is: what can you build with it?
Gemma 4's Apache 2.0 license and frontier-level performance make it the first truly viable open-source LLM for business production. The 27B model benchmarks above GPT-4o mini on reasoning tasks while running on a standard developer machine (16GB RAM for the 12B, 32GB for the 27B).
This article gives you 5 concrete, battle-tested n8n workflows we've built for clients — all running on Gemma 4 locally.
Why Gemma 4 Specifically (Not Llama, Mistral, or Qwen)?
In Q2 2026, Gemma 4 outperforms alternatives on the criteria that matter for business agents:
- Context window: 128K tokens (vs 32K for Mistral 7B) — handles long documents and conversation history
- Multilingual: strong French + English performance out of the box
- Tool calling: reliable function calling for n8n tool integrations
- License: Apache 2.0 — commercial use, no royalties, no restrictions
For local n8n agents specifically, the instruction-following consistency of Gemma 4 IT (Instruction Tuned) is noticeably better than Llama 3.1 8B for structured output tasks.
Workflow 1 — Private Lead Qualifier
Problem: Your form collects lead data. You need to score each lead (SMALL/MEDIUM/LARGE) and route them — but you can't send client names and company data to OpenAI's API.
Architecture:
- Trigger: Typeform Webhook
- LLM: Gemma 4 27B (Ollama)
- Tools: HTTP Request to Pappers API (French company registry), Notion API (CRM)
- Output: Notion entry with score + personalized first email draft
System Prompt key elements:
You are a B2B lead qualifier for a digital agency.
Score each lead as SMALL/MEDIUM/LARGE based on:
- Company size (employees, revenue if available)
- Industry fit (tech, e-commerce, services = good)
- Budget signals (mention of "urgent", "budget confirmed")
Output a JSON: {score, reason, email_subject, email_body}
Result: 2.5h of manual qualification per day automated. 100% of data stays on-premises.
Workflow 2 — Document Analyzer (Contracts, RFPs, Invoices)
Problem: Your team receives 50+ documents per week. Reading and extracting key info takes hours.
Architecture:
- Trigger: Email Webhook (Gmail API) or Webhook from file upload
- Pre-processing: Extract PDF text with n8n's HTTP Request to a local parser (Apache Tika or pdf-parse)
- LLM: Gemma 4 27B with the full document in context (128K window)
- Output: Structured JSON → Google Sheets row or Notion database entry
Use cases:
- Extract payment terms, amounts, parties from contracts
- Flag risk clauses ("exclusivity", "auto-renewal", "penalty")
- Summarize RFPs in 5 bullet points for quick assessment
Key tip: Gemma 4's 128K context handles documents up to ~100 pages without chunking. For longer documents, split by section and aggregate.
Workflow 3 — Offline Customer Support Bot
Problem: You need a 24/7 support bot, but customer conversations contain sensitive data (account numbers, addresses, purchase history) that can't go to OpenAI.
Architecture:
- Trigger: Chat Trigger (embed on your website via n8n's public URL)
- LLM: Gemma 4 12B (faster response, sufficient for FAQ-type tasks)
- Memory: Postgres Chat Memory (persistent conversation history)
- Tools: HTTP Request to your internal knowledge base or FAQ endpoint
- Fallback: If confidence low → escalate to human via Slack notification
Performance tip: Gemma 4 12B runs at ~15 tokens/second on a standard VPS with GPU (RTX 3060). Response time: 2-4 seconds for typical support messages — acceptable for async support, borderline for real-time chat.
Workflow 4 — Local Data Extractor (Web Scraping + Structuring)
Problem: You scrape competitor prices, job listings, or market data. You need to clean and structure thousands of rows — too expensive via OpenAI API at scale.
Architecture:
- Trigger: Schedule (every 6 hours)
- Data collection: n8n HTTP Request nodes scraping target URLs
- LLM: Gemma 4 2B (tiny model, extremely fast for simple extraction tasks)
- Output: Structured JSON → PostgreSQL or Airtable
Why Gemma 4 2B here? For structured extraction from semi-clean HTML, the 2B model is 95% as accurate as the 27B at 10x the speed and 0 cost. Reserve the larger models for reasoning-heavy tasks.
Example prompt:
Extract from this job listing:
- company_name
- job_title
- location
- salary_range (null if not specified)
- remote_policy (remote/hybrid/on-site)
Return only valid JSON.
Workflow 5 — Autonomous Content Writer (FR/EN)
Problem: You need to publish 3-5 blog posts per week across FR and EN. Manual writing doesn't scale.
Architecture:
- Trigger: Airtable row creation (editorial calendar)
- Step 1: Research agent — Gemma 4 27B + Brave Search tool → collects 5 top-ranking articles on the topic
- Step 2: Outline agent — generates H2 structure based on competitor gaps
- Step 3: Writer agent — produces full draft (1500-2500 words) section by section
- Step 4: SEO checker — validates title, meta description, keyword density
- Output: Notion draft ready for human review
Important: Always keep a human in the loop for final review. Gemma 4 produces solid drafts but hallucinations on specific data (statistics, dates, prices) require verification.
Performance Benchmarks: Gemma 4 Models for n8n Agents
| Model | RAM Required | Tokens/sec (GPU) | Best For |
|---|---|---|---|
| Gemma 4 2B | 4 GB | ~80 t/s | Simple extraction, classification |
| Gemma 4 12B | 16 GB | ~20 t/s | Support bots, summarization |
| Gemma 4 27B | 32 GB | ~8 t/s | Complex reasoning, document analysis |
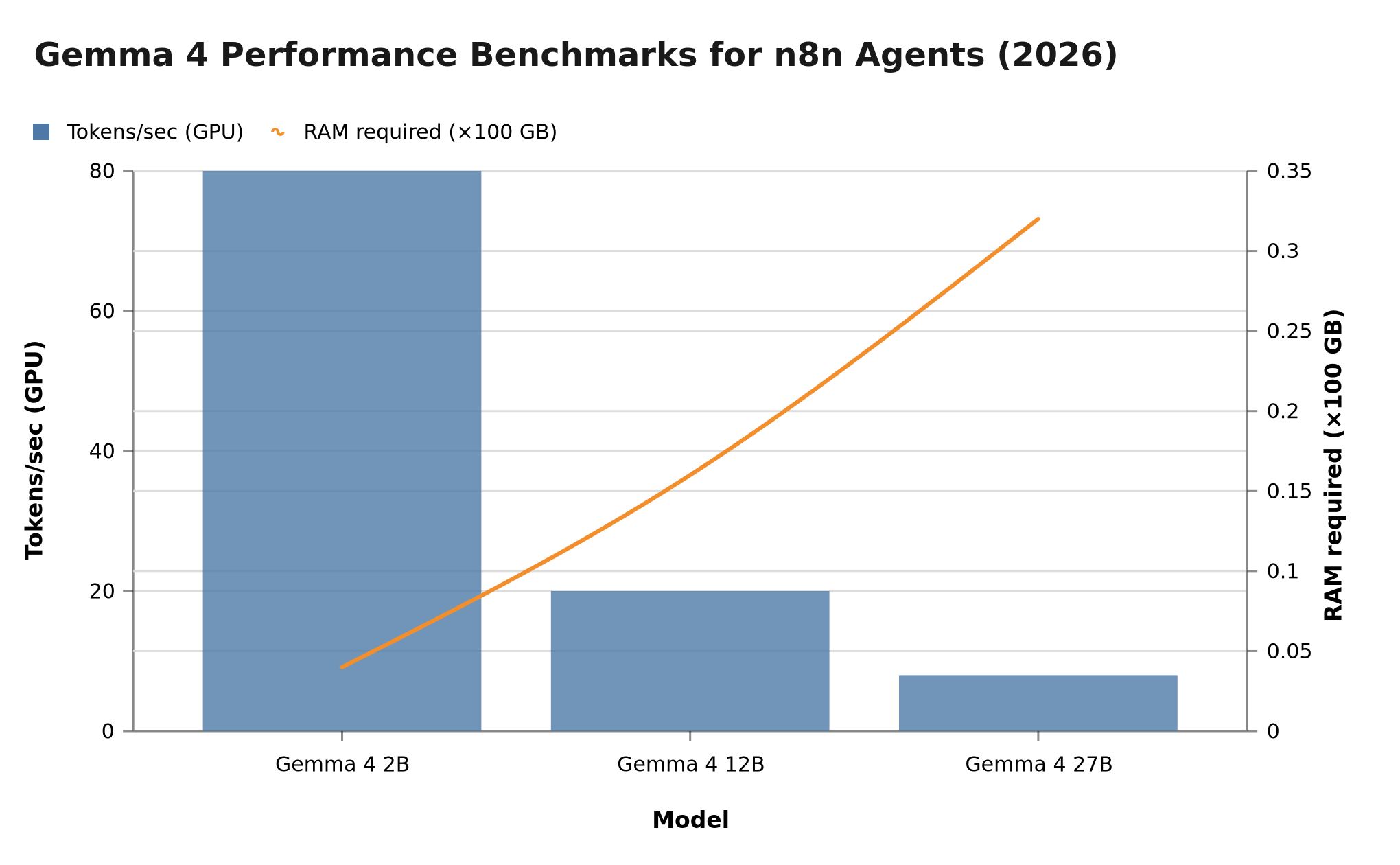 Gemma 4 model comparison: 2B at ~80 t/s (4GB RAM), 12B at ~20 t/s (16GB RAM), 27B at ~8 t/s (32GB RAM)
Gemma 4 model comparison: 2B at ~80 t/s (4GB RAM), 12B at ~20 t/s (16GB RAM), 27B at ~8 t/s (32GB RAM)
For cloud deployment without OpenAI costs, run Ollama on a Hetzner GPU server (CCX33 with RTX 4000) at ~40€/month — cost-effective for 500+ agent runs per day.
Combining Gemma 4 with Cloud LLMs
The best architecture for most production systems: local by default, cloud as fallback.
In n8n, this looks like:
- Primary path: Gemma 4 local (free, private)
- Error handler: If Ollama is unavailable OR task complexity exceeds local model → GPT-4o via OpenAI API
- Fallback alert: Slack notification to DevOps
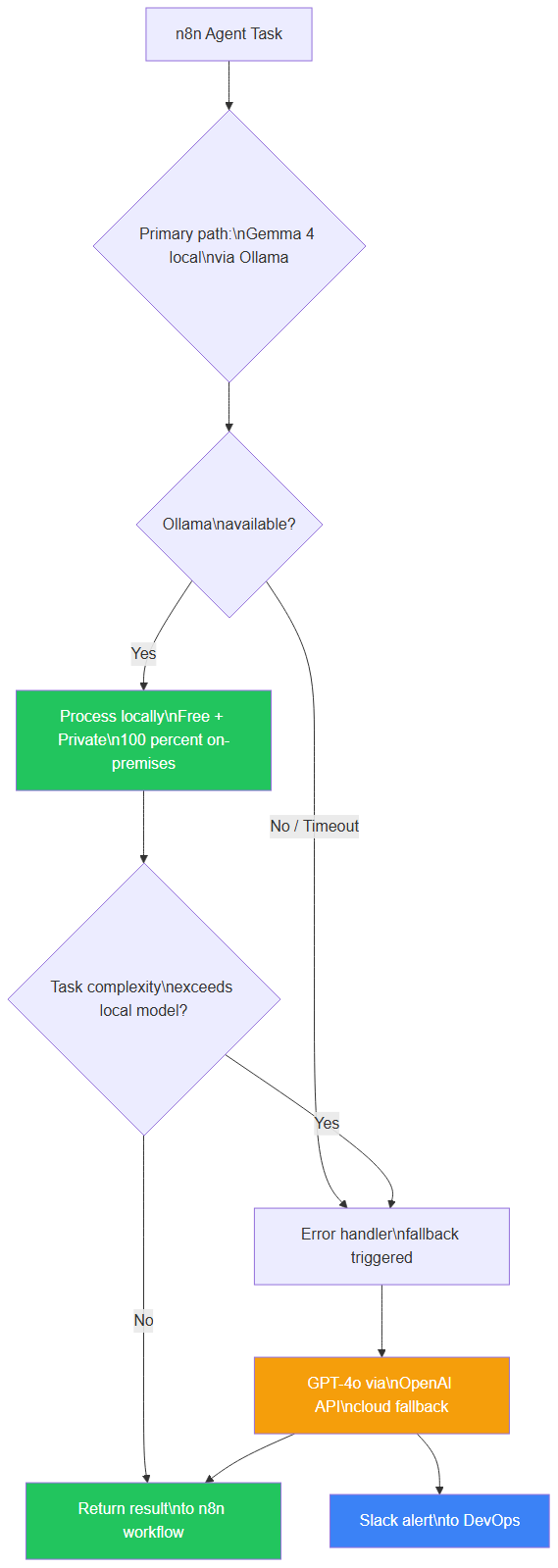 n8n agent architecture: Gemma 4 local (primary) with GPT-4o cloud fallback for unavailability or complex tasks
n8n agent architecture: Gemma 4 local (primary) with GPT-4o cloud fallback for unavailability or complex tasks
This setup gives you 90%+ cost savings while maintaining 100% uptime for your automation pipeline.
Ready to deploy one of these workflows? The BOVO Digital team builds and maintains n8n agent systems for SMEs and agencies. We can deploy your first Gemma 4 agent in 48 hours. Get a free quote.
Tags
FAQ
Which Gemma 4 model should I use for n8n agents?
It depends on the task complexity: Gemma 4 2B for simple extraction and classification (fastest, 4GB RAM), Gemma 4 12B for support bots and summarization (16GB RAM), Gemma 4 27B for complex reasoning and document analysis (32GB RAM). Start with 12B — it covers 80% of business use cases.
Is Gemma 4 reliable enough for production n8n workflows?
Yes, for most structured tasks. Gemma 4 IT (Instruction Tuned) has strong reliability for tool calling and JSON output — the two critical requirements for n8n agent integration. For unstructured creative tasks or complex multi-step reasoning, GPT-4o still has an edge. Use Gemma 4 as your primary LLM and GPT-4o as a fallback for edge cases.
Can I run Gemma 4 on a cloud server instead of locally?
Yes. Deploy Ollama on a VPS with a GPU (Hetzner CCX33 with RTX 4000 = ~€40/month). n8n connects to it via HTTP as if it were local. This is the recommended setup for production: you get the privacy and cost benefits of local LLMs with the reliability of cloud infrastructure.
How does Gemma 4 handle French language in n8n agents?
Gemma 4 has strong French performance out of the box — one of the best among open-source models. Instruction following in French is reliable for business tasks. For specialized French legal, medical, or financial content, fine-tuning may be needed, but for standard business automation (emails, summaries, classification), Gemma 4 performs well.
Ready to implement this?
Book a free 30-min strategy call with our experts
We'll analyze your situation and propose a concrete action plan.

William Aklamavo
Web development and automation expert, passionate about technological innovation and digital entrepreneurship.


