
Gemma 4 Apache 2.0, OpenClaw Goes Paid, Claude Opus 4.6: The Week That Rebalances AI
In one week: Google opens everything with Gemma 4 (Apache 2.0), Anthropic shuts the valve on aggressive agent usage with OpenClaw, and Claude Opus 4.6 hits 1M tokens. Three signals revealing the real economics of AI in 2026.

Updated

The week of March 31 to April 6, 2026, as it happened
Wednesday, April 2, 2:00 PM GMT. Google publishes Gemma 4 on Hugging Face. Apache 2.0 license. Four sizes. Native tool use. 250,000 tokens of context. Available immediately for download on any laptop.
Friday, April 4, 6:00 PM GMT. Anthropic sends an email to its Claude Code subscribers: OpenClaw — the aggressive code execution tool integrated into Claude Code — is being removed from standard subscription plans. It moves to pay-as-you-go billing, at a rate that stings builders who were overusing it.
In this context: Claude Opus 4.6, available on Google Vertex AI since February 2026 with 1 million tokens of context, is silently changing how enterprise teams build their analysis pipelines.
Three apparently contradictory movements. In reality, they tell the same story: AI is entering a phase of economic maturity where the rules of the game are stabilizing, and where today's technical choices determine tomorrow's margins.
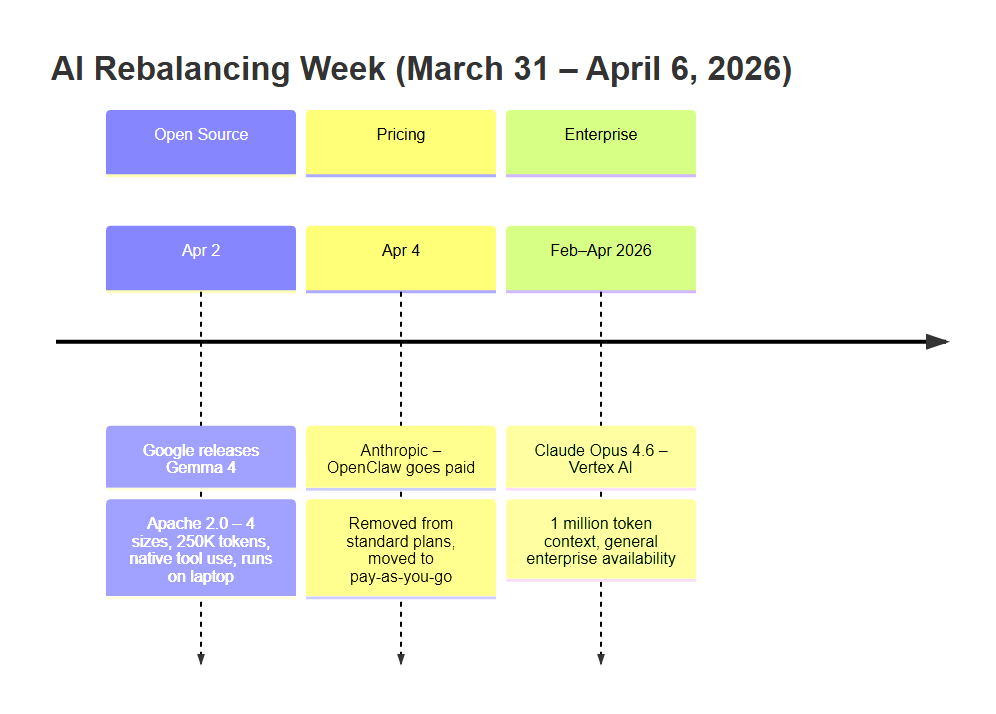 AI Rebalancing Week: Gemma 4 Apache 2.0 (Apr 2), Anthropic OpenClaw goes paid (Apr 4), Claude Opus 4.6 1M tokens
AI Rebalancing Week: Gemma 4 Apache 2.0 (Apr 2), Anthropic OpenClaw goes paid (Apr 4), Claude Opus 4.6 1M tokens
Act 1: Gemma 4 and Google's open source strategy
To understand Gemma 4, you need to understand why Google gives away something this valuable for free.
Google is not an NGO. Gemma 4 Apache 2.0 is a calculated strategic decision.
Google's calculation: If developers worldwide build their agents, apps, and workflows on a Google model, they need infrastructure to run them at scale. Cloud infrastructure = Google Cloud. Every Gemma 4 workflow that moves to production on GCP is a win for Google, even if the model itself is free.
This is exactly the Android strategy: give the OS away for free to dominate the mobile ecosystem.
What this means for you:
- Gemma 4 2B runs on a Raspberry Pi. That's not a detail — it's a statement of intent about edge computing.
- 400 million cumulative downloads for the Gemma family since 2024. Adoption is real and massive.
- The Apache 2.0 license allows commercial use without restriction. You can build a product and sell it without royalties.
We've published a complete tutorial to run Gemma 4 with Ollama and n8n — if you want to start today.
Gemma 4 in depth: the four sizes and their real-world use cases
The release of Gemma 4 isn't just "another free model." What fundamentally changes with this generation is the existence of four coherent sizes covering the complete deployment spectrum — from embedded devices to cloud production.
The 2B version is designed for edge and constrained devices. It runs on a Raspberry Pi 4, a high-end Android smartphone, or a Cloudflare Worker. Its 250,000-token context window remains highly capable for classification, short summarization, or entity extraction tasks. The inference cost is almost nothing: a few cents of electricity per hour. For lightweight local automations, this represents a complete paradigm shift.
The 9B version is the sweet spot we recommend from the outset for most professional use cases. It requires 16GB VRAM for smooth inference (an RTX 3080 Ti is sufficient), produces results comparable to GPT-3.5 Turbo on most practical task benchmarks, and supports native tool use. This is the size that makes self-hosting economically rational for a tech team of 2-10 developers.
The 27B version pushes performance toward GPT-4o Mini territory on complex tasks. It requires two GPUs (or a single A100 in the cloud) to run comfortably. At this level, you enter the territory of multi-step analysis, non-trivial code generation, and reasoning over structured problems. Infrastructure costs remain below equivalent cloud APIs starting from a few million tokens per month.
The 76B version — the largest — competes with top proprietary models on advanced reasoning benchmarks. It requires a dedicated GPU cluster for inference and is not intended for individual self-hosting. Its primary interest lies in fine-tuning: organizations with abundant proprietary data can create domain-specialized versions tailored to their vertical.
Native tool use: the differentiating feature
What makes Gemma 4 genuinely remarkable for agent builders is the native tool use integration from the 2B version onward. In previous generations, tool use was reserved for premium models or required complex prompt engineering. With Gemma 4, you can build agents that call APIs, execute web searches, or interact with databases — and do so from a model running locally without API costs.
For the n8n and Make workflows we build at BOVO Digital, based on our reading of the market, this represents a genuine turning point: for automations involving non-sensitive data, Gemma 4 9B can replace GPT-4o Mini with near-zero operational cost once the infrastructure is in place.
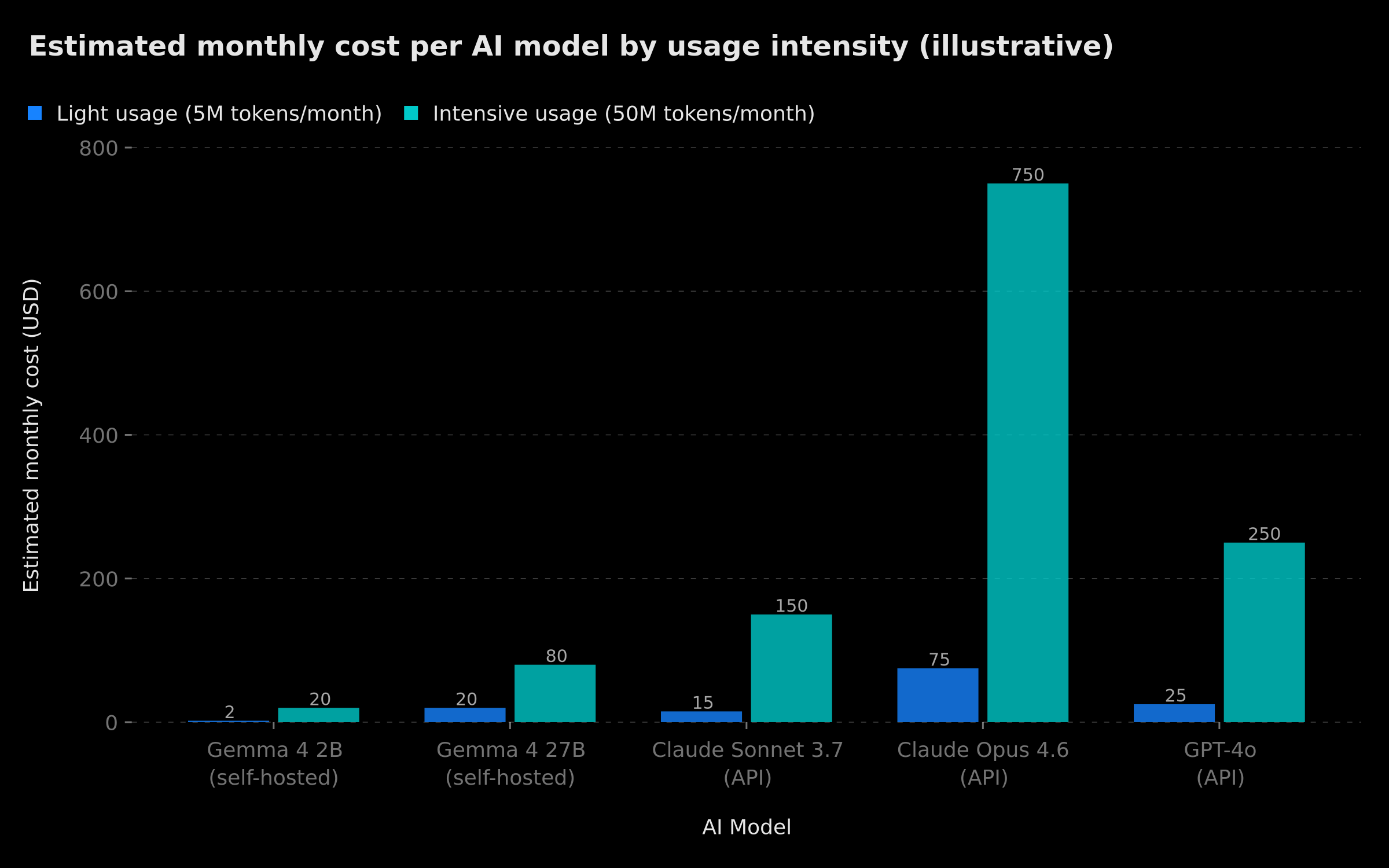 Estimated monthly cost (USD): Gemma 4 self-hosted vs Claude Sonnet, Opus 4.6, GPT-4o via API — light vs intensive usage (illustrative data)
Estimated monthly cost (USD): Gemma 4 self-hosted vs Claude Sonnet, Opus 4.6, GPT-4o via API — light vs intensive usage (illustrative data)
This illustrative chart highlights the economic rupture: at intensive usage (50M tokens/month), the cost difference between self-hosted Gemma 4 and Claude Opus 4.6 via API can reach a factor of 9 to 37. The self-hosting break-even point generally sits around 20-30M monthly tokens, depending on local infrastructure costs.
Act 2: Anthropic tightens the bolts — and it makes sense
Anthropic's decision on OpenClaw surprised many in the community. Wrongly so.
Remember that Claude Code leaked 512,000 lines of code in March 2026. In that leak, researchers discovered that Anthropic had already identified "unsustainable" usage patterns for certain agent tools. OpenClaw was among them.
The OpenClaw problem:
OpenClaw allowed Claude Code to execute complex agent loops — dozens or even hundreds of LLM calls per session, with code execution, web search, and file modification in parallel. For a human user, it's powerful. For an automated pipeline running 24/7, it's inference consumption that a $20/month subscription simply doesn't cover.
Anthropic made the economically rational choice: scalable usage pays per use, occasional usage stays on subscription.
What this reveals about AI inference economics:
LLM inference is expensive at scale. OpenAI, Anthropic, Google — all these players are subsidizing their current prices with their fundraising rounds. As automated agent pipelines multiply, this subsidy becomes unsustainable.
Anthropic's OpenClaw decision is the first in a series that will come in the next months. Fixed subscription prices for aggressive agent usage are a temporary anomaly.
Read our analysis on the hidden Anthropic features revealed by the leak for full context.
Decoding inference economics in 2026
To fully understand why Anthropic's OpenClaw decision was inevitable, you need to look honestly at the numbers behind LLM inference.
A single token costs between 0.1 and 15 microdollars depending on the model and provider, in 2026. Claude Opus 4.6 is positioned in the high tier. An aggressive OpenClaw session — with 200 LLM calls per session, long contexts, and code execution — can easily consume the equivalent of $5 to $20 in compute. Multiply that by 100 active users with automated pipelines, and you're looking at $500 to $2,000 per day in raw inference costs — not covered by a $20/month subscription.
Why providers have subsidized until now
The massive fundraising rounds of OpenAI ($40 billion in 2025-2026), Anthropic (multiple billions across successive series), and Google's investments in Gemini all enabled one thing: subsidizing the real cost of inference to acquire users. It's the same logic as Uber offering rides at a loss to dominate the taxi market.
This phase is coming to an end. Not because providers are running out of money, but because enterprise clients — not individuals — now represent the bulk of revenue. And enterprises have pipelines running 24/7. The subsidy becomes structurally impossible to sustain.
What you should anticipate
Based on our reading of the market, three evolutions are likely in the next 12 months: first, other providers will follow Anthropic and create distinct "agent tiers" separate from standard plans; second, per-use prices (input/output tokens) will stabilize or even decrease thanks to hardware efficiency gains, but agent features (tool use, computer use, long context) will remain premium; third, self-hosting with open-source models like Gemma 4 will become the default choice for margin-conscious teams.
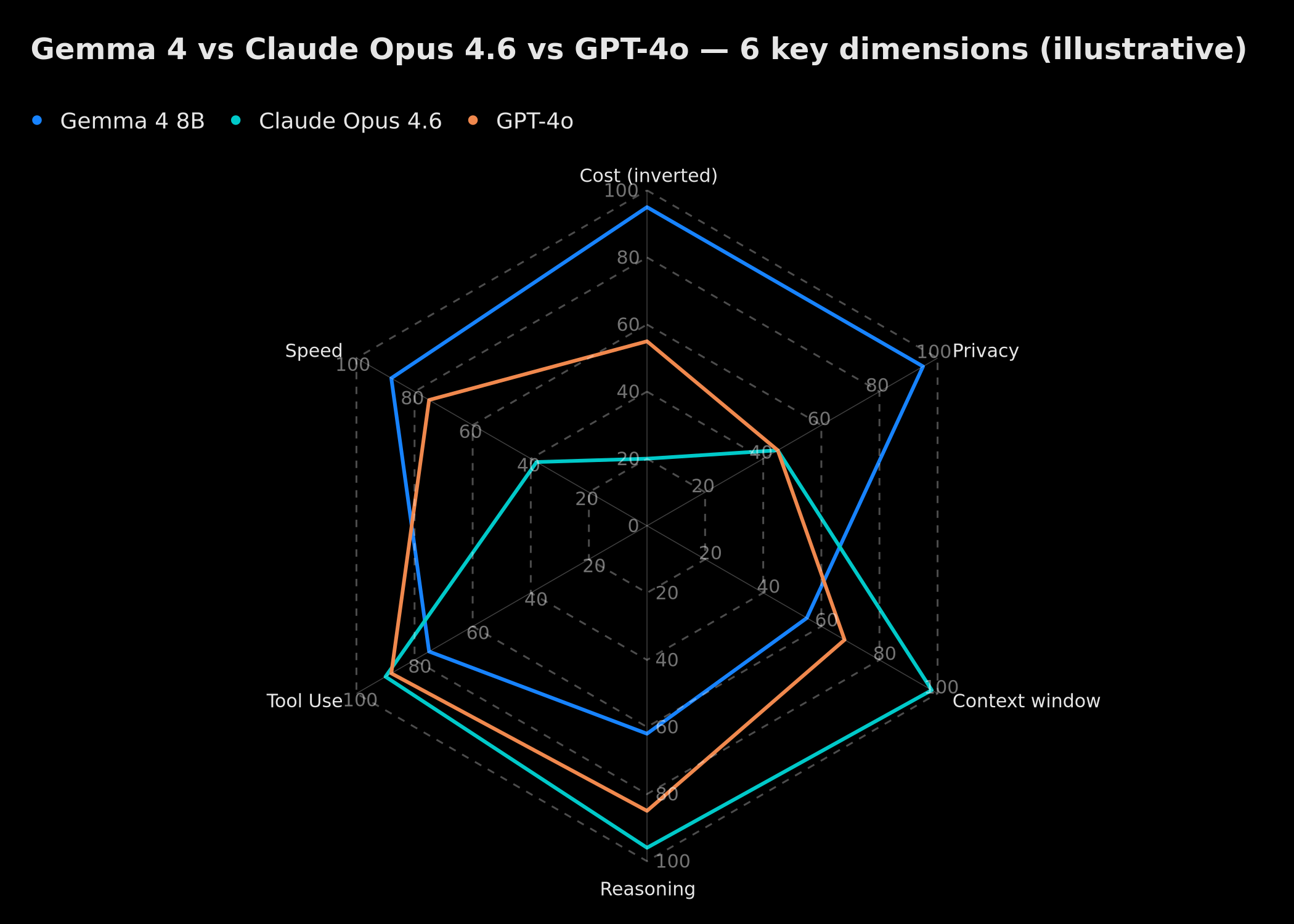 Illustrative comparative radar: cost (inverted), privacy, context window, reasoning, tool use, speed — Gemma 4 8B vs Claude Opus 4.6 vs GPT-4o
Illustrative comparative radar: cost (inverted), privacy, context window, reasoning, tool use, speed — Gemma 4 8B vs Claude Opus 4.6 vs GPT-4o
This radar illustrates the positioning of each model across six axes. No single model dominates across all dimensions: Gemma 4 excels on cost and privacy, Claude Opus 4.6 on context and reasoning, GPT-4o offers the most balanced overall profile. This reality makes a multi-model architecture not just desirable, but necessary.
Act 3: Claude Opus 4.6 and the long context era
Amid all this noise, one piece of information passed almost unnoticed: Claude Opus 4.6 is available on Google Vertex AI with 1 million tokens of context.
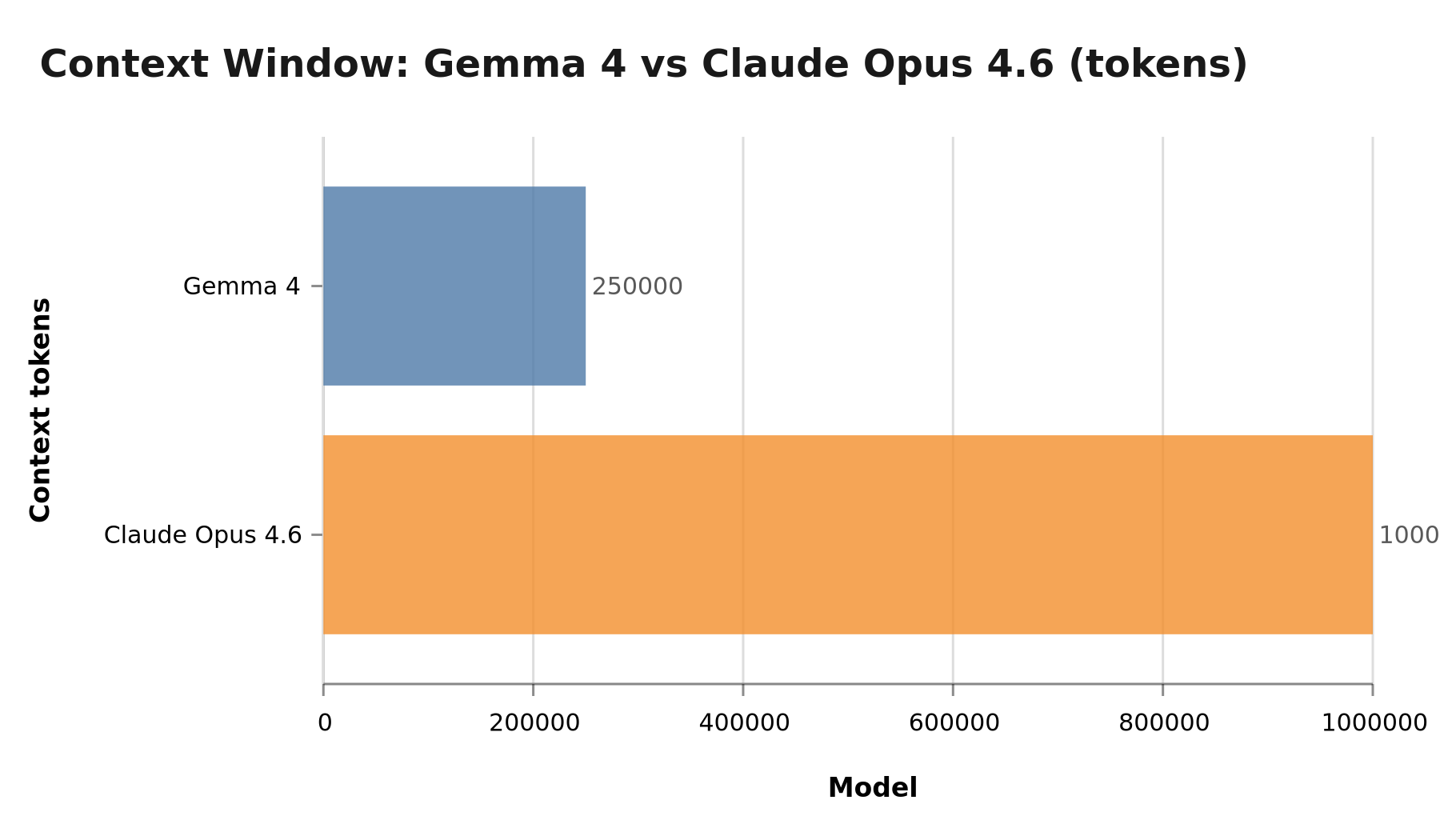 Available context window: Gemma 4 = 250,000 tokens, Claude Opus 4.6 = 1,000,000 tokens (4× more)
Available context window: Gemma 4 = 250,000 tokens, Claude Opus 4.6 = 1,000,000 tokens (4× more)
For reference: 1 million tokens is roughly 750,000 words. It's an entire average codebase. It's 500 pages of product documentation. It's 3 years of a salesperson's emails.
What this makes possible:
- Complete codebase audit in a single request: Send an entire project and ask "where are the security flaws?" without RAG, without chunking
- Contractual data analysis: Ingest hundreds of contracts and extract patterns in a single pass
- Long-duration conversational memory: Maintain months of interaction context without external memory architecture
Our February 2026 tech recap had already covered the initial announcement — Opus 4.6 available on Vertex AI marks the move to general enterprise availability.
Long context: revolution for whom?
Before integrating Claude Opus 4.6 into all your pipelines, you need an honest assessment of what long context actually solves — and what it doesn't.
When 1M tokens genuinely changes the game
Long context excels in scenarios where global coherence across the entire corpus is critical. A complete security audit of a 100,000-line codebase, for instance: a RAG architecture will chunk the code and miss vulnerabilities that span multiple distant files. Claude Opus 4.6 with 1M tokens sees everything simultaneously and can reason about interactions between distant components.
Similarly, for contractual due diligence in M&A or legal contexts — analyzing hundreds of contracts to identify contradictory clauses or hidden risks — long context enables comparative analysis in a single inference, whereas RAG requires multiple passes with risk of losing subtle semantic connections.
When RAG remains superior
Long context is not the universal solution some enthusiasts present. For evolving knowledge bases (continuously updated product documentation), RAG remains structurally superior: you can update an isolated vector without re-injecting the entire corpus. For volumes exceeding 1M tokens — a customer support datacenter with 5 years of tickets, for example — RAG is unavoidable.
There's also the cost question. A 1M input-token inference with Claude Opus 4.6 costs significantly more than a classic RAG inference of a few thousand tokens. For frequent queries against a stable corpus, RAG retains a considerable economic advantage.
Vertex AI availability: what it means
The fact that Claude Opus 4.6 is available via Google Vertex AI — not just directly via the Anthropic API — is significant. Vertex AI integrates the governance controls, enterprise SLAs, and observability tools that large organizations require. This is a strong signal from Anthropic: Claude Opus is no longer positioned as a developer tool, but as enterprise infrastructure. The pricing follows logically.
Who wins and who loses in this rebalancing?
Based on our reading of the market, the April 2026 rebalancing creates clearly identifiable winners and losers. Understanding which category you fall into is the first step to adjusting your strategy.
The clear winners
Freelancers and indie hackers come out as the big winners of this week. Gemma 4 Apache 2.0 gives them access to a commercial-grade model with zero recurring cost. A freelancer automating classification or summarization tasks for clients can now offer local, confidential, API-cost-free solutions — a value proposition that was previously impossible.
Open-source developers and academic teams benefit from an unambiguous Apache 2.0 license. Unlike Meta's "community" licenses (Llama) or Mistral AI's custom licenses, Apache 2.0 is universally recognized, allows commercial redistribution, and contains no unilateral revocation clauses.
Companies with strong confidentiality obligations — healthcare, finance, public sector — see in Gemma 4 an on-premise deployment opportunity that no cloud API can offer. Data that never leaves internal infrastructure, predictable cost, no dependency on an external provider.
The less well-positioned
Builders who constructed automated pipelines on Claude Code with heavy OpenClaw usage will feel a tariff shock. This isn't Anthropic punishing anyone — it's simply the end of a subsidy. Those with pipelines generating genuine value will adapt; those whose workflows weren't economically viable at the real inference price will need to rethink their architecture.
LLM-as-a-commodity users — those who assumed current API prices would remain stable indefinitely — will need to internalize that the AI economy in 2026 increasingly resembles the cloud economy in 2012: tier specialization, usage-differentiated pricing, and advantage to teams with a cost optimization strategy.
The ecosystem-level effect
Beyond individual winners and losers, this rebalancing has a structural effect on the AI ecosystem. The open-source tier — represented by Gemma 4 and its Apache license — creates genuine price competition for the cloud tier. This is exactly the dynamic that prevented AWS and Azure from maintaining artificially high margins on compute: the existence of a credible alternative forces incumbents to justify their premium with genuine differentiation. For users of Claude Opus 4.6, GPT-4o, or other premium models, this competitive pressure from open-source is ultimately healthy — it pushes providers to improve quality, reliability, and tooling rather than competing on raw token price.
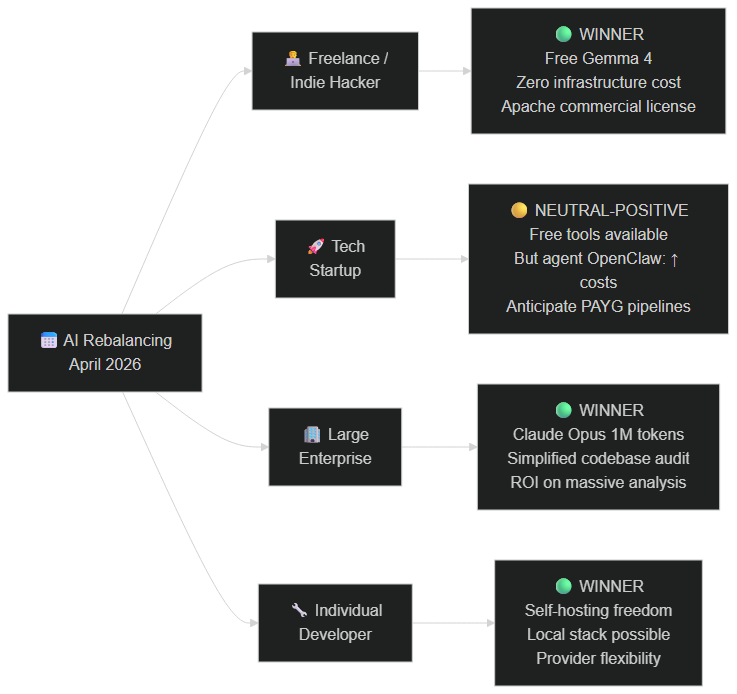 Who wins, who loses in the April 2026 AI rebalancing: freelancers and individual devs winning with Gemma 4, enterprise with Claude Opus 1M tokens, startups in neutral-positive position
Who wins, who loses in the April 2026 AI rebalancing: freelancers and individual devs winning with Gemma 4, enterprise with Claude Opus 1M tokens, startups in neutral-positive position
What does the April 2026 AI rebalancing mean for builders?
These three events draw the map of the territory for the next 18 months:
1. Local LLMs will cannibalize APIs for standard use cases. Gemma 4 Apache 2.0 running on a laptop is sufficient for 80% of common automations. Cloud providers will have to differentiate on the remaining 20%. If you're interested in the broader tension between open and closed models, our analysis of the open vs closed AI war with DeepSeek V4 and GPT-5.5 provides essential complementary context.
2. Pay-per-use will replace subscriptions for agent usage. What happened with OpenClaw will happen again. If you're building pipelines that run 24/7, anticipate that the "subscription prices" you're paying today will evolve.
3. Long context changes the architecture of AI pipelines. With 1M tokens, some complex RAG architectures become superfluous. But inference costs at these volumes remain high — you need to arbitrate. To understand the protocols standardizing agent-to-tool communication, read our article on MCP and Agent2Agent.
The 5-step strategy for navigating the rebalancing
Faced with these changes, an emotional reaction — "let's abandon everything and move to Gemma 4" or "we'll stay on Claude Opus regardless of cost" — is the worst path. The rational response is a deliberate architecture. Here are the five steps we recommend based on our operational experience.
Step 1: Audit your current provider dependency
The first question to ask is simple: if your primary LLM provider raises prices 50% tomorrow, how long does migration take? If the answer exceeds two weeks, your architecture is too tightly coupled. List every place in your code where a model name or API URL is hardcoded. That's your risk surface.
Step 2: Implement an LLM abstraction layer
LiteLLM is today's most mature solution for provider abstraction. It exposes an OpenAI-compatible interface for over 100 providers — Anthropic, Google, Mistral, Ollama — meaning your code only needs to know one interface. A provider switch becomes an environment variable change rather than a full refactor.
Step 3: Develop a local strategy with Gemma 4
For each use case in your stack, ask the question: does this flow really need to go through a cloud provider? Incoming document classification, internal summary generation, entity extraction on HR data — all of this can run locally with Gemma 4 9B. Reserve cloud APIs for tasks that genuinely require the superior reasoning level of Claude Opus or GPT-4o. Our article on the real cost of an AI chatbot in 2026 precisely quantifies these savings.
Step 4: Set up regression testing on your prompts
One of the underestimated risks of a model migration is silent regression: behavior changes subtly, results degrade slightly, but no one notices immediately. An automated test suite on your critical prompts — comparing expected outputs to actual outputs — is non-negotiable for a robust architecture.
Step 5: Monitor inference costs per use case
Without granular metrics, you're flying blind. Every LLM call in your stack must be instrumented with the provider, model, tokens consumed, and associated cost. This lets you identify disproportionately consuming use cases and make data-driven decisions rather than intuition-based ones.
For teams looking to prevent AI errors in production — not just costs, but also response reliability — our guide on avoiding AI hallucinations in enterprise completes this stack strategy.
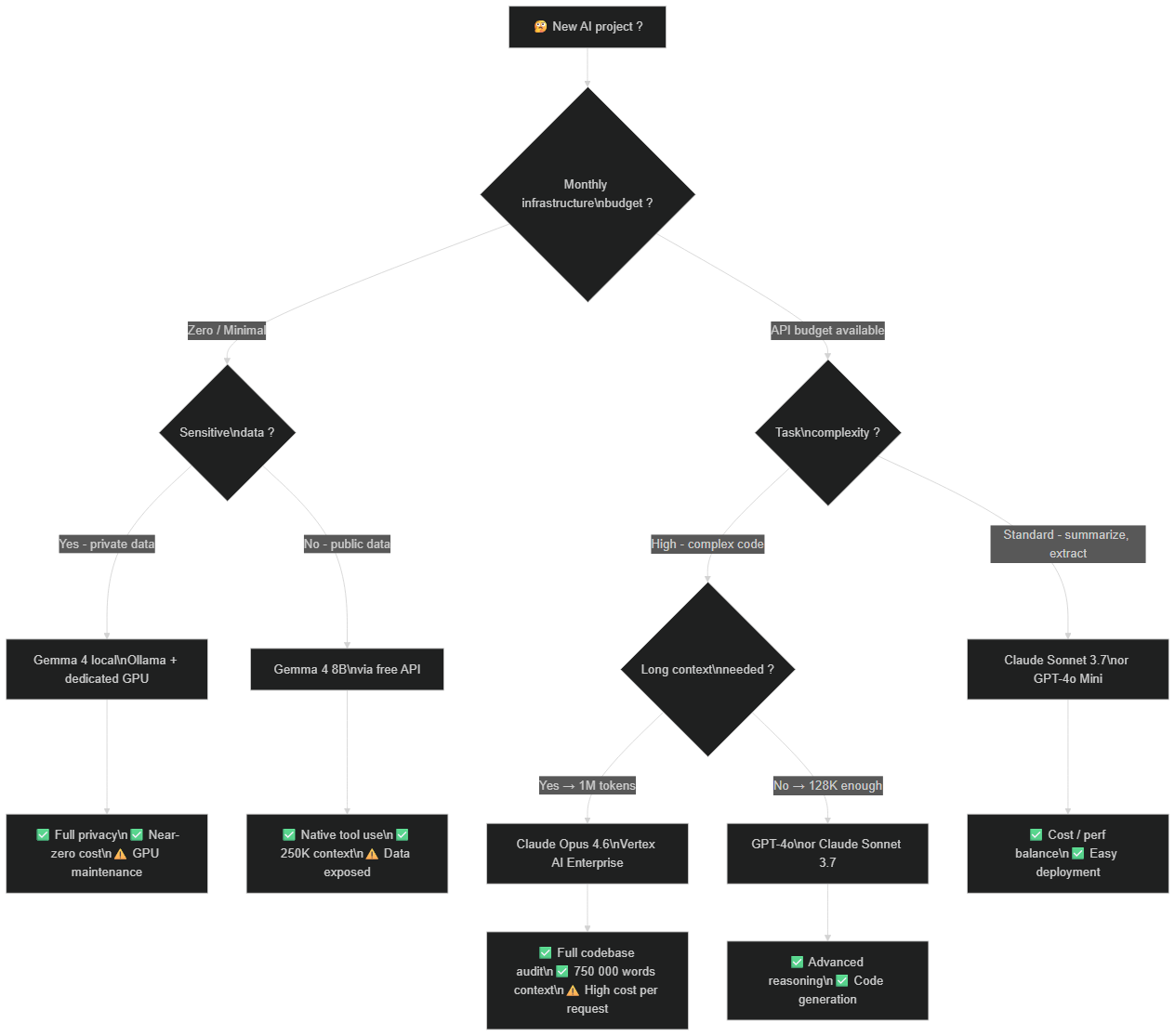 Decision flowchart: Gemma 4 local (sensitive data, zero budget), Claude Opus 4.6 (enterprise long context), Claude Sonnet / GPT-4o (standard usage), GPT-4o / Sonnet (reasoning without long context)
Decision flowchart: Gemma 4 local (sensitive data, zero budget), Claude Opus 4.6 (enterprise long context), Claude Sonnet / GPT-4o (standard usage), GPT-4o / Sonnet (reasoning without long context)
The lesson for your AI stack:
The builders who weather pricing changes are those with a flexible architecture — able to switch models (OpenAI → Anthropic → local Gemma) without rebuilding everything. A provider abstraction layer, parameterized prompts, automatic regression tests.
That's exactly what we design at BOVO Digital when we deliver production agents: an architecture that doesn't depend on a single provider, and that can dynamically arbitrate between local and cloud based on the nature of each request.
The week of March 31 to April 6, 2026 will be remembered as the moment the AI industry stopped pretending that subscription-priced inference could be unlimited. Whether you see this as a threat or an opportunity depends almost entirely on how well-prepared your technical architecture is. The builders who have spent the past months building provider-agnostic, test-covered, observability-instrumented pipelines are about to see that investment pay off. The rest have their work cut out for them — and the clock is ticking.
Is your current AI stack resilient to pricing and provider changes?
Discover our automation and AI agent integration services — or explore William Aklamavo's profile to understand the architectures we deliver.
Tags
FAQ
Why is Google launching Gemma 4 for free under Apache 2.0?
It's a strategy similar to Android: give the model away for free to push developers to adopt the Google ecosystem, particularly Google Cloud for inference at scale. Every builder running Gemma 4 in production needs infrastructure — Google Cloud is the natural target.
What is OpenClaw and why did Anthropic remove it from standard plans?
OpenClaw is an aggressive code execution tool in Claude Code, allowing complex agent loops with hundreds of LLM calls per session. Anthropic removed it from standard subscriptions because intensive automated usage isn't profitable at $20/month. It now moves to pay-as-you-go billing.
What does Claude Opus 4.6's 1 million token context change concretely?
It allows ingesting an entire codebase, 500 pages of documentation, or 3 years of emails in a single request. For some audit or analysis use cases, this replaces complex RAG architectures. Inference cost at these volumes remains high — you need to arbitrate based on use case.
How to build an AI stack resilient to provider pricing changes?
By abstracting the LLM provider from your application logic. Concretely: use an abstraction layer (LiteLLM, LangChain), don't hardcode model names, maintain regression tests on your key prompts, and have a local strategy (Ollama) for use cases that can run locally.
Will Gemma 4 replace OpenAI for n8n automations?
For 80% of common use cases (classification, summarization, information extraction, simple tool use), Gemma 4 8B is a viable and free alternative. For complex reasoning, advanced code generation, or coherence over very long contexts, GPT-4o and Claude Sonnet remain superior.
Can you host Gemma 4 27B without a dedicated GPU in production?
Technically possible via 4-bit quantization on CPU, but performance is limited (high latency, low throughput). For viable production, you need at minimum a GPU card with 16GB VRAM (RTX 3090, RTX 4080) or a cloud GPU instance (A10G, L4). The 9B version remains the best balance for self-hosting without a high-end GPU.
Which tools allow easy switching between LLM providers without rebuilding?
LiteLLM is the most mature solution: it offers a unified OpenAI-compatible interface for over 100 providers. LangChain and LlamaIndex offer higher-level abstractions. For n8n workflows, the generic AI Model node allows switching providers without modifying workflow logic. The key rule is to never hardcode a model name in your application code.
When is Claude Opus 4.6 long context preferable to a RAG architecture?
Long context is preferable when global coherence across the entire corpus matters — full security audits, multi-document comparative analysis, contractual synthesis. RAG remains superior for evolving knowledge bases, volumes exceeding 1M tokens, and cases where inference cost is a critical factor. In practice, both approaches are complementary rather than competing.
Ready to implement this?
Book a free 30-min strategy call with our experts
We'll analyze your situation and propose a concrete action plan.
William Aklamavo
Web development and automation expert, passionate about technological innovation and digital entrepreneurship.


